云端电子书创作 [官方]
前言
随着互联网技术的不断发展,Web应用程序的需求也随之不断增加。作为一名开发者,我们需要掌握各种技术来满足不同的需求。在服务器端开发领域,Node.js 已经成为了一种非常流行和强大的工具。
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行时环境,它让我们可以使用 JavaScript 语言进行服务器端编程,从而实现高性能、可扩展的网络应用和后端服务。相较于传统的服务器端开发语言,Node.js 拥有更好的性能、更高的效率和更良好的开发体验。
本书的目标是帮助读者全面了解 Node.js 的基本原理、核心模块、常用框架和实际应用,从而能够掌握 Node.js 的核心概念和技术,并运用它们构建高性能、可靠和可扩展的Web应用程序和后端服务。
本书内容介绍
下面将对本书的内容做一个整体的介绍,这样可以对书中的知识体系有一个全面的了解。
第一部分:基础知识和工具
这一部分将介绍 Node.js 的基本概念和原理,包括 Node.js 的起源和发展、安装和配置、工具的使用以及基础知识的介绍。通过学习这些内容,您将对 Node.js 有一个全面的认识,并能够开始进行基础的开发工作。
第二部分:核心模块和常用工具
这一部分主要介绍 Node.js 的核心模块和常用工具。它包括 Node.js 的核心模块、异步编程、模块和包管理等知识内容。这些核心模块和常用工具在 Node.js 开发中非常重要,它们提供了丰富的功能和工具,方便开发者进行文件操作、事件处理、工具函数调用等任务。
第三部分:网络编程和Web开发
这部分主要介绍如何使用 Node.js 构建 TCP、UDP、HTTP、Websocket 服务和进程以及网络服务和安全等,还有如何使用 Node.js 去进行一些Web开发。
第四部分:数据库和Web框架的使用
这部分介绍了如何使用 Node.js 去连接和访问数据库,并通过 Express 框架构建Web服务。这部分包含了数据库访问、ORM、Restful API、EXpress框架、中间件和模版引擎渲染等技术。通过这部分的学习,可以快速开发一个现代化、高性能的Web应用服务器。
第五部分:Node.js进阶
Node.js 的进阶部分涵盖了测试、项目产品化、日志监控、安全性、性能优化和部署扩展等主题。掌握这些知识将使开发者能够更好地组织和管理代码、保障应用程序的安全性和提升应用程序的性能以及项目的运维部署。
读者建议
本书适合那些具备一定 JavaScript 编程基础和服务器端开发经验的读者。如果您已经掌握了 JavaScript 语言、Web开发以及服务器端开发的基础知识,那么这本书将对您进一步提升技能和拓宽视野非常有帮助。如果您还没有这些基础,建议先学习相关知识,以充分理解本书的内容。
建议多动手实践,建议手动尝试运行本书中的代码,以便能够帮助您快速的掌握本书中的内容。最好能够自己动手去做一个 Node.js 的项目,这样会更大限度的加深对 Node.js 的理解。
购买须知
- 购买后可获得永久阅读本书的权限。
- 本书版权归陕西云端源想有限公司所有,只可自己阅读学习,禁止私自转载、链接、转贴、或用于任何商业用途。如有违反,将追究法律责任。
- 本书为虚拟内容,如果购买成功概不退款,敬请见谅。
- 由于篇幅限制和时间仓促,在书中难免会有疏漏和错误,如有任何问题可随时联系或者私信@我,笔者非常感谢能收到您的反馈和意见。
1-Node.js简介
Node.js 现在已经是非常火热的技术了,从本节课程开始我们将会带大家了解更多的内容。
1.1 Node.js的发展史
Node.js 的发展史可以追溯到2009年,当时Ryan Dahl发布了第一个 Node.js 版本。Node.js 最初是基于V8引擎和libuv库开发的,旨在使 JavaScript 能够在服务器端执行,实现高性能、可扩展和实时应用程序的构建。
在2010年Ryan Dahl加入了Joyent公司,随后由Ryan Dahl全职负责 Node.js。随着 Node.js 开始受到越来越多的关注和支持,也使得它成为当时最受欢迎的开源项目之一。大量的社区贡献者加入了 Node.js 的开发,提供了大量的模块和工具,帮助开发者快速构建具有各种功能的应用程序。此外,Node.js 的出现也推动了前端和后端技术的融合,使得前端开发者能够使用熟悉的 JavaScript 语言进行全栈开发。
随着 Node.js 的普及,越来越多的企业和组织开始将其用于生产环境中的应用程序。Node.js 也不断地更新和改进,增加了更多的特性和功能,同时也在性能和安全方面得到了更好的保障。目前,Node.js 已经成为全球最流行的服务器端 JavaScript 环境之一,被广泛地应用于Web开发、移动应用、物联网等领域。
1.2 什么是Node.js
Node.js 它既不是语言,也不是一个 JavaScript 框架,更不是一个浏览器端的库。Node.js 是一个能够让 JavaScript 运行在服务端的开发平台,这使得它已经能够和PHP、Python、Perl等平起平坐。
Node.js 的出现极大地拓展了 JavaScript 的应用范围,不再局限于浏览器端的脚本语言。通过 Node.js,开发人员可以构建高性能、可伸缩的网络应用程序,处理大量并发请求,以及执行I/O密集型任务。
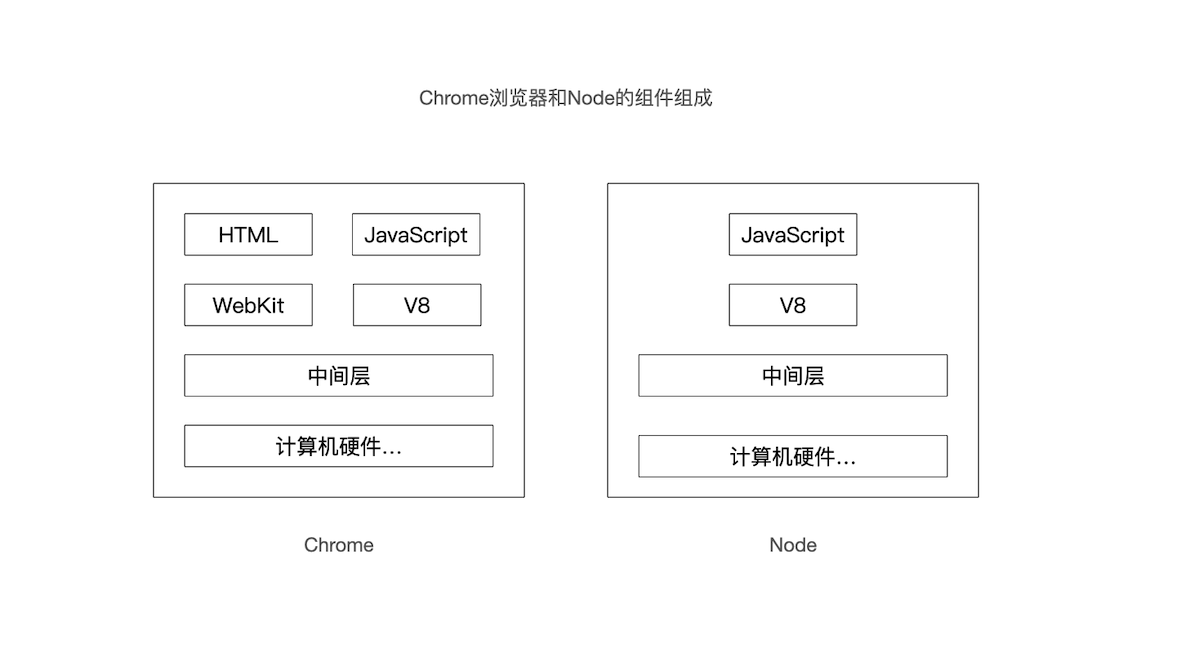
Node.js 采用了事件驱动、非阻塞I/O模型,使得它能够高效地处理并发请求。相比传统的同步I/O模型,Node.js 的异步非阻塞特性使得应用程序能够更快地响应请求,提供更好的性能和可扩展性。
除了作为服务器端的运行时环境,Node.js 还提供了丰富的模块和工具生态系统,使得开发人员能够轻松构建Web应用程序、命令行工具、API服务等各种类型的应用。通过npm(Node Package Manager),开发人员可以方便地安装、管理和共享代码库。
Node.js 在云计算、大数据处理、实时通信等领域广泛应用。许多知名公司和开源项目都使用 Node.js 作为其核心技术栈,如Netflix、LinkedIn、Uber等。
总之,Node.js 是一个强大的服务器端运行时环境,允许开发人员使用 JavaScript 语言构建高性能、可伸缩的应用程序,拓展了 JavaScript 的应用范围,并在Web开发领域取得了广泛的应用和认可。
1.3 Node.js和JavaScript
JavaScript 是一种高级、解释型的编程语言,最初被设计用于在Web浏览器中实现动态交互和用户界面。它具有类似C语言的基本语法结构,支持动态类型和面向对象编程特性。随着 Node.js 的出现,JavaScript 也成为了一种流行的服务器端编程语言。JavaScript 还可以用于全栈开发,利用同一种编程语言在前端和后端进行开发。JavaScrip t拥有丰富的生态系统和第三方库,提供了丰富的功能和API。Node.js 中的 JavaScript 指的是 Core JavaScript 或者是 ECMAScript 的一个实现,它不包含DOM、BOM或者 Client JavaScript。Node.js 使得 JavaScript 可以运行在浏览器之外的平台。它有了文件系统、模块、操作系统API、网络通信等 Core JavaScript 所没有的功能。
Node.js 是一个基于Chrome V8 JavaScript引擎的运行时环境。V8 引擎可以说是世界上最快的 JavaScript 引擎,它的执行速度已经接近本地代码的执行速度。Node.js 实现了前后端编程环境的统一,可以大大降低前端转后端所付出的代价。
1.4 Node.js的特点
Node.js 作为 JavaScript的运行平台,主要用于服务器端编程。下面是 Node.js 的几个主要特点:
-
事件驱动和非阻塞I/O模型:Node.js 采用事件驱动的模型,所有的I/O操作都是异步的,不会阻塞程序的执行。这使得 Node.js 非常适合高并发、I/O密集型的应用场景。
-
单线程和多进程:Node.js 使用单线程模型来实现高并发。在单线程模型下,所有的I/O操作都是异步的,因此不会阻塞程序的执行。同时,Node.js 也支持多进程模型,通过子进程方式实现多进程,可以充分利用多核CPU的性能。
-
高效的内存管理:Node.js 使用了V8引擎来解析和执行 JavaScript 代码,V8引擎具有高效的内存管理机制,可以自动回收不再使用的内存。同时,Node.js 也提供了一些内存管理工具,如 Heapdump 和 profiler 等,方便开发人员进行内存优化和调试。
-
模块化:Node.js 使用 CommonJS 规范来实现模块化,所有的代码都是模块化的。开发人员可以使用
require函数来引入其他模块的代码,使用module.exports或exports来导出自己的代码。这样可以有效地组织、共享和重用代码。 -
社区生态的丰富性:Node.js 拥有一个庞大的社区,有许多优秀的第三方模块和工具可供使用,如Express、Socket.io、Mongoose等。这些模块和工具可以极大地提高开发效率,加速应用程序的开发和部署。
-
跨平台性:Node.js 可以在各种操作系统下运行,如Windows、Linux、MacOS等。这使得 Node.js 非常适合开发跨平台的应用程序。
1.5 Node.js能做什么
Node.js 作为一种服务器端 JavaScript 运行时环境 你可以做以下几个方面的事情:
-
构建Web应用程序:Node.js 提供了HTTP模块,可以轻松地创建Web服务器。同时,Node.js 还有丰富的第三方模块和框架,如Express、Koa等,可以帮助开发人员快速构建高质量的Web应用程序。
-
实现API服务:Node.js 可以用来实现RESTful API服务,处理和响应HTTP请求。同时,Node.js 还可以与各种数据库进行交互,如MySQL、MongoDB等,实现数据的读写操作。
-
开发命令行工具:Node.js 可以用来开发命令行工具,如Webpack、Gulp等。这些工具可以自动化执行一些重复性的任务,提高开发效率。
-
实现网络编程:Node.js 可以用来实现网络编程,如构建TCP、UDP服务器和客户端等。同时,Node.js 还可以使用WebSocket协议,实现实时通信功能。
-
处理文件系统:Node.js 可以用来处理文件系统,如读写文件、创建和删除目录等。同时,Node.js 还可以监视文件和目录的变化,支持文件流的方式进行读写操作。
-
带图形的本地应用程序:可以使用 Node.js 与其他工具和框架结合(例如:Electron、Qt等),来创建带有图形界面的本地应用程序。
Node.js 具有丰富的应用场景和功能,可以用于各种类型的应用程序开发。通过丰富的第三方模块和工具,开发人员可以轻松地构建高质量的应用程序。
1.6 有哪些公司在用
Node.js 在业界得到了广泛的应用和采用,许多知名公司都在使用 Node.js 来构建他们的应用程序。以下是一些使用 Node.js 的知名公司:
-
Netflix:Netflix是全球领先的在线流媒体服务提供商,在其服务器端应用程序中广泛使用 Node.js 。Netflix利用 Node.js 的高并发和非阻塞I/O模型来处理大量的并发请求,提供快速且稳定的流媒体服务。
-
Uber:Uber是一家全球知名的打车服务公司,他们的后端系统中也使用了 Node.js。Uber的实时应用程序需要处理大量的并发请求和实时数据交换,Node.js 的事件驱动和非阻塞I/O模型非常适合这种场景。
-
LinkedIn:LinkedIn是全球最大的职业社交网络平台,他们的服务端应用程序中也采用了 Node.js。LinkedIn使用 Node.js 来构建实时通信、数据推送等功能,通过 Node.js 的高性能和轻量级特性,实现了快速响应和高并发的需求。
-
PayPal:PayPal是一家全球领先的在线支付解决方案提供商,他们的一些服务和工具中也使用了Node.js。PayPal利用 Node.js 构建了一些内部工具和API服务,以提高开发效率和系统性能。
-
Walmart:Walmart是全球最大的零售公司之一,他们的一些后端系统中也采用了 Node.js。Walmart利用 Node.js 构建了一些实时数据分析和监控系统,通过 Node.js 的高效性能和灵活性,实现了对商业数据的及时处理和分析。
除了以上这些公司,还有许多其他知名公司也在使用 Node.js,如Yahoo、NASA、IBM等。Node.js 的高性能、丰富的生态系统和广泛的社区支持使得它成为许多公司选择的首选技术之一。
总结
Node.js 以其高性能、可扩展性和丰富的生态系统成为开发者喜爱的选择,为构建现代化的网络应用程序提供了强大的支持。Node.js 无论是构建Web应用、处理实时数据还是开发命令行工具等等,都是一个强大的选择。
2-Node.js的安装和配置
从2009年诞生至今,Node.js 一直处于快速发展的阶段,很多方法和功能都会被新的技术所取代,因此我们需要注意的是对于 Node.js 的版本没必要追求最新。由于 Node 的安装方式有很多,我们主要介绍从官网的途径去获取并安装。下面我们将介绍如何在Windows、Mac和Linux系统上安装Node环境。
2.1 安装前的准备
在 官网 下载安装,推荐使用 LTS 版本(长期支持版本)进行安装。
2.1.1 下载并安装
点击官网的 Other Downloads 然后根据自己的操作系统选择对应的安装包下载进行安装。
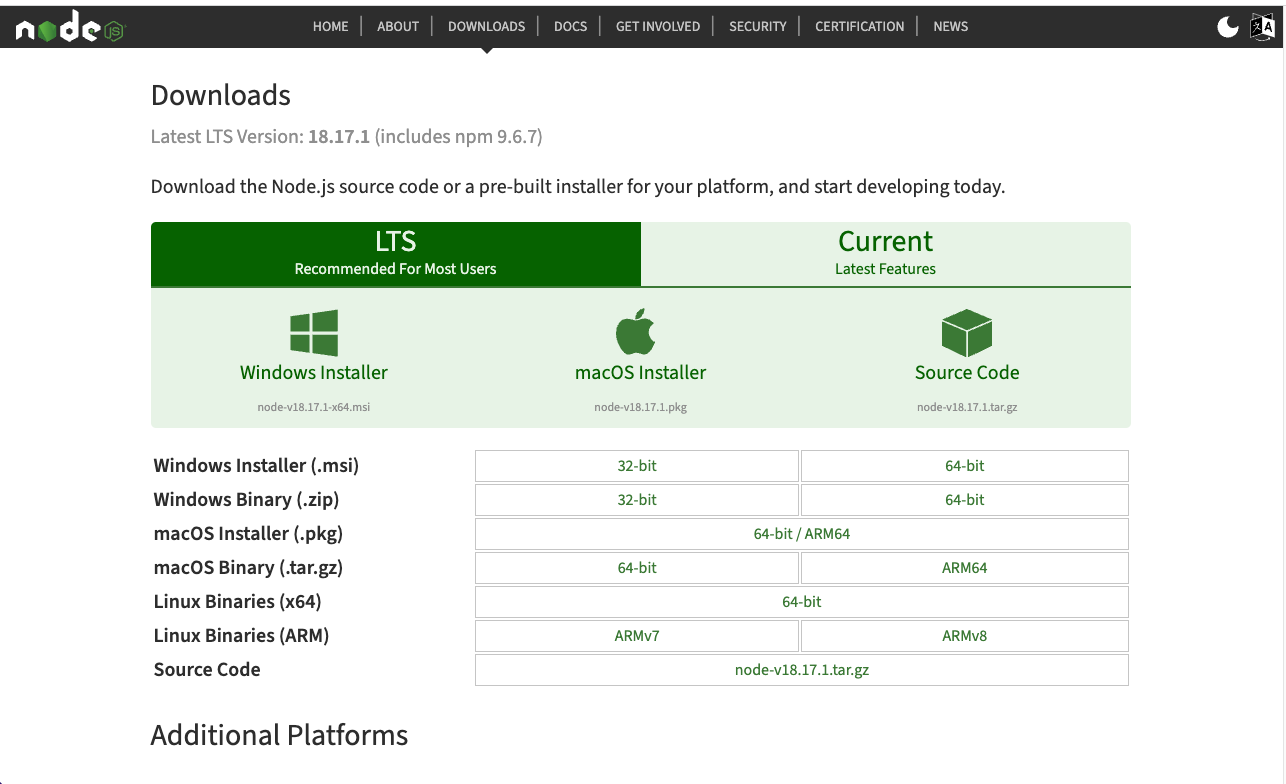
注意事项:
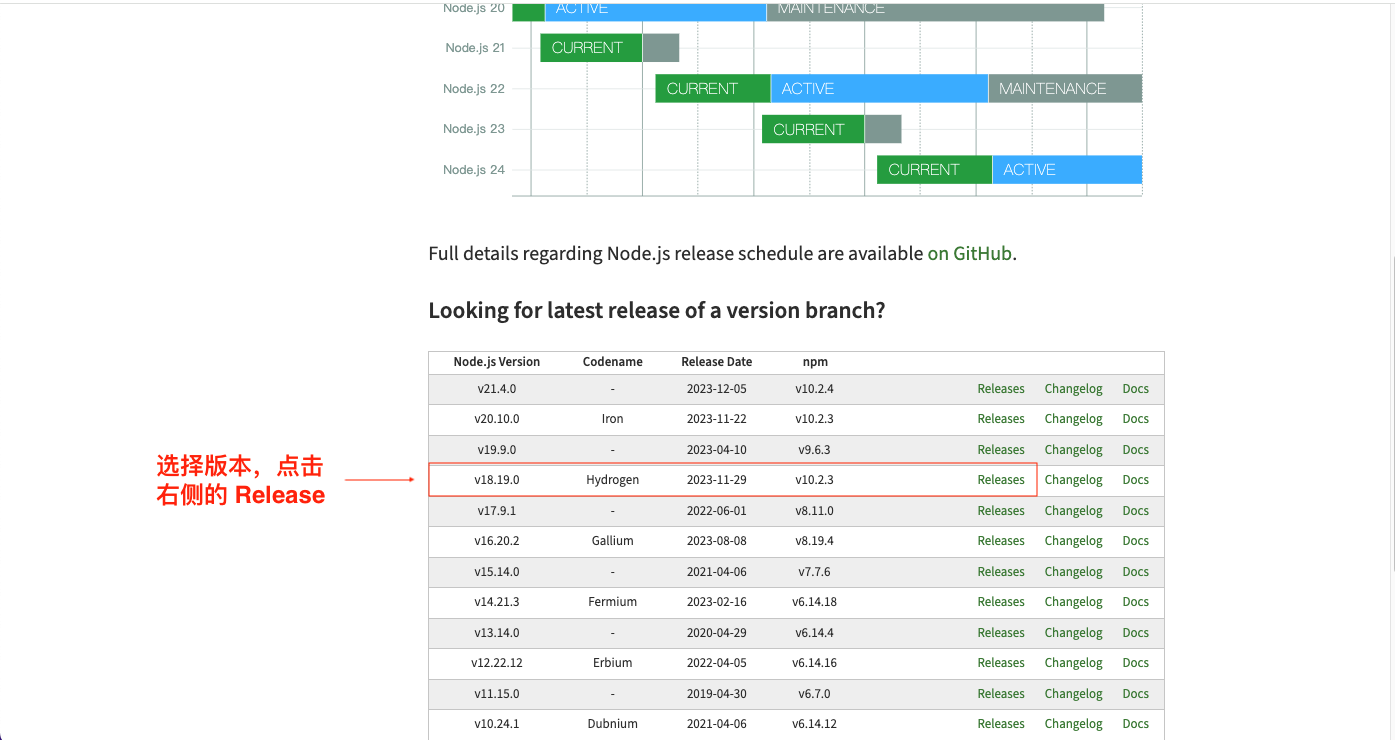
1. 点击官网下载页面上的 Previous Releases 栏可以选择往期版本进行安装。
2. 需要注意自己的操作系统,32位操作系统下载32位安装版,64位操作系统下载64位安装包,不能选错。
3. 注意有些计算机的处理器是arm架构(如:Mac M1、M2),需要下载ARM64的安装包。

2.1.2 Windows上安装Node.js
安装
- 找到并点击下载好的安装包,点击
Next开始进行安装。

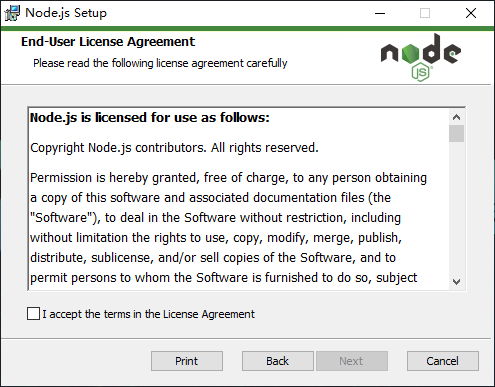
- 勾选
接受,继续安装。
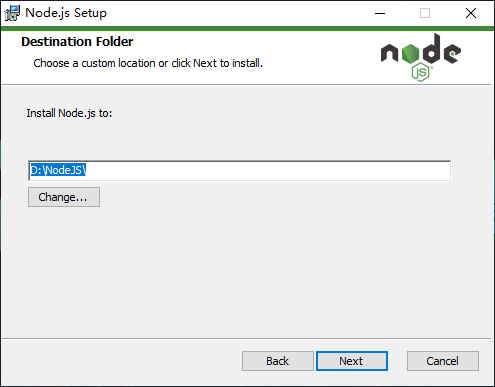
-
根据自己的喜好,可以将 Node.js 安装到你选择的磁盘目录下,点击
Next。点击
change可以选择 Node.js 安装到你选择的磁盘目录。

- 保持默认,点击
Next。
- 继续点击
Next。

- 点击
install开始安装,最后等待进度条结束完成安装。
- 在 Node.js 的安装目录下创建
node_global和node_cache文件夹。
- 管理员身份打开cmd,运行下面命令:
npm config set prefix "D:\NodeJS\node_global"
npm config set prefix "D:\NodeJS\node_cache"
环境变量配置
-
Windows操作系统下,通过
系统>高级系统设置>环境变量来进行环境变量设置。
图13 环境变量 (1)
图14 环境变量 (2)
图15 环境变量 (3)
-
在系统变量
path>编辑里添加D:\NodeJS。
图16 环境变量 (4)

图17 环境变量 (5)
-
在系统变量中新建变量名
NODE_PATH,变量值D:\NodeJS\node\_global\node_modules。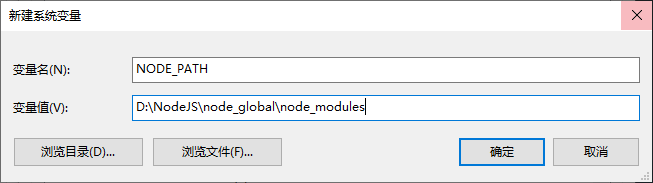
图18 环境变量 (6)
然后在系统变量
path>编辑里添加%NODE_PATH%。图19 环境变量 (图7)
图20 环境变量 (8)
-
在用户变量
path>编辑,新增D:\NodeJS\node_global。
图21 环境变量 (9)
2.1.3 Mac上安装Node.js
-
点击下载好的安装包,点击
继续开始进行安装。
图22 Mac上安装Node.js (1)
-
在软件许可协议阶段点击
继续,然后点击同意。
图23 Mac上安装Node.js (2)
-
根据自己喜好,点击
更改安装位置,可以修改Node.js的安装磁盘位置,完成后点击继续等待进度条结束完成安装。
图24 Mac上安装Node.js (3)
图25 Mac上安装Node.js (4)
2.1.4 Linux上安装Node.js
安装
进入到 /usr/local 下载压缩包并解压。
# 进入到/usr/lcoal目录下
cd /usr/lcoal
# 创建app文件夹
mkdir app
# 使用wget工具下载Node.js
wget https://nodejs.org/download/release/v18.19.0/node-v18.19.0-linux-x64.tar.gz
# 解压
tar -zxvf node-v18.19.0-linux-x64.tar.gz -C /usr/local/app
环境变量配置
将node-v18.19.0-linux-x64下的 bin 目录加入环境变量中,修改 /etc/profile 或者 $HOME/.profile 文件。
在 profile 文件末尾追加配置内容。
vim /etc/profile
或
vim $HOME/.profile
英文输入法状态下输入 i 进入编辑状态,并末尾追加下面的内容:
export NODE_HOME=/usr/local/app/node-v18.19.0-linux-x64
export PATH=$PATH:$NODE_HOME/bin
最后输入 :wq 退出编辑状态并保存。
2.1.5 验证是否安装成功
-
查看node版本:
node -v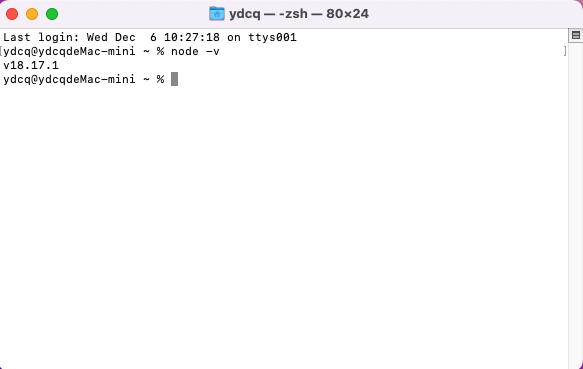
图26 验证 (1)
-
查看npm版本:
npm -v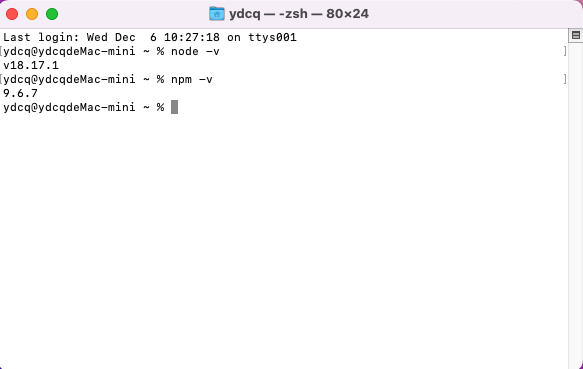
图27 验证 (2)
如果嫌安装配置环境麻烦,我们还可以使用远端源想的在线编程工具,直接创建项目编写并运行代码,后面我们会介绍。
2.1.6 设置镜像地址
在 cmd或终端 中输入以下命令:
# 更换npm源为淘宝镜像
npm config set registry https://registry.npm.taobao.org
# 设置 npm官方镜像仓库 (如果你想使用官方镜像地址就执行这条命令)
npm config set registry https://registry.npmjs.org
查看是否配置成功,在cmd中输入 npm config get registry 是否能成功输出淘宝的镜像地址。
# 查看npm源地址
npm config get registry
注意: 如果遇到 npm ERR: request to https://registry.npm.taobao.org failed, reason: certificate has expired错误,这是因为证书已经过期了;淘宝镜像站已经切换成新的域名。需要将 https://registry.npm.taobao.org 换成 https://registry.npmmirror.com
2.2 多版本管理器
Node.js 更新速度非常快,有可能旧版本的方法和API会被新版本所替代,这就会造成代码不能正常的向下兼容。如果你想尝试新版本带来的新特性,又想保持目前稳定的开发环境。这时候就需要多版本管理器了。Node.js 的多版本管理器主要包括nvm、nvm-windows和n。它们可以帮助开发者在同一台机器上同时安装和切换不同版本的 Node.js。
-
nvm(Node Version Manager):nvm是一个跨平台的 Node.js 版本管理工具,适用于 macOS 和 Linux 系统。它允许用户在同一台机器上安装和管理多个 Node.js 版本,并且可以轻松切换使用不同的版本。nvm 还支持在不同的项目中使用不同的 Node.js 版本,这对于处理依赖关系和保持项目的一致性非常有帮助。
-
nvm-windows:nvm-windows 是为 Windows 操作系统设计的 Node.js 版本管理工具。类似于 nvm,在 Windows 上使用 nvm-windows 可以方便地安装和切换不同版本的 Node.js。nvm-windows 提供了一个交互式的命令行界面,用户可以从命令行界面中选择要安装和使用的 Node.js 版本。
-
n:n 是另一个简单实用的 Node.js 版本管理工具,适用于macOS和Linux系统。与 nvm 不同,n 不提供交互式的命令行界面,而是通过命令行命令来安装和切换 Node.js 版本。n 还提供了一些其他有用的功能,例如列出可用版本、安装指定版本、切换默认版本等。
如果已经正确安装了 Node.js 环境,那么就可以直接使用 npm install -g n 命令来管理 Node.js,安装好 n,可以使用 n --help查看它的帮助命令。
注意:
1. n不支持Windows系统,Windows系统下需要使用 nvm-windows。
2. n只能管理通过n安装的 Node.js。
2. 多版本管理器根据需要安装,Node.js 学习阶段不是必须的。
总结
这章节我们介绍了 Node.js 环境的安装以及环境变量配置等内容,请确保 Node.js 的开发环境能够正确安装,这将为我们后面的学习开发等知识内容做好良好的铺垫。
3-使用Node进行编程
通过前面的介绍和学习,相信你已经成功安装了 Node.js,接下来就让我们开始正式学习如何在 Node.js 上编程并运行代码。
3.1 Node.js交互式环境REPL
REPL (Read Eval Print Loop),它是 Node.js 提供的交互式环境,允许用户直接在命令行中输入 JavaScript 代码并立即得到执行结果。这个功能类似于 Python 的交互式环境或者 Ruby 的 IRB。
通过在命令行中输入 node 命令,即可进入 Node.js 的 REPL 环境。在 REPL 环境中,用户可以输入任意的 JavaScript 代码,并且 Node.js 会立即对这些代码进行解析、求值和输出结果。例如,用户可以输入简单的数学运算、定义变量、调用函数等操作,并且可以立即得到执行结果。这使得开发者可以快速测试和验证一些想法,而不必编写完整的程序。
除了基本的 JavaScript 语法外,Node.js 的 REPL 还提供了一些额外的功能,例如可以使用下划线 _ 变量来引用最近一次表达式的结果,可以使用.help命令来获取帮助信息,以及可以使用 .exit 或者按下 Ctrl+C 两次来退出 REPL 环境。
Node.js 的 REPL 是一个非常有用的工具,可以帮助开发者快速验证和调试 JavaScript 代码,以及学习和探索新的语言特性和API。它为开发者提供了一个方便的交互式环境,可以在其中进行实时的代码实验和交互式学习。
3.1.1 REPL的基础命令
当你进入 Node.js 的 REPL 环境后,可以使用以下基础命令来进行交互:
-
.help:显示 REPL 环境的帮助信息,其中包含了可用命令的列表和说明。
ydcq@ydcqdeMac-mini ~ % node Welcome to Node.js v18.17.1. Type ".help" for more information. > .help .break Sometimes you get stuck, this gets you out .clear Alias for .break .editor Enter editor mode .exit Exit the REPL .help Print this help message .load Load JS from a file into the REPL session .save Save all evaluated commands in this REPL session to a file Press Ctrl+C to abort current expression, Ctrl+D to exit the REPL > -
.break(或按下两次
Ctrl+C):如果你输入了一个多行代码并且想要取消输入,可以使用.break命令。> a = [1, 2, 3]; [ 1, 2, 3 ] > a.forEach(function(x) { ... console.log(x); ... } ... .break >注意:如果是一段代码没有写分号
;或者是一段表达式没有写完就会发生多行分次输入,直到代码或者表达式写完。 -
.clear:清除 REPL 环境中的所有内容,将其重置为初始状态。
注意:通过
.help我们可以看到.clear的解释是Alias for .break; 它是.break的别名;意思就是它的作用和.break命令是一样的。 -
.save [filename]:将当前 REPL 会话中输入的所有代码保存到指定的文件中。
> a [ 1, 2, 3 ] > msg = "hello"; > .save /Users/ydcq/Desktop/web/node_demo/demo.js Session saved to: /Users/ydcq/Desktop/web/node_demo/demo.js >如果保存路径正确,我们就可以看到已经保存的文件了。
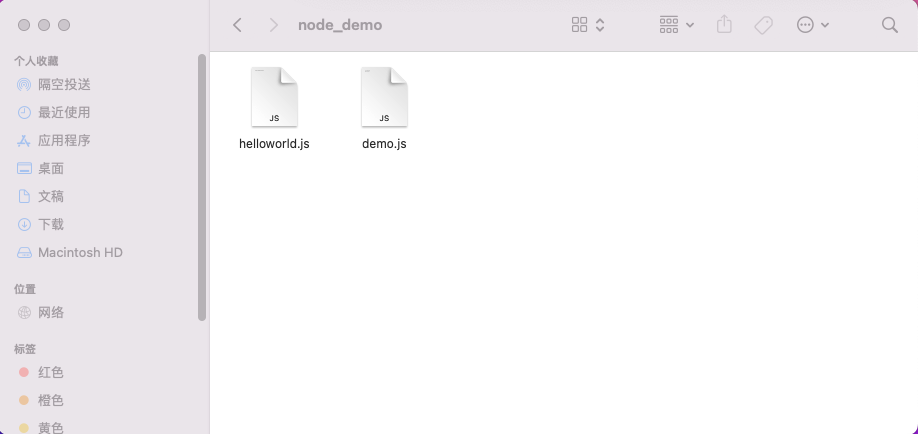
图1 .save命令
-
.load [filename]:从指定的文件中加载 JavaScript 代码并执行。
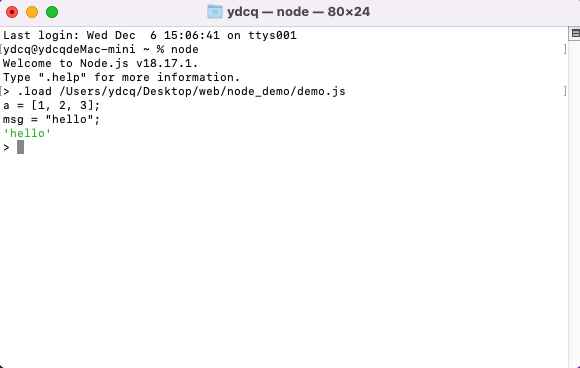
图2 .load命令
-
.exit(或按下两次Ctrl + C):退出 Node.js 的 REPL 环境。
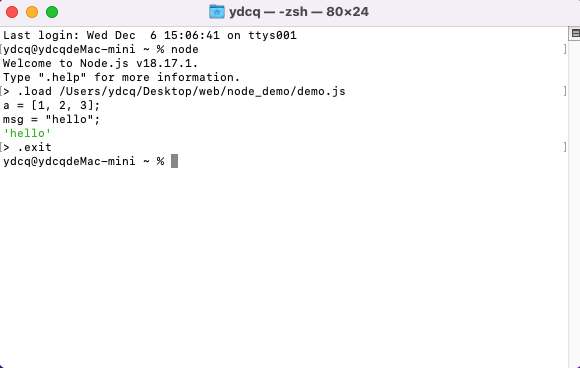
图3 .exit命令
-
.editor:进入编辑器模式,以便你可以多行输入和编辑代码。按下
Ctrl+D或者输入.exit退出编辑器模式并执行代码。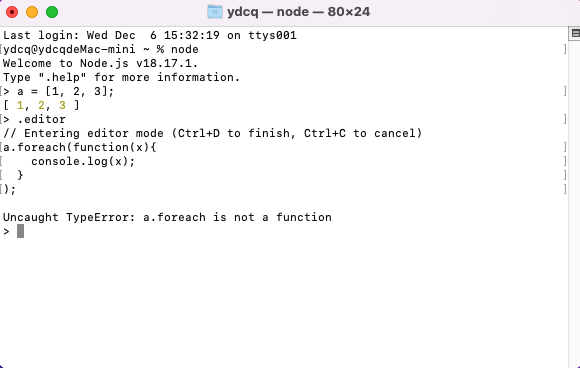
图4 .editor命令
-
tab :当在空白行按下时,显示全局和本地作用域内的变量。当在输入时按下,显示相关的自动补全选项。
图5 tab补全
3.1.2 REPL中使用下划线 _
在 Node.js 的 REPL 环境中,下划线符号 _ 代表最近一次表达式的结果。当你在 REPL 中输入一个表达式并按下回车键后,Node.js 会显示表达式的结果,并将该结果存储到下划线 _ 变量中。你可以在随后的表达式中使用下划线 _ 变量来引用先前的结果,而不必重新计算或重新输入相同的代码。
例如,假设你在 REPL 中输入以下两个表达式:
> 2 + 2
4
此时,Node.js 会将表达式 2 + 2 的结果存储到下划线 _ 变量中,并将结果打印到屏幕上。现在,如果你想使用先前的结果来执行另一个操作,例如乘以2,你可以输入以下表达式:
> _ * 2
8
这将使用下划线 _ 变量引用先前的结果,并将其乘以2。这样,你可以在 REPL 环境中轻松地构建和测试复杂的表达式,同时避免重复输入相同的代码或手动存储中间结果。
注意:下划线 `_` 变量只存储最近一个表达式的结果。如果你在 REPL 中输入多个表达式,每个表达式的结果都会覆盖下划线 `_` 变量中的内容。因此,如果你需要在后续操作中引用多个结果,最好将它们存储在具有描述性名称的变量中。
这些基础命令可以帮助你控制和管理 Node.js 的 REPL 环境。你可以使用 .help 命令获取更多详细的信息,并根据需要进行实际操作。此外,你还可以使用常规的 JavaScript 语法和命令,如变量赋值、函数调用等,以及访问全局对象和已加载的模块。REPL 环境允许你以交互方式编写和测试代码,非常适合快速验证想法和进行实验。
3.2 加载Node.js脚本
在 Node.js 环境中,可以通过 node 文件路径 加载和执行 JavaScript 脚本文件。例如我们创建一个 node_demo 文件夹,进入该文件夹,再创建一个 helloworld.js 文件,用文本编辑器打开,并输入 console.log("Hello World!"); 这段代码保存并退出。
在 终端/cmd 中输入 node helloworld.js 并按回车键,终端/cmd 将会输出 Hello World!。
ydcq@ydcqdeMac-mini node_demo % node helloworld.js
Hello Word!
3.3 VSCode
Visual Studio Code(简称 VSCode)是一个免费开源的跨平台代码编辑器,由 Microsoft 开发和维护。它提供了丰富的功能和扩展性,适用于各种编程语言和开发场景。VSCode 还内置了智能代码补全、代码导航和代码重构等功能,可以大大提高开发效率。
3.3.1 VSCode安装
-
VSCode 官网,根据自己的操作系统下载对应的安装包。

图6 VSCode官网
-
双击下载好的安装包并勾选同意按钮,点击下一步进行安装。
图7 VSCode安装
-
根据自己的喜好设置安装到磁盘的位置。

图8 VSCode选择磁盘位置
-
勾选对应的选项点击下一步继续安装等待安装。

图9 VSCode安装继续
-
最后点击完成。
图10 VSCode完成安装
安装完成后的界面。
3.3.2 设置简体中文
我们发现刚才安装的 VSCode 还是英文的,接下来我们就要设置它的中文界面。
点击下面的图标,然后输入 chinese,选择第一个,然后点击 install 进行安装。

完成后根据提示重启 VSCode 就能显示中文了,接下来就可以在VSCode里面进行编程了。

3.4 在线编程工具
我们也可以使用云端源想在线编程工具去运行 Node.js 的项目,在线编程工具已经集成了 Node.js 的环境,可以省去很多安装和配置的步骤,真正做到了开箱即用。下面就让我们来看一看具体的操作吧。
-
进入官网首页https://www.ydcode.cn/,点击开始进入
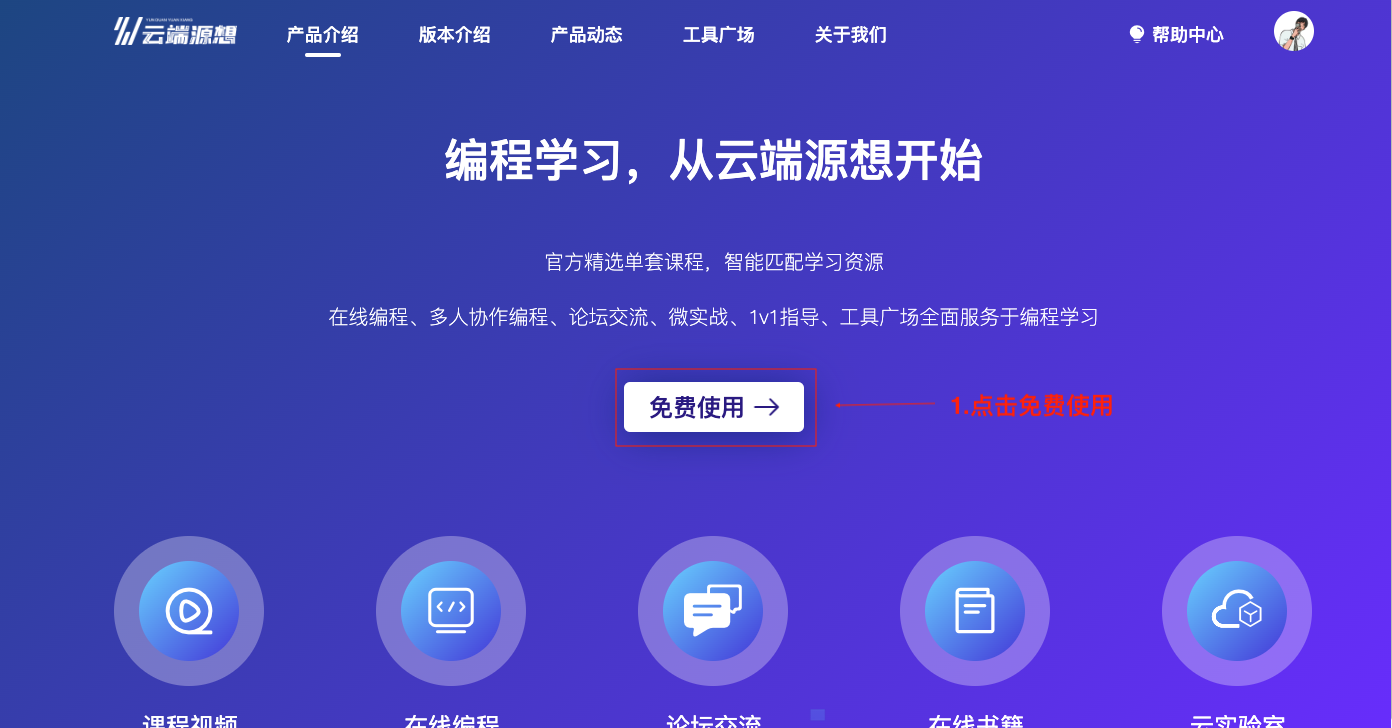
图14 云端源想官网首页
-
在课程首页点击在线编程
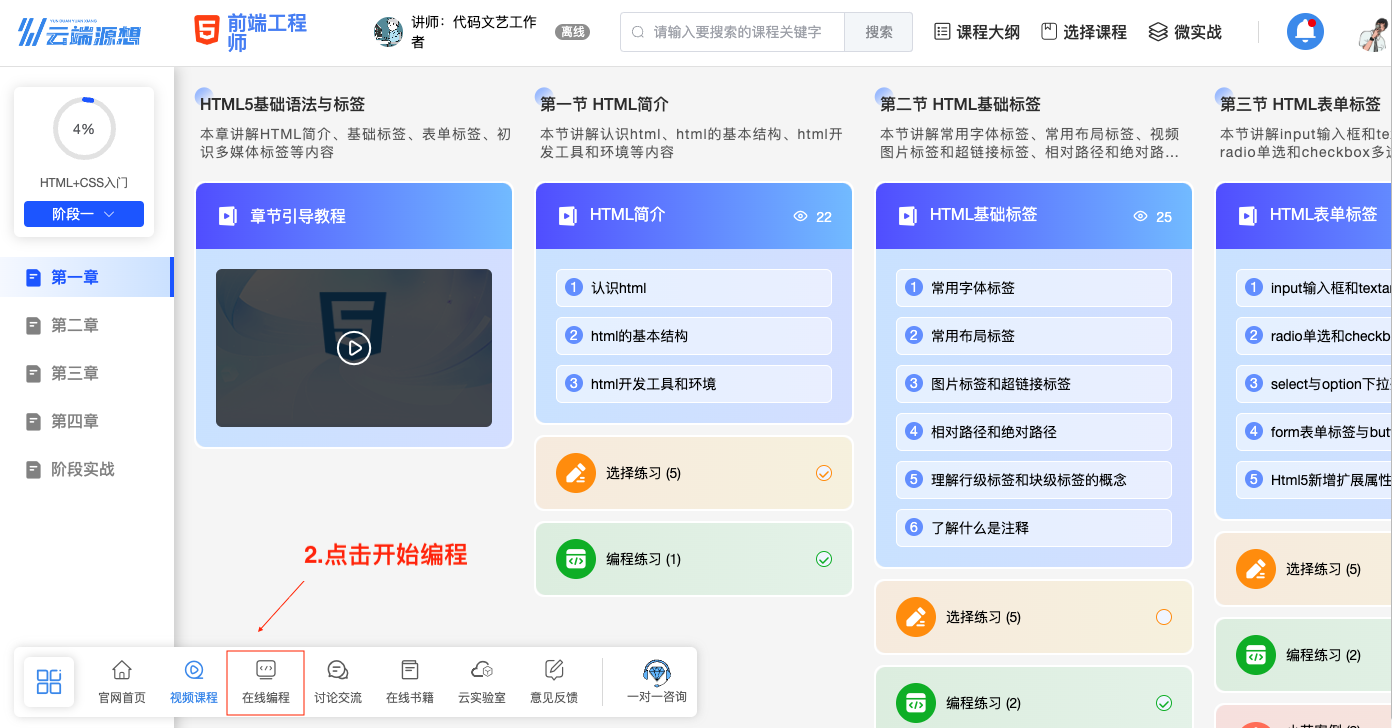
图15 点击在线编程
-
开始创建新的项目
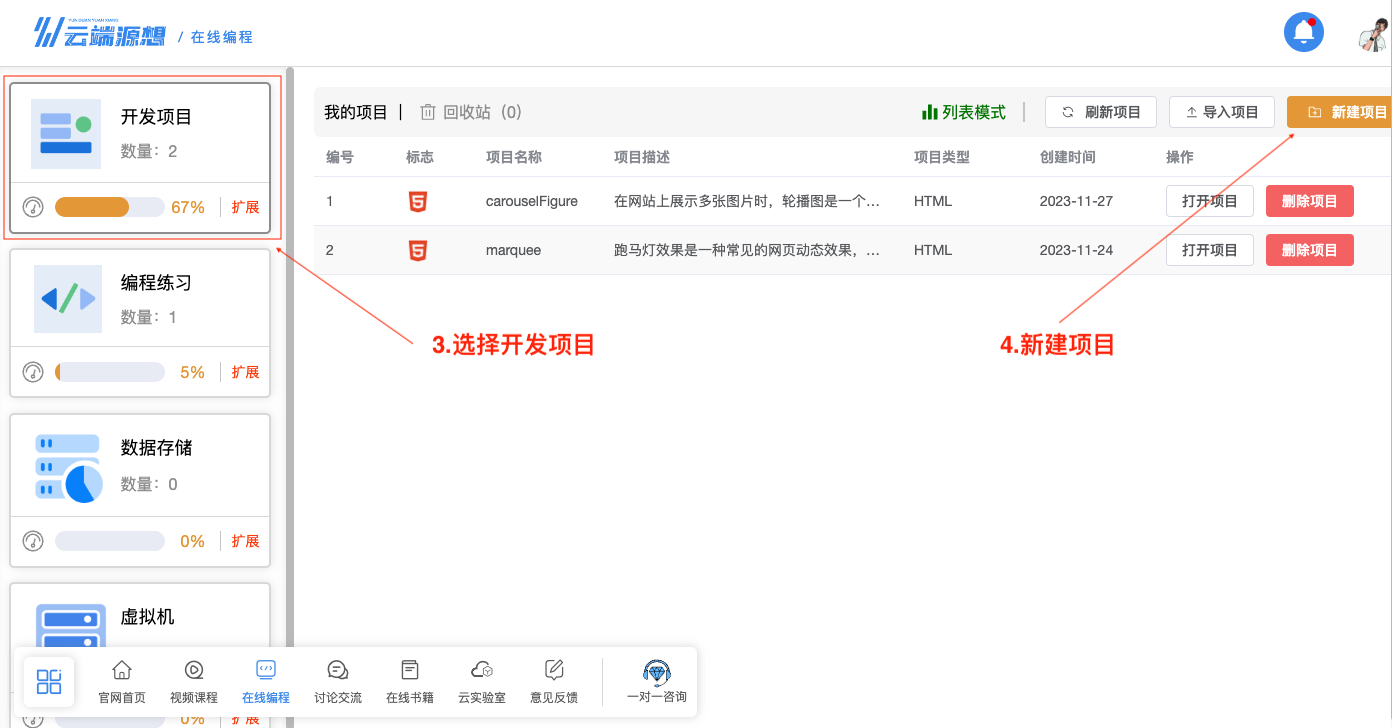
图16 新建项目
-
完成项目创建,我们只使用 Node.js 环境,选择Vue项目足够我们使用了。
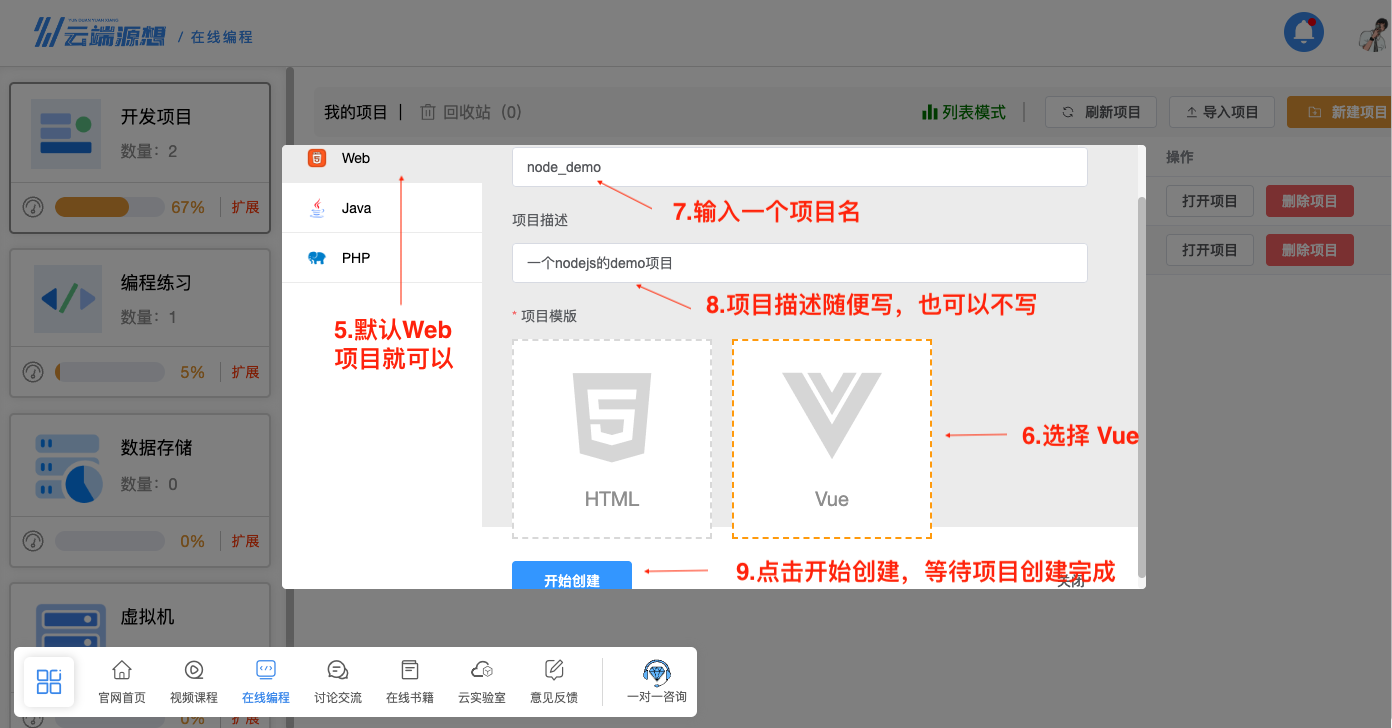
图17 完成创建项目
-
打开创建的项目,等待项目加载并正常打开。
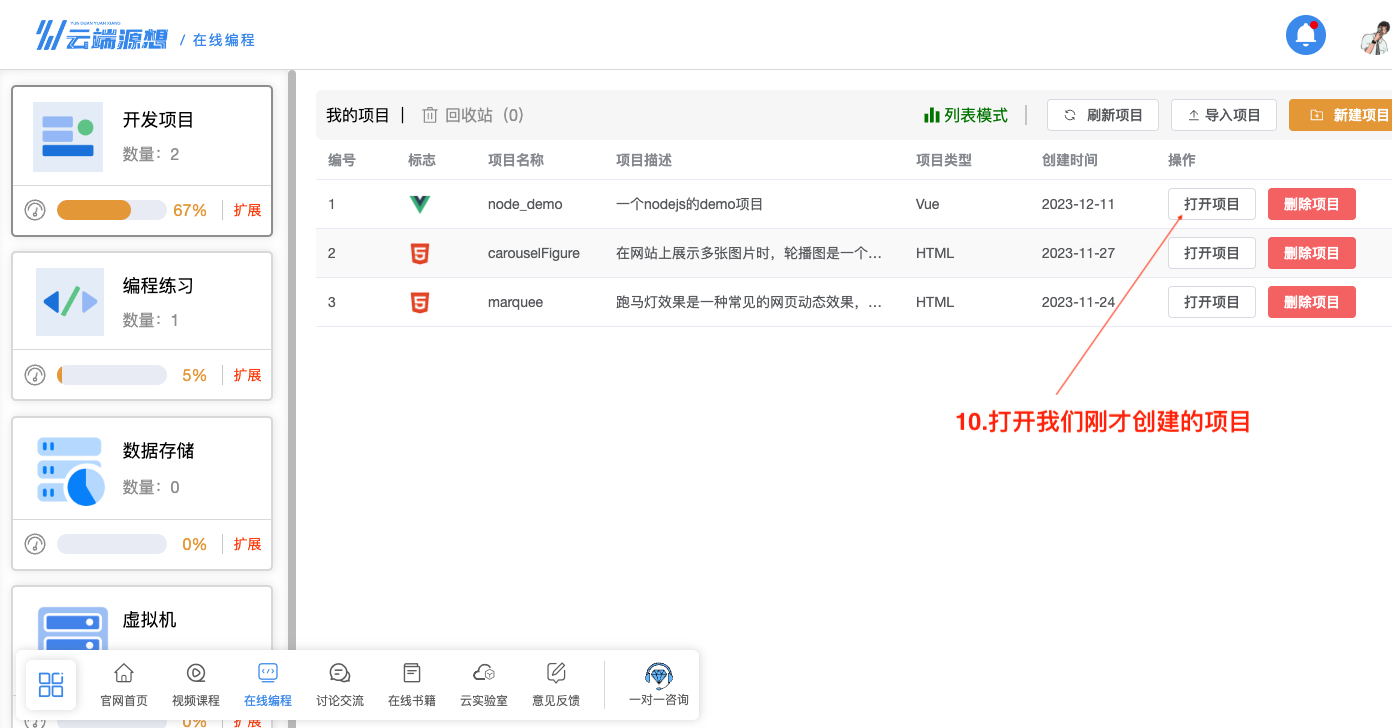
图18 打开创建的项目
-
我们在在线编程下面的终端输入
node -v和npm -v,我们可以看到已经能够正常输出版本号了,是不是很方便。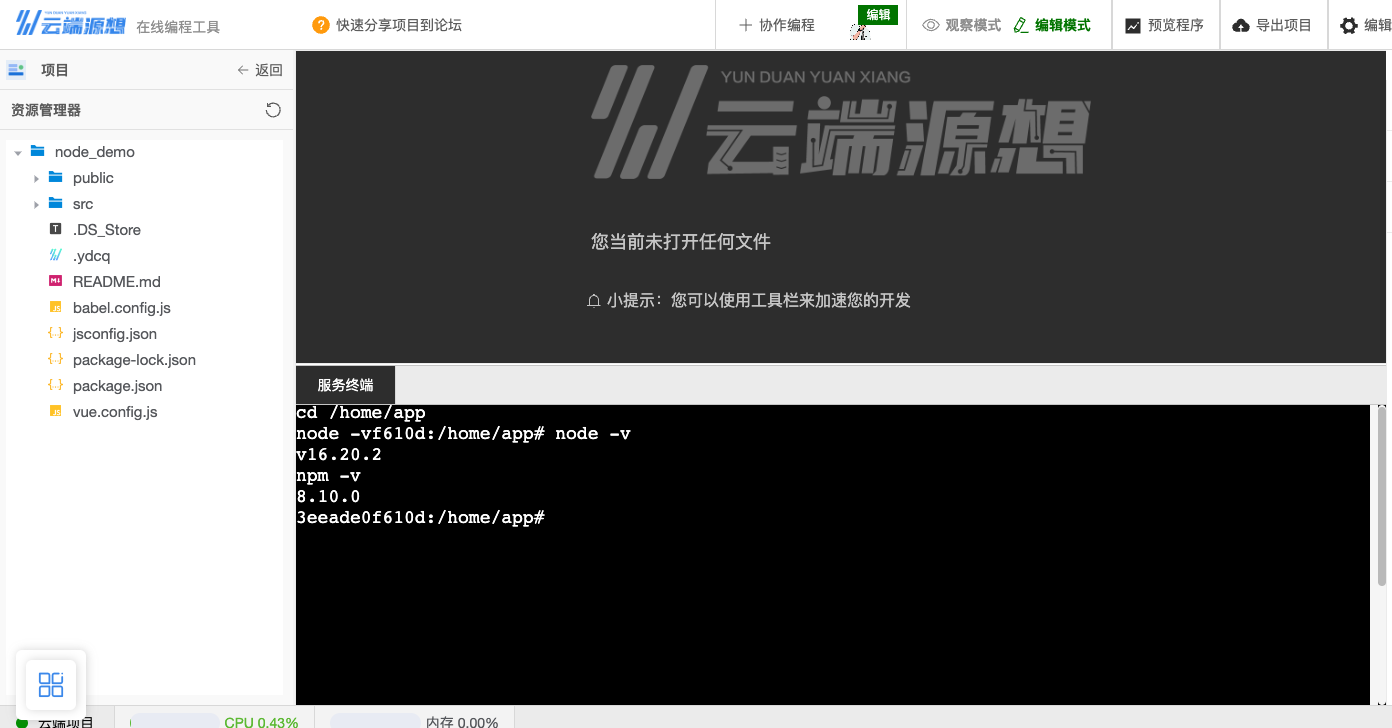
图19 运行node命令
-
我们创建一个
demo.js,并在里面填入console.log("Hello World!");这段代码。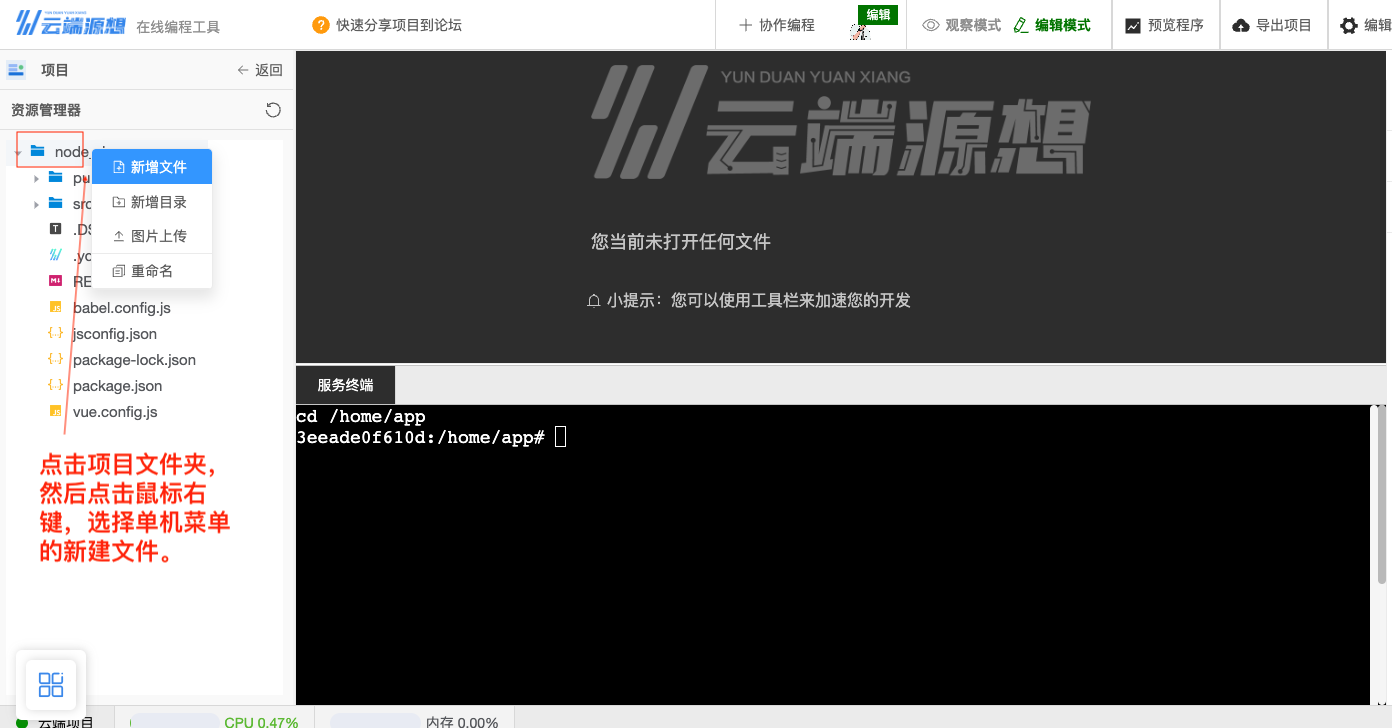
图20 新建文件
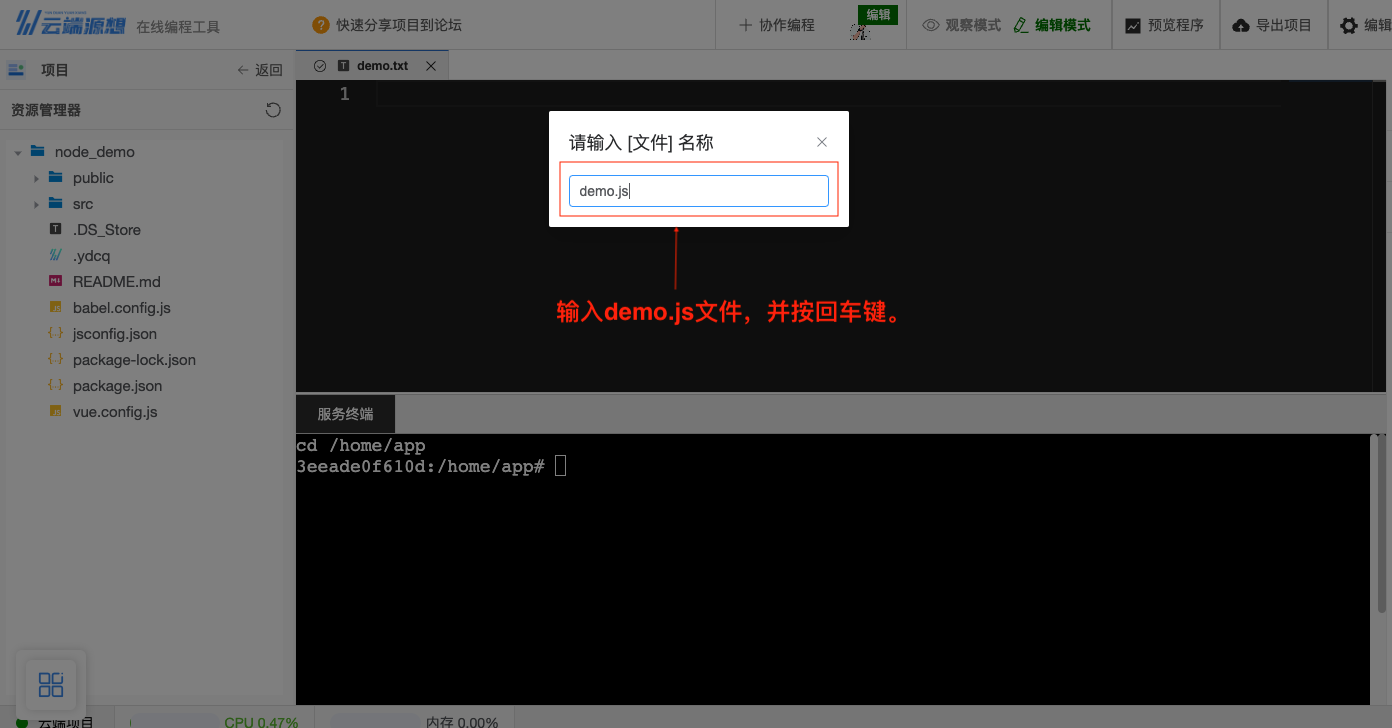
图21 创建demo.js
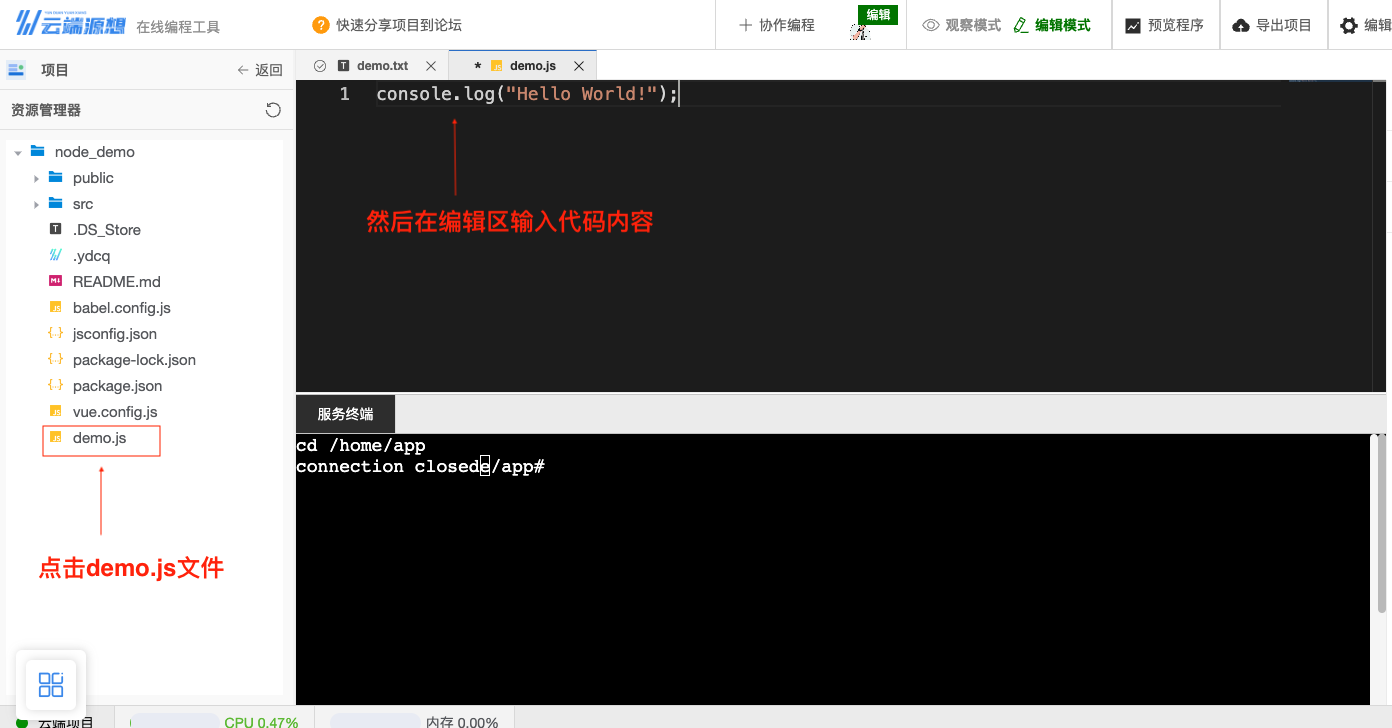
图22 编写代码
-
然后我们在下面的终端输入
node demo.js,命令。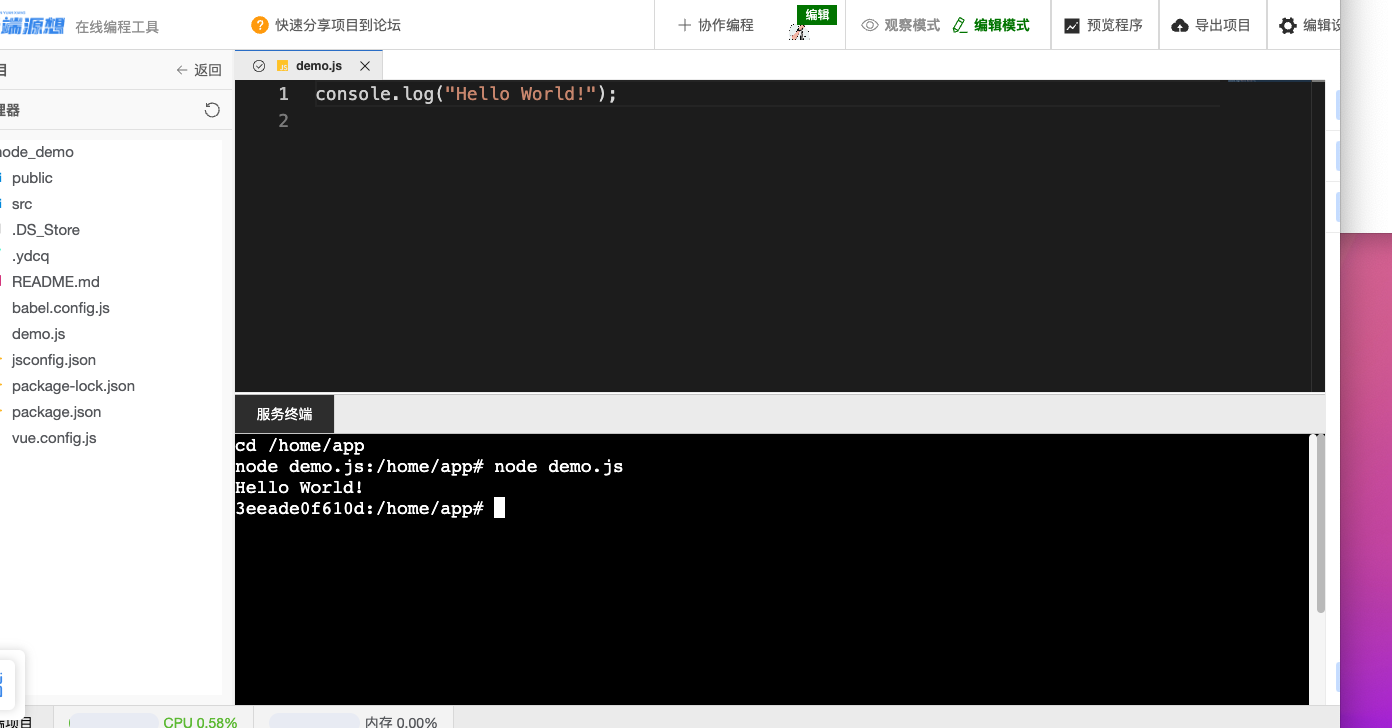
图23 运行demo.js
注意:
1. 输入命令请在英文输入法下进行。
2. 在线编程长时间不操作会断开连接,你需要点击左上角返回然后再重新进入项目才能继续操作。
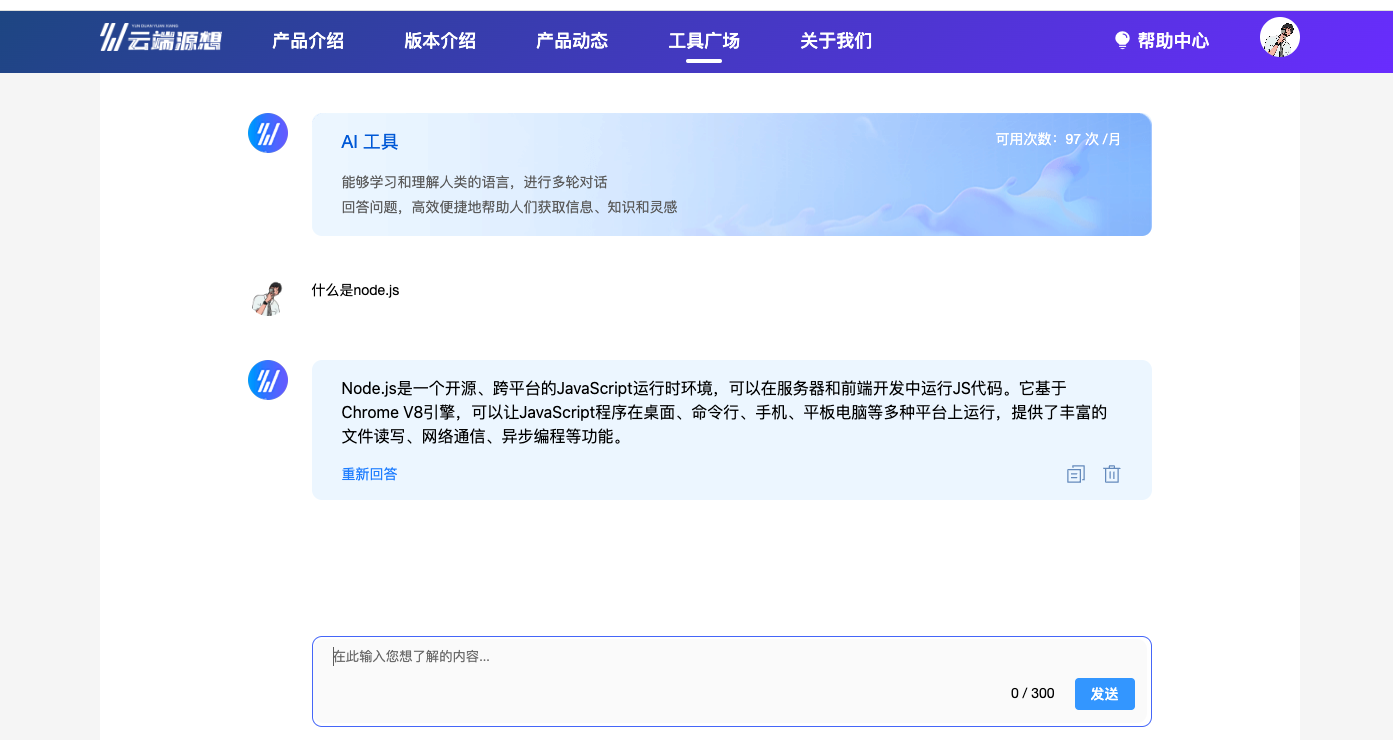
使用云端源想的在线编程工具,我们还可以搭配 智能AI工具 来协助我们进行编程开发等,下面就让我们简单介绍一下吧。
首先先进到智能工具页面,然后我们点击页面上的 智能AI问答。

然后输入我们想要问的问题,稍等片刻,就可以得到问题解答。
如果还有一些学习中或者实际开发当中遇到问题,欢迎大家到远端源想的 论坛交流 板块发帖求助。
3.5 调试
Node.js 的调试器使用 Chrome 开发团队开发的 V8 调试协议作为底层协议,可以通过命令行或图形界面进行调试。
3.5.1 命令行调试
node inspect your-script.js
其中 your-script.js 是你要调试的脚本文件名。这将启动 Node.js 的调试器,并暂停脚本的执行,等你输入调试命令。
以下是一些常见的调试命令:
-
c:继续执行程序直到遇到下一个断点或程序结束。
-
n:执行下一行代码。
-
s:进入当前函数。
-
o:跳出当前函数。
-
setBreakpoint():在当前行设置断点。
-
setBreakpoint(line):在指定行设置断点。
-
setBreakpoint(‘fn()’'):在指定的fn方法设置断点。
-
setBreakpoint(filename, line):在filename文件的line行设置断点。
-
clearBreakpoint(breakpointId):清除指定 ID 的断点。
-
listBreakpoints():列出所有设置的断点。
-
repl:进入 REPL 模式,在该模式下可以查看和修改变量的值。
-
watch(‘variable’):监视一个变量的值。
-
unwatch(‘variable’):取消监视变量。
-
kill:终止当前执行的脚本。
你还可以使用 Ctrl+C 两次来退出调试器。
例如,假设你有一个名为 demo.js 的脚本文件:
function add(a, b) {
return a + b;
}
const result = add(1, 2);
console.log(result);
如果你想要在 add 函数内进行调试,可以在代码中添加一个断点:
function add(a, b) {
debugger;
return a + b;
}
然后使用以下命令启动调试器:
node inspect demo.js
这将会在 debugger; 处暂停程序的执行,等待你的调试命令。在调试器中,你可以使用 c 命令来继续执行程序,或使用 s 命令进入 add 函数内部进行调试。
在实际应用中,你可能需要更多的高级调试功能,例如条件断点、捕获异常、远程调试等,Node.js 调试器还提供了这些功能,你可以查阅 Node.js 文档获取更详细的信息和示例。
3.5.2 VSCode调试
下面我们来讲解一下如何在 VSCode 中开始代码调试。
-
使用 VSCode 打开你的项目,然后点击红色框出来的调试按钮。
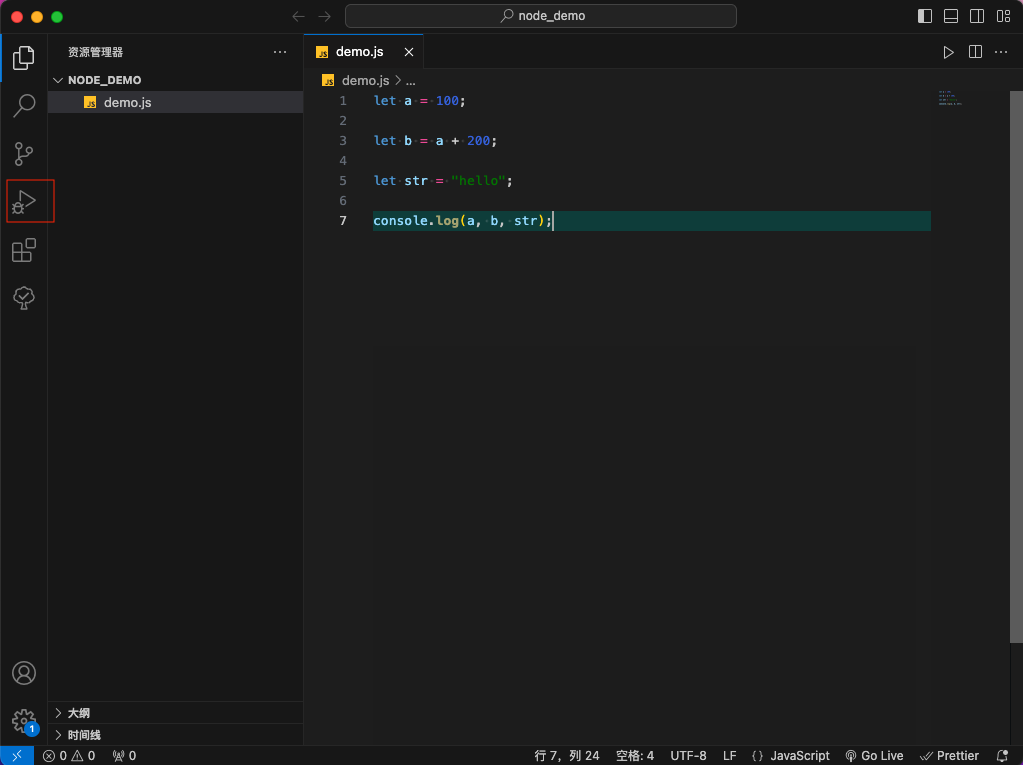
图26 点击调试按钮
-
点击创建
launch.json文件。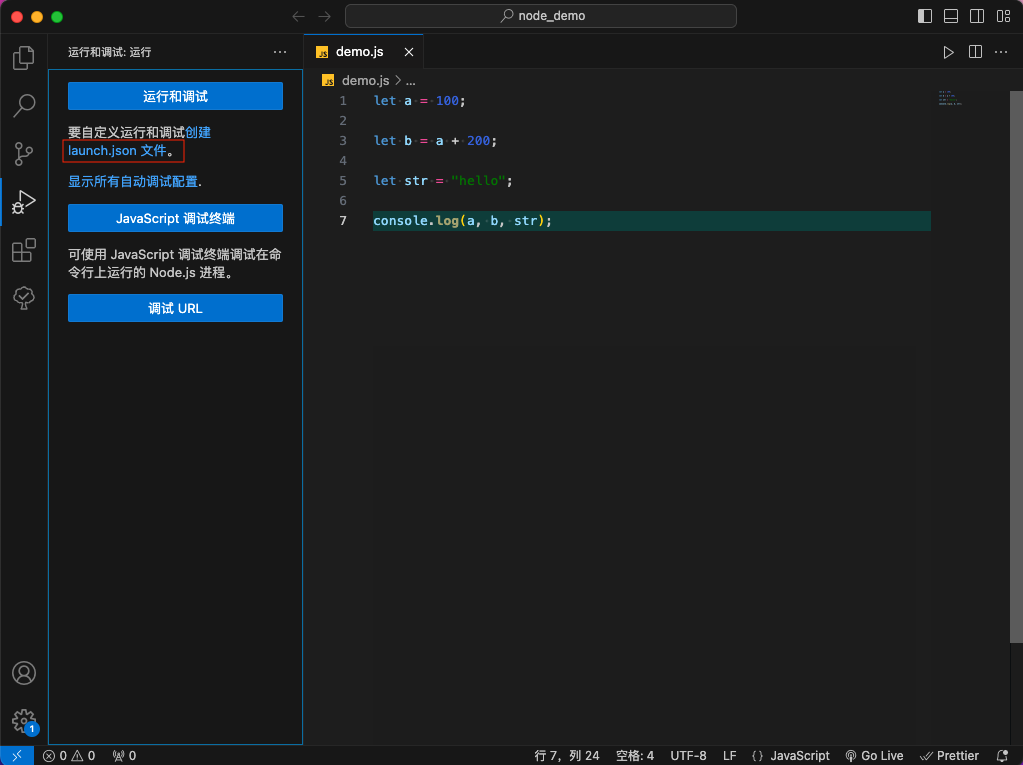
图27 项目创建launch.json
-
点击选择 Node.js。
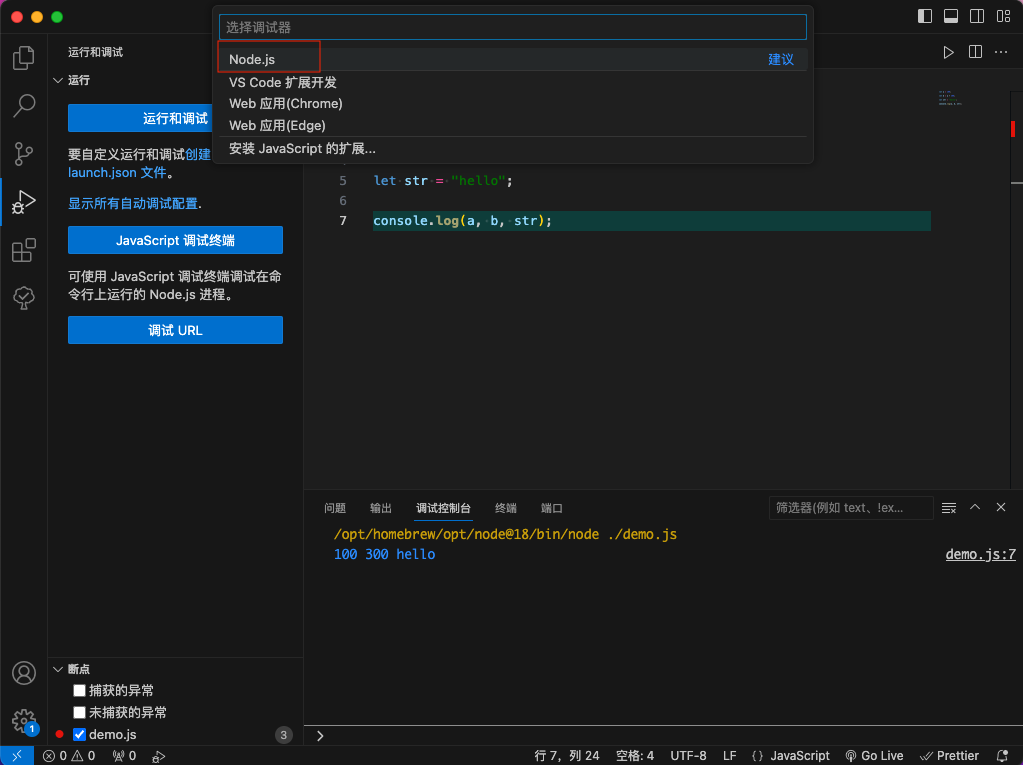
图28 选择Node.js
-
接着就创建好了
launch.json文件。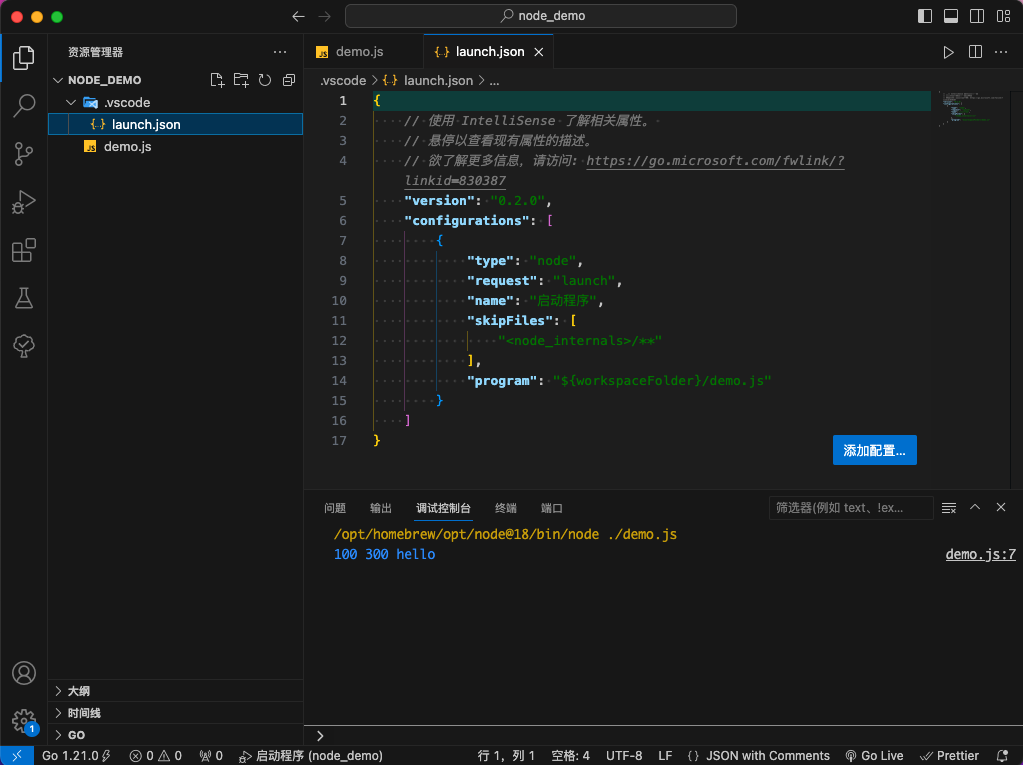
图29 launch.json
-
点击调试按钮,并在代码的行号前面点击标出断点。
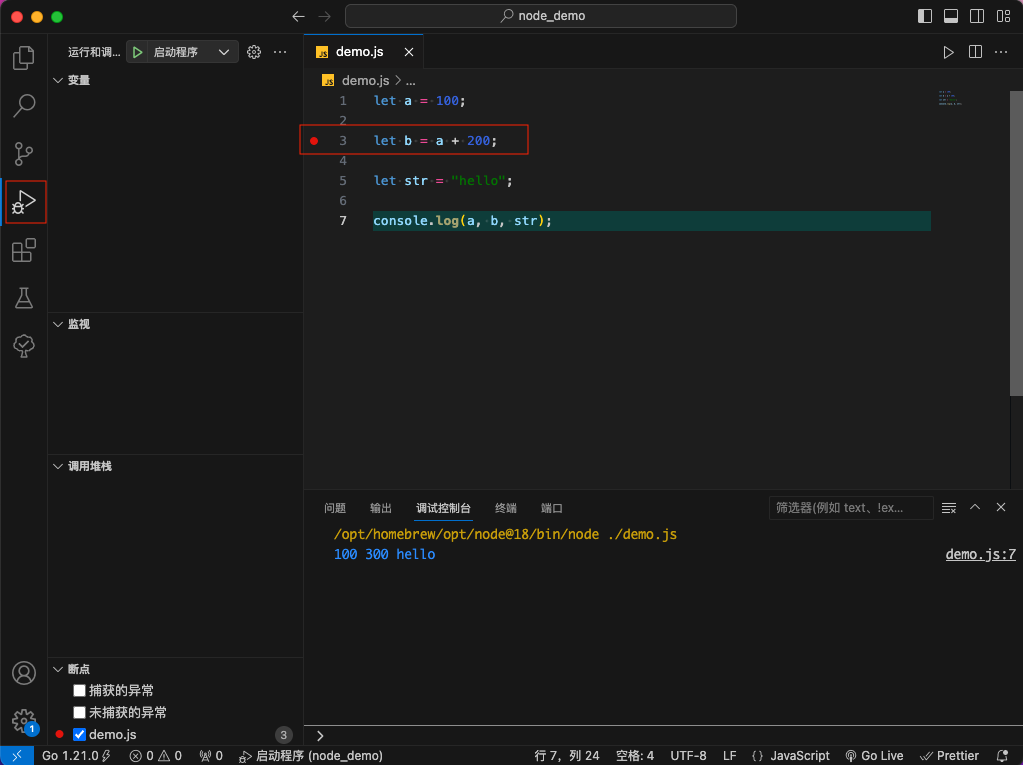
图30 标注断点开始调试
-
点击运行程序,代码就会停在有断点的地方,现在你就可以进行调试了。
图31 点击启动程序开始调试
总结
这一节我们讲解了 Node 的 REPL 运行环境,以及如何在 REPL 环境中编写运行代码等,还讲解了其他几种代码编写和运行工具的使用等。根据你的喜好选择适合自己的方式可以大大提高编写效率。
4-全局对象
4.1 全局对象
Node.js 中有一些全局对象,在任何模块中都可以访问它们,而无需导入或引入。在 JavaScript 中 window 是全局对象,而 Node.js 中的全局对象是 global,除了 global,其他的全局对象都是 global 的属性。通过使用全局对象,你可以轻松地访问和操作各种 Node.js 运行时环境中提供的功能和信息。
下面是一些常见的 Node.js 全局对象:
-
global:
global是 Node.js 的全局对象,类似于浏览器环境中的window对象。你可以在任何模块中使用global来定义全局变量。但是,在编写 Node.js 应用程序时,最好避免在全局范围内定义太多全局变量。 -
process:
process对象提供了有关当前 Node.js 进程的信息,并允许与进程进行交互。例如,你可以使用process.argv来获取命令行参数,使用process.env来访问环境变量,使用process.exit()来退出当前进程等。 -
console:
console对象是一个全局对象,提供了一组用于将输出消息写入控制台的方法,如前面所述。 -
require:
require函数是一个用于加载模块的全局函数。通过require函数,你可以在一个模块中引入其他模块,以便在当前模块中使用其导出的功能。 -
module:
module对象代表当前模块,在每个模块中都是唯一的。它包含有关当前模块的信息和状态,并且可以使用module.exports导出模块的功能。 -
exports:
exports对象是module.exports的一个引用,它被用于导出当前模块的功能。你可以将要导出的内容添加到exports对象上,以便其他模块可以使用require函数引入。
4.1.1 console
Node.js 中的 console 是一个全局对象,提供了一组用于将输出消息写入标准输出流 (stdout) 或标准错误流 (stderr) 的方法。你可以使用这些方法在命令行窗口、终端或日志文件中记录调试信息、警告和错误等信息。
console.log方法
console.log() 是 Node.js 中用于向标准输出流 (stdout) 输出消息的方法。它是 console对象提供的一个常用方法。
console.log() 可以接受一个或多个参数,并将它们打印到控制台。每个参数将使用空格分隔,并以换行符结尾。下面是一些使用 console.log() 的示例:
console.log('Hello, World!'); // 输出: Hello, World!
const name = 'Alice';
const age = 25;
console.log('Name:', name, 'Age:', age); // 输出: Name: Alice Age: 25
const fruits = ['apple', 'banana', 'orange'];
console.log('Fruits:', fruits); // 输出: Fruits: [ 'apple', 'banana', 'orange' ]
注意:console.log() 还支持像C语言的print函数的 %s 和 %d 的占位符。
const name = 'Alice';
const age = 25;
console.log('Name:%s Age:%d', name, age); // 输出: Name: Alice Age: 25
console.error方法
console.error() 是 Node.js 中用于向标准错误流 (stderr) 输出错误消息的方法。它是 console 对象提供的一个常用方法。
与 console.log() 不同,console.error() 将消息写入标准错误流,并以红色字体显示,以突出显示错误性质。这样可以更容易地区分错误消息和普通消息。
console.error() 的用法与 console.log() 类似,可以接受一个或多个参数,并将它们打印到控制台。每个参数将使用空格分隔,并以换行符结尾。下面是一些使用 console.error() 的示例:
const error = new Error('Something went wrong!');
console.error(error); // 输出 Error: Something went wrong!
const name = 'Alice';
const age = 25;
console.error('Name:', name, 'Age:', age); // 输出 Error: Name: Alice Age: 25
console.trace方法
console.trace() 是 Node.js 中的一个方法,用于在控制台输出当前函数的调用堆栈(stack trace)。它是 console 对象提供的一个常用方法。
当你调用 console.trace() 时,它会打印当前函数或代码段的调用堆栈信息,显示函数的调用关系和位置。这对于调试和追踪代码执行路径非常有用,特别是在定位错误和查找代码路径时。
下面是使用 console.trace() 的示例:
function foo() {
bar();
}
function bar() {
baz();
}
function baz() {
console.trace();
}
foo();
运行上述代码将输出以下内容:
Trace
at baz (/Users/ydcq/Desktop/web/node_demo/demo.js:10:11)
at bar (/Users/ydcq/Desktop/web/node_demo/demo.js:6:3)
at foo (/Users/ydcq/Desktop/web/node_demo/demo.js:2:3)
at Object.<anonymous> (/Users/ydcq/Desktop/web/node_demo/demo.js:13:1)
at Module._compile (node:internal/modules/cjs/loader:1256:14)
at Module._extensions..js (node:internal/modules/cjs/loader:1310:10)
at Module.load (node:internal/modules/cjs/loader:1119:32)
at Module._load (node:internal/modules/cjs/loader:960:12)
at Function.executeUserEntryPoint [as runMain] (node:internal/modules/run_main:81:12)
at node:internal/main/run_main_module:23:47
这些信息的每一行都代表调用堆栈中的一个函数,并显示了函数的名称、文件名、行号和列号。从上到下,可以看到函数的调用顺序,最后是当前文件的入口点。
console.trace() 在调试和排查问题时非常有用,可以帮助你了解代码是如何被调用的,以及它们之间的关系。通过追踪函数的调用路径,你可以更好地理解程序的执行流程,并找出可能的问题所在。
console.time 方法和 console.timeEnd 方法
console.time() 和 console.timeEnd() 是Node.js中用于测量代码执行时间的方法,它们是console对象提供的一对常用方法。
console.time(label) 用于开始计时器,并将其与一个标签 (label) 相关联。标签可以是任何字符串,用于标识计时器。你可以同时启动多个计时器,只需为每个计时器使用不同的标签。
console.timeEnd(label) 用于停止计时器,并输出经过的时间。它会根据与计时器关联的标签 (label) 找到相应的计时器,并计算出从 console.time() 到 console.timeEnd() 之间经过的时间。
下面是使用 console.time() 和 console.timeEnd() 的示例:
console.time('myTimer'); // 启动计时器
// 执行一些耗时操作
for (let i = 0; i < 1000000; i++) {
// do something
}
console.timeEnd('myTimer'); // 停止计时器并输出时间
在这个示例中,我们使用 console.time('myTimer') 开始计时器,然后执行一些耗时操作,最后使用 console.timeEnd('myTimer') 停止计时器并输出经过的时间。输出显示计时器标签和经过的时间(以毫秒为单位)。
通过使用 console.time() 和 console.timeEnd(),你可以测量代码中特定部分的执行时间,以便更好地了解程序的性能和优化需求。这在优化代码、比较不同实现方式的性能等方面非常有用。
4.1.2 process
process 是 Node.js 中的一个全局对象,它提供了与当前 Node.js 进程相关的信息和控制能力,包括进程环境、命令行参数、标准输入输出、事件通知等。你可以使用 process 对象来访问这些信息和功能。
下面是一些常用的 process 对象属性和方法:
- process.argv:包含命令行参数的数组,第一个元素是 Node.js 执行程序的路径,第二个元素是被执行的 JavaScript 文件的路径,后续元素是传递给程序的命令行参数。
- process.env:包含进程环境变量的对象。
- process.stdin:标准输入流的可读流对象。
- process.stdout:标准输出流的可写流对象。
- process.stderr:标准错误流的可写流对象。
- process.cwd():返回当前工作目录的路径。
- process.exit([exitcode]):结束进程并返回指定的退出码(exitcode),默认为0。
除了上述方法和属性外,process 对象还提供了许多其他有用的功能,如事件通知机制、信号处理、进程崩溃检测等。
下面是一个使用 process 对象的示例:
// 打印命令行参数
console.log('命令行参数:', process.argv);
// 打印环境变量
console.log('环境变量:', process.env);
// 监听SIGINT事件,在接收到Ctrl+C时打印信息并退出
process.on('SIGINT', () => {
console.log('接收到SIGINT信号,即将退出');
process.exit(0);
});
运行上述代码将输出命令行参数和环境变量信息,并监听 SIGINT 事件。在接收到 SIGINT 信号(例如按下Ctrl+C)时,程序将打印消息并使用 process.exit() 退出进程。
process 对象提供了许多有用的功能,可以帮助你更好地控制和管理 Node.js 进程。使用它,你可以访问进程相关的信息、事件和功能,并对其进行操作和控制。
4.2 全局函数
Node.js 中还定义了一些全局函数,接下来我们将介绍这些全局函数。
4.2.1 setTimeout 函数和 clearTimeout 函数
当在 Node.js 中使用 JavaScript 编写异步代码时,可能会经常用到 setTimeout 和 clearTimeout 函数。这两个函数用于处理定时器相关的操作。
setTimeout 函数用于在一定的时间延迟后执行指定的任务。它接受两个参数:要执行的任务(可以是函数或字符串)和延迟的时间(以毫秒为单位)。下面是一个示例:
setTimeout(() => {
console.log('定时器已触发');
}, 3000);
上述代码将在3秒后输出 “定时器已触发”。
clearTimeout 函数用于取消之前通过 setTimeout 创建的定时器。它接受一个参数,即要取消的定时器对象。下面是一个示例:
const timer = setTimeout(() => {
console.log('这个定时器将被取消');
}, 2000);
clearTimeout(timer);
上述代码中,通过 setTimeout 创建了一个定时器,并将其赋值给了变量 timer。然后在2秒之前,通过 clearTimeout 取消了这个定时器,因此任务不会被执行。
需要注意的是,`setTimeout` 函数返回一个定时器对象,可以通过这个对象来取消定时器。如果不取消定时器,定时器会在延迟时间到达后自动执行任务。
4.2.2 setInterval 函数和 clearInterval 函数
setInterval 和 clearInterval 是两个用于处理定时器的函数。setInterval 函数用于在指定的时间间隔内重复执行指定的任务。它接受两个参数:要执行的任务(可以是函数或字符串)和重复执行任务的时间间隔(以毫秒为单位)。
下面是 setInterval 一个示例:
setInterval(() => {
console.log('这个任务将每隔2秒钟执行一次');
}, 2000);
上述代码将每隔2秒输出一次"这个任务将每隔2秒钟执行一次"。
clearInterval 函数用于取消之前通过 setInterval 创建的定时器。它接受一个参数,即要取消的定时器对象。下面是一个示例:
const timer = setInterval(() => {
console.log('这个定时器将被取消');
}, 2000);
clearInterval(timer);
上述代码中,通过 setInterval 创建了一个定时器,并将其赋值给了变量 timer。然后通过 clearInterval 取消了这个定时器,因此任务不会继续执行。
需要注意的是,`setInterval` 函数返回一个定时器对象,可以通过这个对象来取消定时器。如果不取消定时器,定时器会在每个时间间隔到达后自动执行任务(会一直执行这个任务)。
4.2.3 定时器的ref函数和unref函数
在 Node.js 的定时器中,ref 函数和 unref 函数是用于控制定时器是否参与事件循环的函数。
ref 函数用于保持定时器活跃,使其参与事件循环。默认情况下,定时器是处于活跃状态的,即参与事件循环。但是,在某些情况下,我们可能希望临时暂停定时器,不让其参与事件循环,这时可以使用 unref 函数。下面是一个示例:
const timer = setInterval(() => {
console.log('定时器任务');
}, 1000);
timer.ref(); // 将定时器设置为活跃状态
// 5秒后暂停定时器
setTimeout(() => {
timer.unref(); // 暂停定时器,不参与事件循环
}, 5000);
上述代码中,通过 setInterval 创建了一个每秒执行一次的定时器。然后使用 timer.ref() 将定时器设置为活跃状态,确保它参与事件循环。在5秒后,使用 timer.unref() 将定时器暂停,不让其参与事件循环。
需要注意的是,ref 和 unref 函数只对 setInterval 和 setTimeout 创建的定时器有效。对于其他类型的定时器,如 process.nextTick 或 setImmediate 创建的定时器,这些函数没有作用。
总结
通过使用这些全局对象,可以轻松地访问和操作各种 Node.js 运行时环境中提供的功能和信息。请注意,在编写 Node.js 应用程序时,尽量避免滥用全局对象,以维护代码的可读性和可维护性。
5-CommonJS
CommonJS 是一个 JavaScript 模块化规范,主要用于服务器端 JavaScript 编程。它提供了一套简单的API来定义和加载模块,使得 JavaScript 代码能够按照模块化的方式进行组织。
5.1 CommonJS规范
CommonJS 规范包括模块、包、系统、二进制、控制台、编码、文件系统、套接字单元测试等。Node.js 是 CommonJS 规范的一个实现,它采用了 CommonJS 规范作为其模块系统的基础。在 Node.js 中,每个 JavaScript 文件被视为一个单独的模块,可以通过 require 函数引入其他模块,同时使用 module.exports 或 exports 对象来导出模块的接口。
在 Node.js 中,当模块被第一次引入时,Node.js 会执行该模块的代码,并缓存模块的导出接口,之后再次引入相同的模块时,将直接返回已缓存的导出接口,而不会重新执行模块的代码。
5.2 模块化有什么作用?
-
代码组织和模块化:通过模块化可以将代码分解为相互独立的功能单元,每个模块负责实现特定的功能。这样可以使代码更具可读性和可维护性,便于开发者理解和修改代码。
-
依赖管理:在实际开发中,一个项目通常会依赖于大量的第三方库或框架,模块化可以帮助管理这些依赖关系,避免代码混乱和冲突。
-
代码复用:通过模块化可以将常用的功能封装为模块,然后在多个地方进行引用和复用,避免重复编写相似的代码。
-
性能优化:模块化还可以帮助提高应用程序的性能,因为模块可以被缓存,避免重复加载和执行。
-
作用域隔离:每个模块都拥有自己的作用域,可以避免全局变量污染和命名冲突。
Node.js 需要模块来帮助开发者更好地组织和管理代码,提高代码的可维护性和可复用性,同时也提高了应用程序的性能和可扩展性。
5.3 CommonJS的模块规范
Node.js 遵循 CommonJS 规范,它定义了一套模块化开发的标准,使得 JavaScript 代码可以被组织成独立的、可复用的模块。
CommonJS 是 Node.js 最早采用并广泛使用的模块规范,它的主要特点是同步加载模块。
CommonJS 规范对模块的定义主要包含以下三个部分:
模块引用(require):使用 require 函数加载模块。在 Node.js 中,每个文件都被视为一个独立的模块,通过 require 函数可以加载其他模块的代码。
模块定义(exports 和 module.exports):使用 exports 和 module.exports 对象暴露模块的接口。exports 对象是对 module.exports 的简单封装,用于导出模块的接口。
模块标识(module):每个模块都有一个 module 对象,它表示当前模块本身,包含模块的文件名、模块的导出对象等信息。
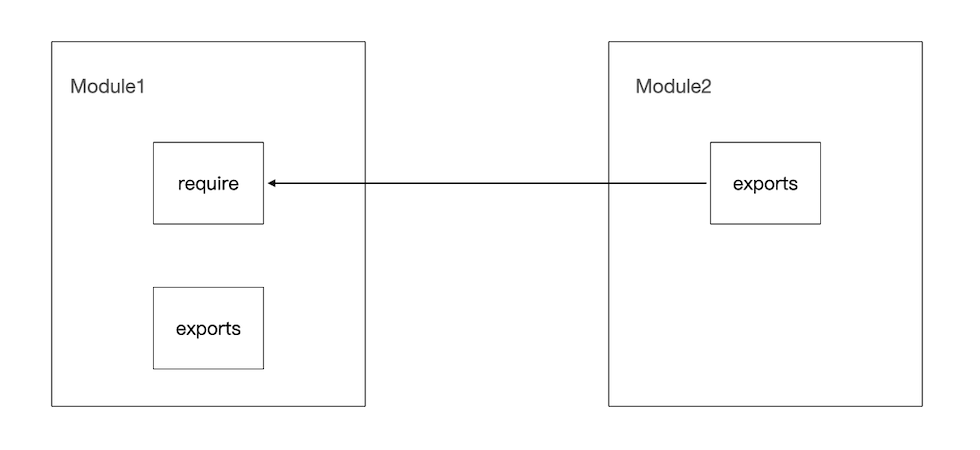
下面是一个简单的示例,演示了如何使用 CommonJS 规范进行模块化开发:
hello.js
// 模块定义
const greeting = 'Hello,';
function sayHello(name) {
console.log(greeting + name + '!');
}
// 暴露模块的接口
module.exports = {
sayHello,
};
main.js
// 模块引用
const hello = require('./hello');
// 使用模块的接口
hello.sayHello('world'); // 输出: Hello,world
在上面的示例中,我们定义了一个 sayHello 函数,并将其作为模块的接口暴露出去。然后在另一个文件中,使用 require 函数加载该模块,并使用模块的接口调用 sayHello 函数。
总结起来,CommonJS 规范是 Node.js 中用于实现模块化开发的标准,它定义了模块的引用、定义和标识方式。这种模块化的机制使得 Node.js 具有良好的可扩展性和灵活性,便于开发大型和复杂的应用程序。
5.4 其他规范
当谈到 Node.js 的多种模块规范时,我们可以详细了解 CommonJS、ES6 Modules、CMD 和 AMD。CommonJS 是为了后端 JavaScript 而制定的规范,它并不适用于前端的使用场景。因此就诞生了 AMD 规范(Asynchronous Module Definition:异步模块定义),AMD 规范还有 CMD 规范(Common Module Definition:通用模块定义)。
这些规范对于模块的定义、导入和导出方式都有不同的特点和语法。让我们逐一来介绍它们:
5.4.1 AMD规范
AMD 是用于浏览器端 JavaScript 模块化的一种规范,允许异步加载模块,有利于提高应用程序的性能。
导出模块:
define(['dependency1', 'dependency2'], function(dep1, dep2) {
// 模块内容
return {
func1: function() { /*...*/ },
func2: function() { /*...*/ }
};
});
导入模块:
require(['module1', 'module2'], function(m1, m2) {
// 使用模块
});
5.4.2 CMD规范
CMD 是另一种用于浏览器端的模块化规范,它与 AMD 类似,但更加强调模块的延迟执行和依赖就近原则。
导出模块:
define(function(require, exports, module) {
// 模块内容
module.exports = {
func1: function() { /*...*/ },
func2: function() { /*...*/ }
};
});
导入模块:
define(function(require, exports, module) {
var dep1 = require('dependency1');
var dep2 = require('dependency2');
// 模块内容
module.exports = {
func1: function() { /*...*/ },
func2: function() { /*...*/ }
};
});
5.4.3 ESM规范
ESM 是 ECMAScript 2015 引入的官方 JavaScript 模块化规范,用于浏览器端和 Node.js。它提供了静态导入和导出的能力。
导出模块:
export default myFunction;
export { func1, func2 };
导入模块:
import moduleName from 'path/to/module';
import { func1, func2 } from 'path/to/module';
ESM 的语法比较简洁,且与其他规范有一些差异。ESM 还在不断发展中,但已经成为了现代 JavaScript 开发中的主流模块化规范。
需要注意的是,AMD 和 CMD 主要用于浏览器端的模块化开发,而 CommonJS 和 ESM 则更多地用于 Node.js 和现代浏览器环境。在实际应用中,可以根据项目需求和开发环境选择合适的规范。同时,也可以使用工具(如 RequireJS、SystemJS 和 Babel)来实现不同规范之间的兼容和转换。
总结
CommonJS 规范定义了模块化的机制和规则,通过导入和导出模块的方式实现代码的组织、复用和共享。它具有简单、易用的特点,并且适用于服务器端的 JavaScript 开发。不同的规范提供了不同的特性和优势,开发者可以根据项目需求选择合适的模块化规范。
6-模块
通过模块系统,Node.js 实现了代码的模块化,它允许开发者将代码分割成小的、独立的模块,以提高代码的可维护性,使得代码更加清晰、并提供了良好的封装和复用性。
6.1 Node.js的模块实现
Node.js 的模块实现是基于 CommonJS 规范的,它提供了一种简单而有效的方式来组织、加载和复用代码。Node.js 的模块系统遵循以下几个重要原则:
-
每个文件都被视为一个独立的模块 (一个模块可以是一个 JavaScript 文件,也可以是一个JSON文件等。),每个模块都有自己的作用域。模块中定义的变量、函数和类默认情况下是私有的,只能在模块内部使用。
-
使用
module.exports或exports对象将接口暴露给其他模块使用。这些导出的接口可以是变量、函数、类或对象。 -
使用
require()函数加载其他模块。require()函数接受一个模块标识符作为参数,并返回该模块的导出对象。
下面详细介绍 Node.js 的模块实现:
6.1.1 模块加载
当调用 require() 函数加载一个模块时,Node.js 会执行以下步骤:
-
解析模块路径:根据传入的模块标识符,Node.js 会解析出模块的绝对路径。模块标识符可以是相对路径(以./或…/开头)或者是一个模块名(如’http’或’lodash’)。
-
缓存检查:Node.js 会检查模块是否已经被缓存,如果已经被缓存,则直接返回缓存的模块对象,避免重复加载和解析。
-
模块编译:如果模块没有被缓存,则进行模块编译。Node.js 会根据模块的文件类型(
.js、.json或.node)使用适当的编译器对模块进行编译,并生成一个模块对象。 -
模块包装:在模块编译完成后,Node.js 会将模块的代码包装在一个函数中,该函数接受五个参数:
require、module、exports、__filename和__dirname。 -
模块执行:包装函数被调用,模块的代码开始执行。在模块内部,可以通过
module.exports或exports对象将接口暴露给其他模块使用。 -
模块缓存:模块的导出对象被缓存起来,以便下次加载时直接返回缓存的对象。
6.1.2 __filename和__dirname
__filename 和 __dirname 是两个特殊的全局变量,用于获取当前模块文件的完整路径和所在目录的完整路径。
- __filename
__filename 表示当前模块文件的完整路径,包括文件名。这个路径是绝对路径,可以通过它获取到当前模块文件的位置。
console.log(__filename);
// 输出:/Users/ydcq/Desktop/web/node_demo/demo.js
- __dirname
__dirname 表示当前模块文件所在目录的完整路径。与 __filename 不同,__dirname 表示的是所在目录的路径,不包括文件名。
console.log(__dirname);
// 输出:/Users/ydcq/Desktop/web/node_demo
这两个全局变量经常用于构建文件路径或者加载其他模块时需要使用的路径信息。在模块化开发中,通常会用到这两个变量来构造文件的绝对路径,以便正确地加载模块或读取文件。
6.1.3 模块导出
模块中的接口可以通过 module.exports 或 exports 对象进行导出。
module.exports 是对 exports 对象的引用,它是导出的主要方式。可以将任何类型的值赋给 module.exports,例如一个对象、一个函数、一个类或一个原始数据类型。
exports 是 module.exports 的一个简便方式,它是一个空对象。可以通过给 exports 对象添加属性和方法来导出接口。
例如,在一个名为 foo.js 的模块中,可以定义一个私有变量和一个导出函数:
// 私有变量
var privateVariable = 'This is a private variable';
// 导出函数
exports.sayHello = function() {
console.log('Hello, world!');
};
在另一个模块中,可以通过 require() 函数加载并使用 foo.js 模块的导出接口:
var foo = require('./foo');
foo.sayHello(); // 输出 "Hello, world!"
6.1.4 模块引入
在一个模块中,可以通过 require() 函数加载其他模块,并使用其导出接口。
require() 函数接受一个模块标识符作为参数,该标识符可以是相对路径或者是一个模块名。如果是相对路径,则表示加载当前目录下的模块文件;如果是模块名,则表示加载安装在 node_modules 目录下的模块。
例如,在一个名为 bar.js 的模块中,可以引入 foo.js 模块并调用其导出函数:
var foo = require('./foo');
foo.sayHello(); // 输出 "Hello, world!"
这里,我们使用相对路径 ./foo 来引入 foo.js 模块,并将其返回值保存在 foo 变量中。然后,我们调用了 foo 模块的 sayHello() 函数来输出一条消息。
6.1.5 模块缓存
Node.js 会对引入的模块进行缓存,以避免重复加载和解析模块。当第一次引入一个模块时, Node.js 会将该模块的导出对象缓存起来。当再次引入该模块时,Node.js 会直接返回缓存的导出对象,而不会重新加载和解析该模块。
例如,在一个名为 qux.js 的模块中,可以多次引入同一个模块:
var foo1 = require('./foo');
var foo2 = require('./foo');
console.log(foo1 === foo2); // 输出 true
这里,我们在两个不同的变量中引入了 foo.js 模块,然后检查它们是否相等。由于模块缓存的存在,这两个变量的值应该是相等的。
需要注意的是,如果一个模块被多个模块引入,则它的导出对象的改变会影响所有引入该模块的模块。因此,在编写模块时,应该避免修改导出对象的属性和方法。
6.1.6 自定义模块解析策略
在 Node.js 中,可以通过自定义模块解析策略来支持更复杂的模块依赖关系。例如,可以将模块路径映射到其他位置,或者根据环境变量来动态决定使用哪个模块。
要自定义模块解析策略,可以使用 require.resolve() 函数来获取模块的路径,然后修改该路径来实现自定义解析。例如,在一个名为 quux.js 的模块中,可以使用环境变量来决定使用哪个模块:
var moduleName = process.env.MODULE_NAME || './foo';
var modulePath = require.resolve(moduleName);
var module = require(modulePath);
module.sayHello(); // 输出 "Hello, world!"
这里,我们通过 process.env.MODULE_NAME 环境变量来决定使用哪个模块,默认情况下使用 ./foo 模块。然后,我们使用 require.resolve() 函数来获取该模块的路径,并将其返回值保存在 modulePath 变量中。最后,我们使用 require() 函数来加载该模块,并调用其导出函数来输出一条消息。
6.1.7 模块循环依赖
在 Node.js 的模块系统中,当存在循环依赖时,Node.js 会解决模块加载的问题。
循环依赖是指两个或多个模块之间相互引用,形成一个闭环的依赖关系。在这种情况下,Node.js 会返回已经部分加载的模块对象,并将其缓存起来。当循环依赖的模块被完全加载后,引用关系会得到解决,模块对象中的导出接口会被填充。
例如,假设存在两个模块 a.js 和 b.js,并且它们彼此相互引用:
a.js
var b = require('./b');
console.log('a:', b.variable);
exports.variable = 'This is a';
b.js
var a = require('./a');
console.log('b:', a.variable);
exports.variable = 'This is b';
当我们加载 a.js 模块时,a.js 会尝试加载 b.js 模块。然而,由于 b.js 又引用了 a.js 模块,Node.js会返回 a.js 的部分加载结果(即 module.exports 或 exports 对象),并将其缓存起来。然后,b.js 继续加载完成,并填充 a.js 模块中的导出接口。
在这种情况下,我们可以看到 a.js 和 b.js 模块互相引用了彼此的导出接口,但由于模块缓存的存在,它们不会陷入无限循环的加载过程。
Node.js 的模块实现基于 CommonJS 规范,并采用简单而灵活的方式来组织、加载和复用代码。模块可以通过 module.exports 或 exports 对象进行导出,通过 require() 函数进行引入。当存在循环依赖时,Node.js 会解决模块加载的问题并保证正确的导出和缓存。
6.2 模块对象的属性
在 Node.js 中,每个模块都有一个特殊的模块对象 module,它包含了当前模块的信息和属性。以下是 module 对象的一些常用属性:
- id:模块的标识符,通常是模块的绝对路径。
- exports:模块的导出接口,可以通过修改该属性来导出模块的功能。
- filename:模块的文件名,即模块的绝对路径。
- loaded:模块是否已加载完成的标志,值为true或false。
- parent:引用当前模块的模块对象。
- children:当前模块引用的其他模块对象的数组。
这些属性可以通过在模块中直接访问 module 对象来获取。例如,在一个模块中可以使用 module.id 来获取当前模块的标识符,使用 module.exports 来导出模块的功能。以下是一个示例:
// 模块定义
console.log('module id:', module.id);
console.log('module filename:', module.filename);
// 修改导出接口
module.exports = {
foo: 'bar'
};
在上述示例中,我们首先输出了模块的标识符和文件名。然后,通过修改 module.exports 属性,将一个对象导出为模块的功能。
需要注意的是,`module` 对象是模块内部的一个局部对象,只能在模块内部使用。它提供了一些有用的属性和方法来操作当前模块的信息和导出接口。
除了以上常用属性,module 对象还具有一些其他的属性和方法:
- require(id):加载和返回指定模块的导出接口。如果模块已经缓存,则直接返回缓存的导出接口,否则将加载并执行模块,并将其导出接口返回。
- paths:一个数组,表示 Node.js 在查找模块时要搜索的路径列表。
- builtinModules:一个数组,包含了 Node.js 内置模块的名称。
- wrapper:一个字符串,表示模块代码的包装函数,默认值为 (
function (exports, require, module, __filename, __dirname) { })。
6.3 核心模块
Node.js 的核心模块是一组原生的模块,提供了许多基本的功能和工具,可以在 Node.js 环境中直接使用,无需额外安装。以下是一些常用的 Node.js 核心模块及其功能:
-
fs(File System)模块:用于处理文件系统操作,包括读取、写入、修改、删除文件等。
-
http 模块:用于创建 HTTP 服务器和客户端,可以实现 Web 服务器的功能,处理 HTTP 请求和响应。
-
path 模块:用于处理文件路径,提供了一些方法来解析、拼接、规范化文件路径等。
-
os(Operating System)模块:用于获取操作系统相关的信息,如 CPU 架构、内存使用情况、操作系统平台等。
-
events 模块:用于实现事件驱动编程,提供了一些类和方法来处理事件的注册、触发和监听。
-
util 模块:提供了一些实用函数,包括继承、类型判断、错误处理等常用的工具函数。
-
crypto 模块:用于提供加密和解密功能,包括哈希、加密、解密、签名等安全相关的操作。
-
stream 模块:用于处理流式数据,可以实现数据的读取、写入和转换等操作,特别适用于大型数据的处理。
-
buffer 模块:用于处理二进制数据,提供了一些方法来创建、操作和转换二进制数据。
-
querystring 模块:用于处理 URL 查询字符串,可以解析、序列化和修改查询字符串。
除了以上列举的核心模块,Node.js 还有其他许多模块可供使用,如 child_process、net、dns、crypto 等,它们提供了更多丰富的功能和工具,使得开发人员可以根据自己的需求进行更灵活的开发。同时,Node.js 也支持模块的扩展和第三方模块的使用,使得开发人员可以利用社区的资源来解决各种问题。
总结
Node.js 的模块实现基于 CommonJS 规范,并采用简单而灵活的方式来组织、加载和复用代码。模块可以通过 module.exports 或 exports 对象进行导出,通过 require() 函数进行引入。当存在循环依赖时,Node.js 会解决模块加载的问题并保证正确的导出和缓存。
Node.js 的模块化开发方式可以帮助开发人员有效组织和管理代码,提高代码的可重用性和可维护性。核心模块、第三方模块和自定义模块相互配合,为开发者提供了丰富的功能和工具。模块导入和导出机制以及模块解析规则使得模块之间的依赖关系清晰可见。
7-包和NPM
7.1 包
包(Package)是一种用于组织、管理和共享代码的机制。一个包可以包含多个模块,以及描述包信息的 package.json 文件。Node.js 通过包的机制实现了代码的模块化和复用,使得开发者可以轻松地组织和管理自己的代码,同时也能方便地使用其他人共享的代码。
CommonJS 包规范主要由包结构和包描述文件组成,包其实就是一个归档文件,即一个目录打包成 .zip 或者 .tar.gz 格式的文件。符合 CommonJS 规范的包的结构还应该包括一下几点:
- package.json:包的描述文件。
- bin:用于存放二进制可执行文件的目录。
- lib:用于存放JavaScript代码的目录。
- doc:用于存放文档的目录。
- test:用于存放单元测试用例的代码。
注意:为了提高兼容性,建议你在制作包的时候,严格遵守 CommonJS 规范。
7.1.1 文件夹类型的模块
文件和模块一般是一一对应,文件可以是 JavaScript文件、JSON文件、二进制等,还可以是一个文件夹。最简单的包就是文件夹作为一个模块。例如:
新建一个 hello 的文件夹,并在 hello 文件夹下创建一个 index.js 文件,最后写入一下代码:
exports.hello = function() {
console.log("hello")
}
然后在 hello 的文件夹之外再创建一个 demo.js,写入一下代码:
var pkg = require("./hello");
pkg.hello();
我们运行 node demo.js 就会输出 hello。我们把这种文件夹封装成为一个模块,也就是包。包实际上就是许多模块的集合,类似于 C/C++ 的函数库。通过 package.json,我们就可以创建更复杂、更符合规范的包,并用于发布和下载安装。
7.1.2 package.json
package.json 是 Node.js 项目中的一个重要文件,用于描述项目的元数据信息和配置信息。它以 JSON(JavaScript Object Notation)格式书写,位于项目的根目录下。
{
"name": "myPackage",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}
package.json 文件包含了以下几个常用字段:
-
name:项目的名称,通常为小写字母、连字符或下划线组成的字符串。它在 npm 仓库中唯一标识一个包。
-
version:项目的版本号,通常采用
"主版本号.次版本号.修订号"的格式,例如:"1.0.0"。版本号的变化反映了项目的迭代更新。 -
description:项目的简短描述,用于介绍项目的特点和功能。
-
main:指定项目的入口文件,即在执行
require()函数时加载的模块。默认值为index.js。 -
scripts:定义了一组脚本命令,可以在命令行中使用
npm run <script>来执行。常见的脚本命令包括start、test等。例如,可以定义一个start脚本来启动应用程序,如"start": "node index.js"。 -
dependencies:列出了项目的生产环境依赖包及其版本号。当使用
npm install安装项目时,这些依赖包会自动下载和安装。 -
devDependencies:列出了项目的开发环境依赖包及其版本号。这些依赖包通常用于开发、测试和构建项目,不会在生产环境中使用。
-
keywords:关键字数组,用于描述项目的特点、功能或领域,便于搜索和分类。
-
author:项目的作者信息,可以是个人或组织的名称。
-
license:项目的许可证类型,用于定义其他人使用、修改和分发项目的规则。常见的许可证类型包括MIT、Apache-2.0等。
7.1.3 node_modules 目录
node_modules 目录通常是在 Node.js 项目中出现的一个文件夹,它用于存放项目依赖的第三方模块。当你使用 npm 或者 yarn 等包管理工具安装了某个 Node.js 模块时,这些模块会被下载并存放在 node_modules 目录下。
在 node_modules 目录中,每个安装的模块通常会有自己的文件夹,里面包含了该模块的代码文件、配置文件和其他必要的资源。这样做的好处是能够保持项目结构的清晰,并且方便地管理和维护依赖关系。
注意:
1. node_modules 目录是用来存放 Node.js 项目依赖的第三方模块的文件夹,它对于管理项目的依赖关系是非常重要的。
2. node_modules 目录非常容易变得庞大,因为项目可能会依赖很多第三方模块。为了避免在版本控制系统中提交过多的第三方模块代码,一般会将 node_modules 目录添加到 .gitignore 文件中,以防止将其提交到代码仓库中。
7.2 NPM包管理工具
NPM(Node Package Manager)是 Node.js 的包管理工具,用于安装、共享以及管理 Node.js 项目中的包依赖关系,你也可以使用 NPM 发布属于你自己的包。以下是关于 NPM 的详细介绍:
7.2.1 安装和使用:
-
NPM 是随同 Node.js 一起安装的,默认已经包含在 Node.js 的安装包中。
-
可以在命令行中执行各种 NPM 命令,如安装、升级、删除包等。
-
如果你不熟悉 NPM 命令,可以直接执行
npm或者是npm --help查看帮助引导说明。
7.2.2 包的安装和管理:
-
使用
npm install package-name命令可以安装指定的包。 -
包可以通过
-g选项进行全局安装,也可以在项目目录下安装本地包。 -
在项目的根目录下,可以通过
npm init命令来创建一个新的 Node.js 项目,并生成一个初始的package.json文件。 -
在
package.json文件中可以列出项目所依赖的其他包及其版本。通过npm install命令可以安装项目所依赖的所有包。 -
可以使用
npm update命令更新项目中的已安装包到最新版本。npm update package-name可以更新特定的包到最新版本。 -
通过
npm uninstall package-name命令可以从项目中删除指定的包。 -
通过
npm outdated检查哪些依赖项已经过时。 -
通过
npm search package-name可以搜索npm仓库中的特定包。 -
npm run package-name命令可以运行在package.json文件中定义的脚本。 -
npm test命令可以运行在package.json文件中定义的测试脚本。
本地安装
对于一些没有发布到 NPM 官方源上的包,或者是一些其他原因无法直接安装的包,可以将这些包下载到本地,然后使用本地安装。本地安装需要为 NPM 指定 package.json 文件所在的位置;这个 package.json 可以是一个带有 package.json 的归档文件,或者是一个URL地址,再或者是一个目录下带有 package.json 文件的目录位置。
# 通过package.json文件路径安装依赖包
npm install <file>
# 通过URL地址安装依赖包
npm install <url>
# 通过文件夹路径安装依赖包
npm install <folder>
非官方源安装
在安装依赖包的时候,还可以通过景象安装的方式进行安装,你只需要在后面加上 --registry=http://xxx 就可以安装非官方源的依赖包了。
npm install xxx --registry=http://xxx
7.2.3 NPM scripts:
-
package.json文件中的scripts字段允许开发者自定义一系列命令,用于在项目中执行各种脚本任务。 -
这些脚本任务可以通过
npm run script-name命令来运行。
7.2.4 版本管理:
-
NPM 使用语义化版本控制(Semantic Versioning)来管理包的版本。
-
在
package.json文件中,可以通过指定特定的版本范围来管理包的依赖关系。"dependencies": { "axios": "^1.3.4", }
7.2.5 搜索和浏览包:
-
可以使用
npm search package-name命令搜索 NPM 仓库中的包。 -
在 NPM 的网站上(https://www.npmjs.com/)也可以浏览和搜索各种 Node.js 包。
7.2.6 包的发布:
要发布一个 npm 包,你需要按照以下步骤进行操作:
-
创建
package.json文件:在你的项目根目录下,打开终端并运行npm init命令。按照提示填写项目的相关信息,比如包名称、版本、描述等,并确认生成的package.json文件。{ "name": "node-demo", // 包名,在NPM服务器上须要保持唯一 "version": "1.0.0", // 当前版本号 "dependencies": { // 三方包依赖,需要指定包名和版本号 "argv": "0.0.2" }, "main": "./lib/main.js", // 入口模块位置 "bin" : { "node-demo": "./bin/node-demo" // 命令行程序名和主模块位置 } } -
编写代码和测试:开发你的包,并确保它具备良好的功能和稳定性。同时,你也可以编写一些测试用例,以确保包在各种环境下都能正常工作。
-
注册
npm账号:如果你还没有npm账号,需要前往npm官网 注册一个账号。 -
登录
npm账号:在终端中运行npm login命令,然后输入你在上一步注册的npm账号的用户名、密码和邮箱。 -
构建包:在项目根目录下,确保你的代码和
package.json文件都已经准备好。运行npm publish命令,npm将会自动构建并发布你的包到npm仓库中。 -
验证发布结果:访问
https://www.npmjs.com/package/你的包名称检查你的包是否成功发布。你也可以运行npm info 你的包名称命令来检查包的详细信息。
请注意:发布 npm 包需要遵循一些规范和最佳实践。你可以查阅 npm 文档以获取更详细的发布指南和说明。
总结
NPM 不仅是一个工具,也是一个庞大的开源社区,其中有数以万计的开发者共享和贡献他们的包。通过 NPM,开发者可以方便地使用其他人的包,并且可以将自己的代码分享给全球开发者,促进了 Node.js 生态系统的繁荣和发展。
8-异步I/O
异步其实最先诞生于操作系统的底层,在底层系统中,异步通过信号量、消息等方式有广泛的应用。但在大多数高级编程语言中,异步并不多见,因为异步编程其实并不符合人的思维逻辑。异步其实早就已经诞生了,在Web 2.0的时候随着Ajax就已经在Web中变得非常流行了。前端技术员在Ajax技术产生就已经非常习惯异步应用场景了。
8.1 Node.js为什么需要异步I/O
异步I/O为什么在 Node.js 里如此重要,这其实与 Node.js 的网络设计有关,现在的Web应用已经不是以前的单一的服务器就能够胜任的,跨网并发已经是主流了,然而说到具体就要从下面两点说起:
8.1.1 用户体验
前端Web浏览器的处理UI和响应是处于停滞状态的,用户是不能进行其他任何操作的。如果浏览器的执行事件如果超过100毫秒,用户是会感觉到卡顿现象的,如果时间过长,用户就会认为网页已经停止了响应。只有后端能够足够快的处理响应资源,才能让前端UI和用户的体验变好。这也就是异步I/O为什么在 Node.js 为什么如此盛行。
8.1.2 资源分配
接下来我们从计算机资源分配的层面上来说一下异步 I/O 的重要性。计算机在发展过程中将组件抽象为 I/O 设备和计算机设备。假设有一组任务,现阶段的主流处理方式有以下两个:
-
单线程串行依次执行
同步执行时,就会造成阻塞,必须等待前一个任务结束,才能继续执行下一个任务。当然现在计算机在多核的情况下可以并行完成,但是同步会导致I/O的进行会让后续的任务阻塞等待,这使得计算机的资源不能被有效的利用起来。
-
多线程并发执行
在多线程下,操作系统会CPU的时间片分配给其他的线程继续执行,这也就使得多线程在多核CPU上能够有效的将资源利用起来。多线程并发其实也有一些弊端,多线程在创建和线程切换的时候开销比较大。如果创建线程的开销小如果小于并行执行那么多线程编程仍然是首选。如果在一些复杂的业务中,多线程还会有锁、状态同步等问题产生。
单线程同步编程会因为阻塞I/O导致系统的硬件资源不能被充分利用起来。而多线程也同样面临、锁、状态同步等诸多问题。
Node.js 已经在这两者之间给出了权衡利弊的方案;利用单线程可以避免多线程的锁和状态同步的问题。同时利用异步 I/O 也能让单线程远离阻塞,从而更好的利用系统资源。
为了弥补单线程无法利用多核CPU的问题,Node.js 还提供了类似前端浏览器的 Web Workers 的子进程,它可以充分高效的利用CPU和 I/O 等资源。
8.2 操作系统对异步I/O的支持
异步与非阻塞听起来好像是同一个意思,因为从实际效果而言它们都达到了我们并行 I/O 的目的。但是对于计算机内核 I/O 而言,它们又是另外一回事了。
8.2.1 I/O的阻塞与非阻塞
-
阻塞 I/O 是指程序在执行 I/O 操作时,会一直等待直到操作完成才返回结果。在阻塞 I/O 的情况下,当一个线程发起 I/O 请求后,它会一直等待直到 I/O 操作完成,期间无法进行其他操作,程序会停在那里,等待 I/O 操作完成。这种方式的缺点是会造成资源浪费,使得系统的并发性能受到影响。
-
非阻塞 I/O 指程序在执行 I/O 操作时,不会一直等待操作完成才返回结果。在非阻塞 I/O 的情况下,当一个线程发起 I/O 请求后,它会立即返回一个错误代码(比如 EAGAIN、EWOULDBLOCK),告诉调用者 I/O 操作尚未完成,然后该线程可以做其他事情,或者将控制权交给其他线程来处理其他任务。当 I/O 操作完成后,操作系统会通知程序,线程再次去读取数据。这种方式可以充分利用资源,提升系统的并发性能。
8.2.2 I/O的同步与异步
-
同步I/O 是指程序发起一个 I/O 请求后,需要等待直到请求完成并返回结果,期间程序会一直阻塞。在同步 I/O 的情况下,程序发送一个 I/O 请求后,会一直等待直到数据准备就绪并完成数据传输,期间程序处于阻塞状态,无法执行其他任务。这意味着程序必须等待 I/O 操作完成才能继续执行后续的任务。
-
异步 I/O 是指程序发起一个 I/O 请求后,不需要等待请求完成,可以立即执行其他任务。在异步 I/O 的情况下,程序发送一个 I/O 请求后,可以立即执行其他任务,不需要等待数据准备就绪或数据传输完成。当数据准备就绪或传输完成后,操作系统会通知程序,并处理相应的事件。
8.3 异步I/O与轮询技术
阻塞 I/O 会造成CPU的等待,而非阻塞 I/O 则会带来需要确认数据是否完全完成了获取的问题 (当进行非阻塞 I/O 操作时,也就需要读到完整的数据,那么程序就需要多次轮询,才能确保完整的读取数据。)。它会让CPU处理状态判断,造成CPU的资源浪费。下面就是现在常用的一些轮询技术:
-
read 是一个阻塞式 I/O 函数,用于从文件描述符中读取数据。当没有数据可读时,
read函数会一直阻塞等待,直到有数据到达或发生错误。如果需要进行非阻塞读取,可以使用O_NONBLOCK标志来设置文件描述符为非阻塞模式。它是最原始的,也是性能最低的一种方式,在得到数据以前,CPU资源一直用在了等待上。 -
select 是一种多路复用技术,用于监视多个文件描述符的状态,并在其中任何一个文件描述符准备好进行 I/O 操作时得到通知。通过调用
select函数,程序可以等待多个文件描述符中的任意一个变为可读或可写状态,从而实现非阻塞式 I/O 操作。但是select有性能瓶颈,因为它每次都要遍历所有监视的文件描述符。 -
poll 也是一种多路复用技术,类似于
select,主要不同在于poll是基于链表实现的,因此可以处理更多的文件描述符。poll 函数会等待所有指定的文件描述符中任意一个可读、可写或出现错误时返回。poll与select相比,对于大量文件描述符的情况,poll性能更优。 -
epoll 是
Linux 内核提供的一种 I/O 多路复用机制,是最新的轮询技术。与 select 和 poll 相比,epoll` 可以处理更多的并发连接,并且具有更好的性能、更低的延迟和更少的资源消耗。epoll 通过注册感兴趣的文件描述符来监视 I/O 事件,当事件发生时,系统会触发回调函数,通知程序进行相应的操作。 -
kqueue 是一种在 BSD 系统中广泛使用的高性能 I/O 事件通知机制,它提供了一种可扩展的、高效的事件通知接口,用于监视文件描述符上的事件,并在事件发生时通知应用程序。
kqueue主要用于实现高并发的 I/O 多路复用,特别适用于网络编程和服务器开发。
8.3.1 理想的非阻塞异步I/O
理想的非异步 I/O 是应用层调用异步方法后,直接进行下一个任务处理,然后等数据完整拿到以后再通过回调传递给程序,如下图所示:
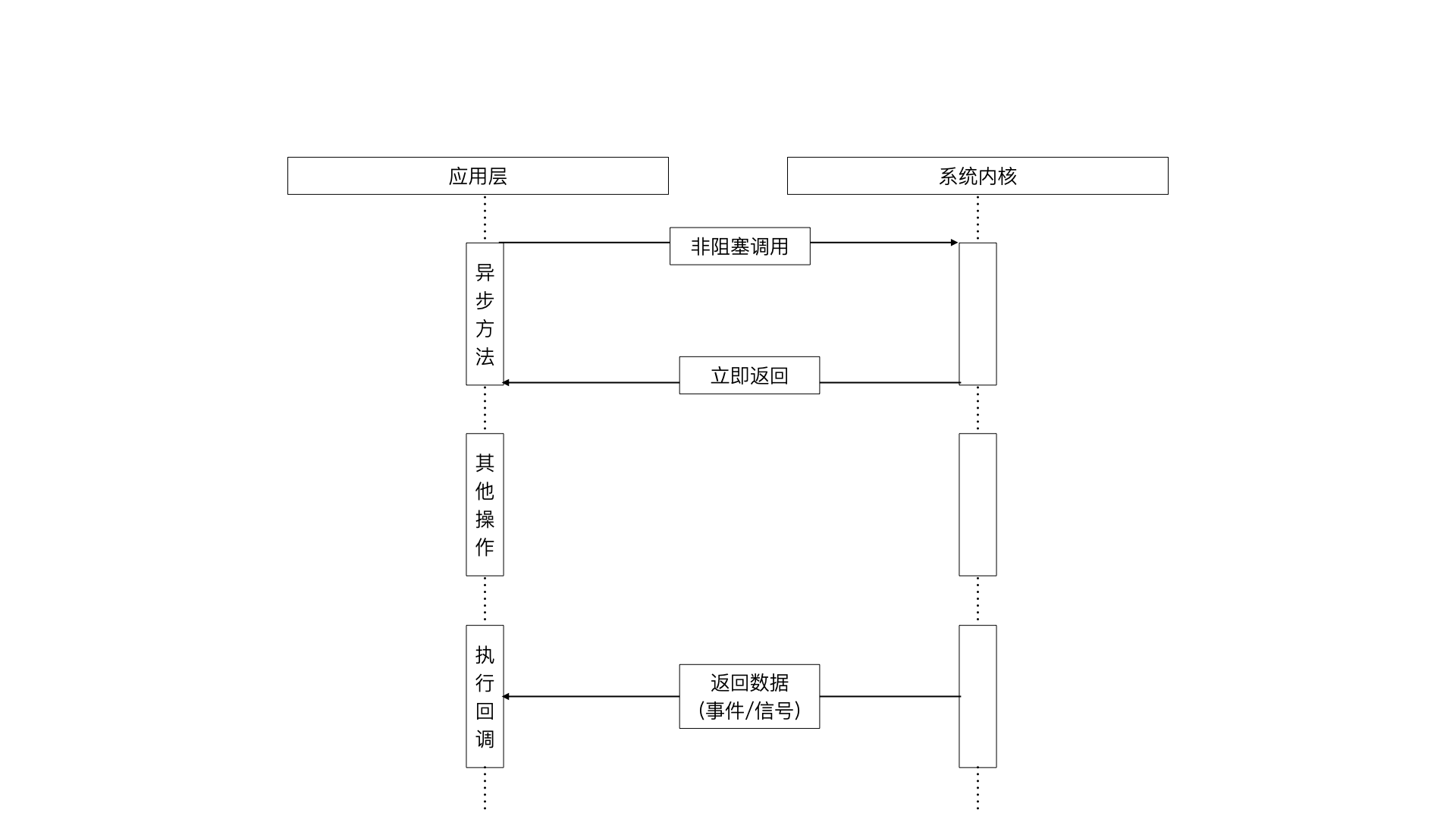
在 Linux 系统下确实存在这种方式,它原生提供了一种异步非阻塞异步 I/O 方式 (AIO)。AIO是通过信号或者回调来传递数据的。只不过仅仅只有 Linux 系统有这么一个方案,而且它还存在缺陷和BUG(AIO仅支持内核I/O中的O_DIRECT方式读取,从而导致应用程序无法利用系统缓存带来的性能优势。)。
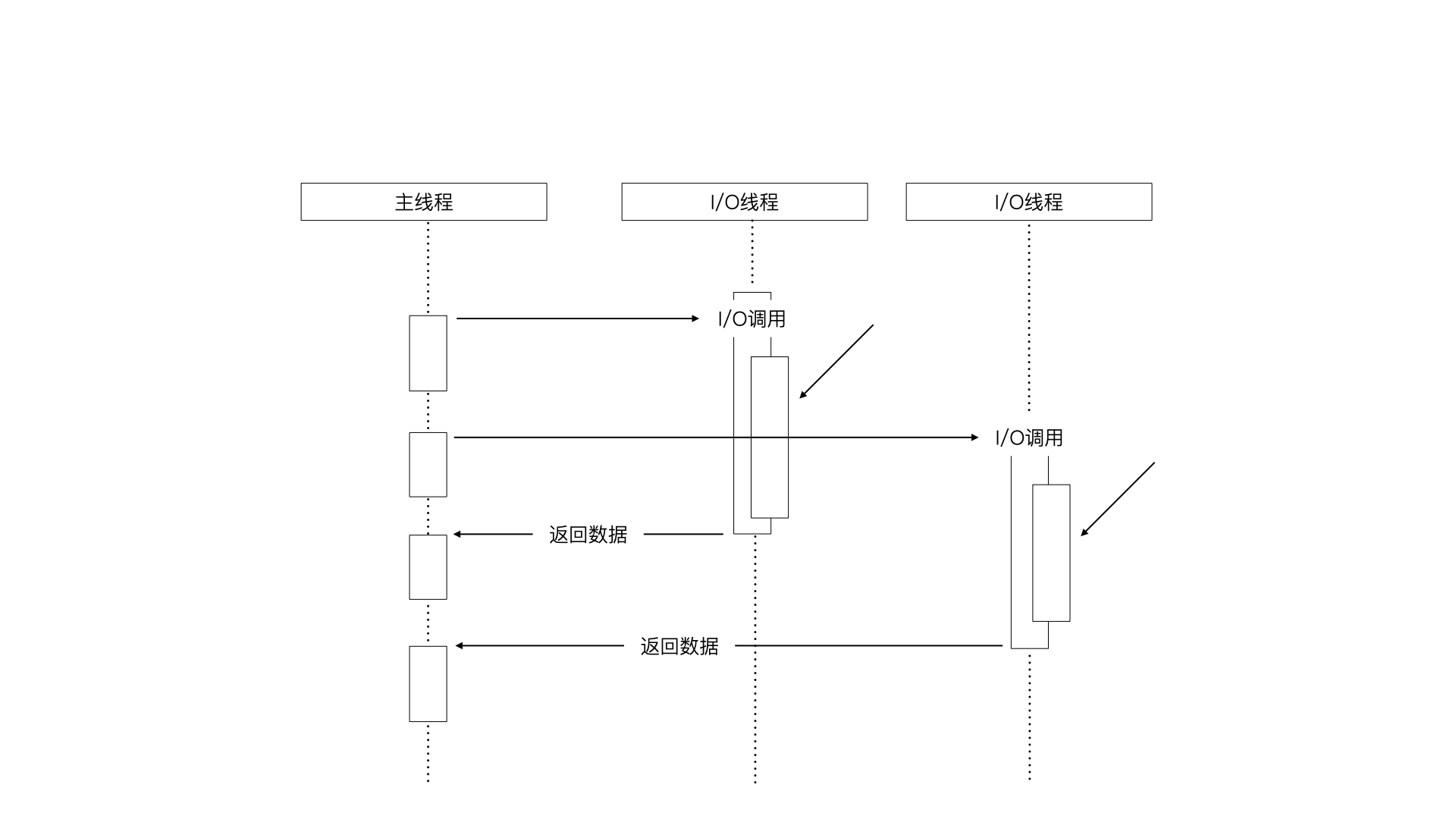
8.3.2 其他方式的异步I/O
还另一种异步 I/O 是采用多线程加阻塞 I/O,将 I/O 操作分到多个线程上,从而利用多线程之间的通信将 I/O 获得到的数据进行传递,这样也就实现了异步 I/O。如下图所示:
8.3.3 不同系统的异步I/O方案
在 Windows 系统中,主要使用 I/O 完成端口(I/O Completion Port)实现异步 I/O。它基于事件驱动的模型,通过将 I/O 操作请求关联到完成端口上,并在操作完成时通知应用程序,实现异步操作。IOCP的异步模型和Node的异步模型十分相似。
在 Linux 系统下采用了 libeio 配合 libve 的实现 I/O 部分,实现了异步 I/O。而在Node v0.9.3中,自行实现了线程池用来完成异步 I/O。
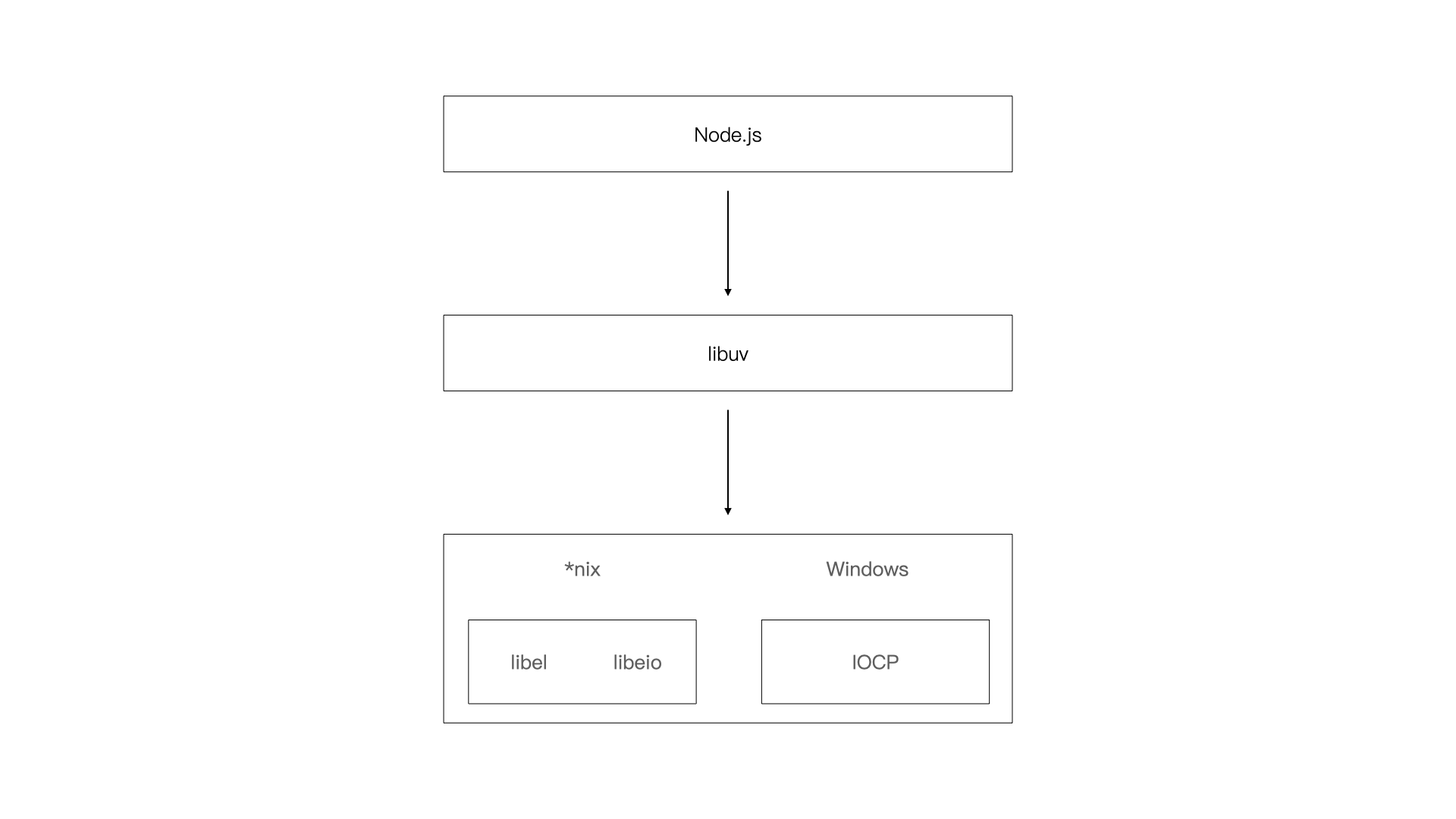
8.3.4 Node.js对于不同系统的兼容
由于各个系统之间对异步 I/O 都有不同的支持和实现,所以 Node.js 提供了 libuv 作为底层封装,这也使得不同的平台兼容性都能由这层来完成,这样保证 Node.js 和底层 libeio/libev 及 IOCP 之间各自独立。Node.js 会在编译期间判断操作系统平台,然后选择性的编译unix目录或是win目录下的源文件到目标程序中。
8.4 Node.js的异步I/O
上面我们介绍了操作系统对异步 I/O 的支持,下面我们将介绍 Node.js 如何实现异步 I/O。
8.4.1 事件循环 (Event Loop)
在 Node.js 中,事件驱动指的是程序通过注册事件处理函数,并等待事件的触发来执行相应的代码逻辑。Node.js 使用了事件循环机制,它会不断地检查事件队列中是否有事件需要处理,当有事件被触发时,相应的回调函数就会被调用。在程序启动的时候,Node 会创建一个类似于 while(true) 的循环,每执行一次循环体的过程就被称为 Tick。每个 Tick 的过程就是查看是否有事件需要处理,如果有,那就取出事件及其相关的回调函数(如果存在与之关联的回调函数那就去执行该回调函数。)。然后进入到下一个循环,如果不存在需要处理的事件,那么就退出进程。
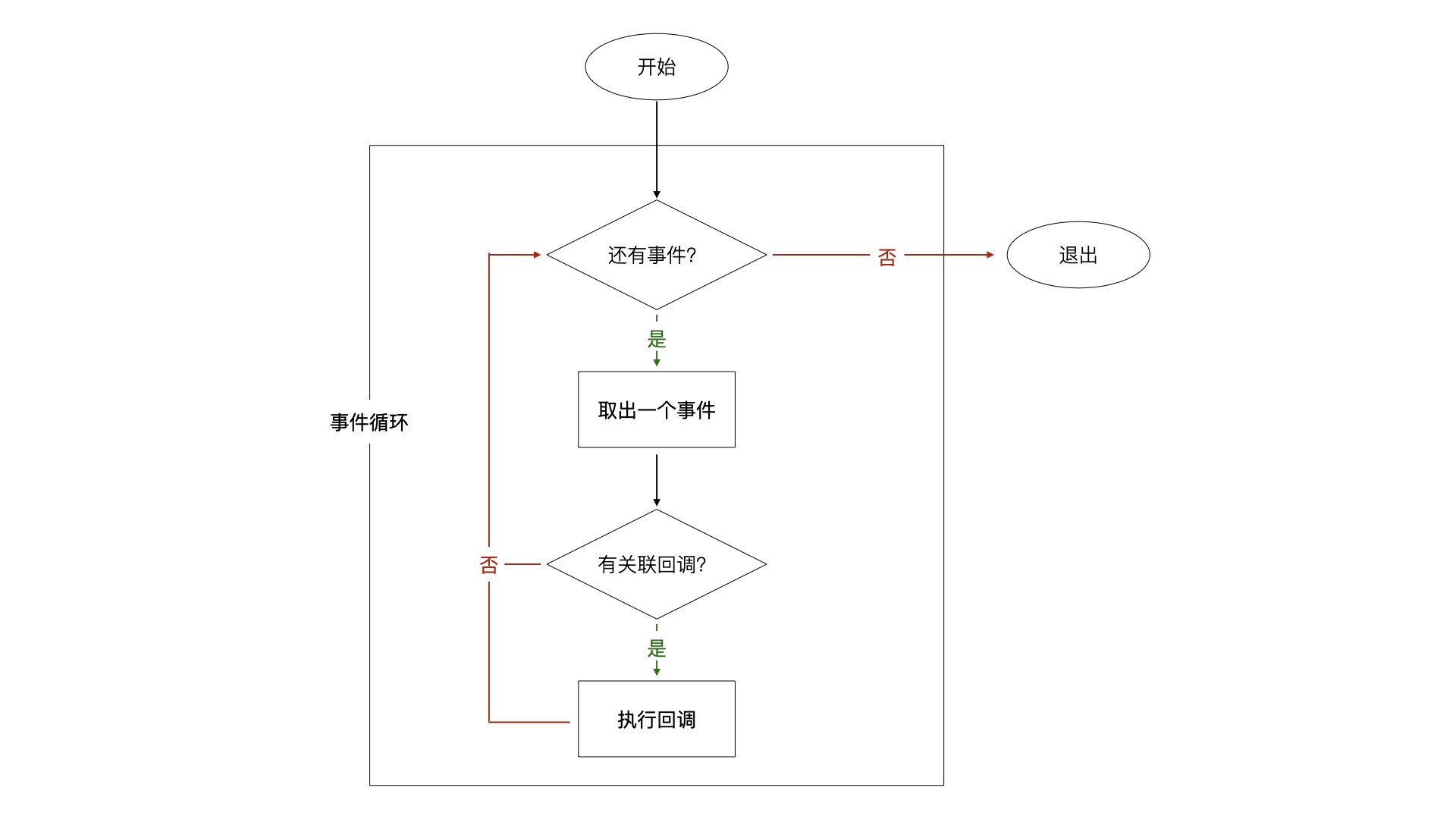
8.4.2 事件循环和观察者
像这种判断是否有事件需要处理的设计模式就是观察者模式。浏览器采用了类似的机制,事件可能来自用户的点击或者加载某些文件时产生,这些事件都有与之相对应的观察者。在 Node.js 中,事件主要来源于网络请求、文件 I/O 等。而这些事件与之的对应的观察者有网络 I/O 观察者和文件 I/O 观察者等,观察者也将事件进行了分类。
事件循环是一个典型的生产者和消费者模型,异步I/O和网络请求等相当于事件的生产者,源源不断地为Node提供不同类型的事件,这些事件最后被传递到对应的观察者那里,事件循环从观察者那里取出事件并处理。在Windows系统下这个循环是基于IOCP创建的,在*nix下是基于多线程创建的。
8.4.3 请求对象
普通的函数一般由开发者自己调用,回调函数则是由系统直接调用。我们发出了调用以后,再到回调函数执行,它们中间发生了什么?即从 JavaScript 发起调用到内核执行完 I/O 操作过程中,这中间的产物就是请求对象。
我们以一段代码为例,我看看看 Node.js 如何来对接这些操作系统从而实现异步 I/O:
const fs = require('fs');
fs.open('/msg.txt', function (err, data) {
console.log(data);
});
- JavaScript调用Node核心模块(fs.js)。
- Node核心模块调用C++的内建模块(node_file.cc),创建对应的文件I/O观察者对象。
- c++的内建模块通过Node的libuv根据不同的系统平台进行系统调用。

8.4.4 libuv调用过程
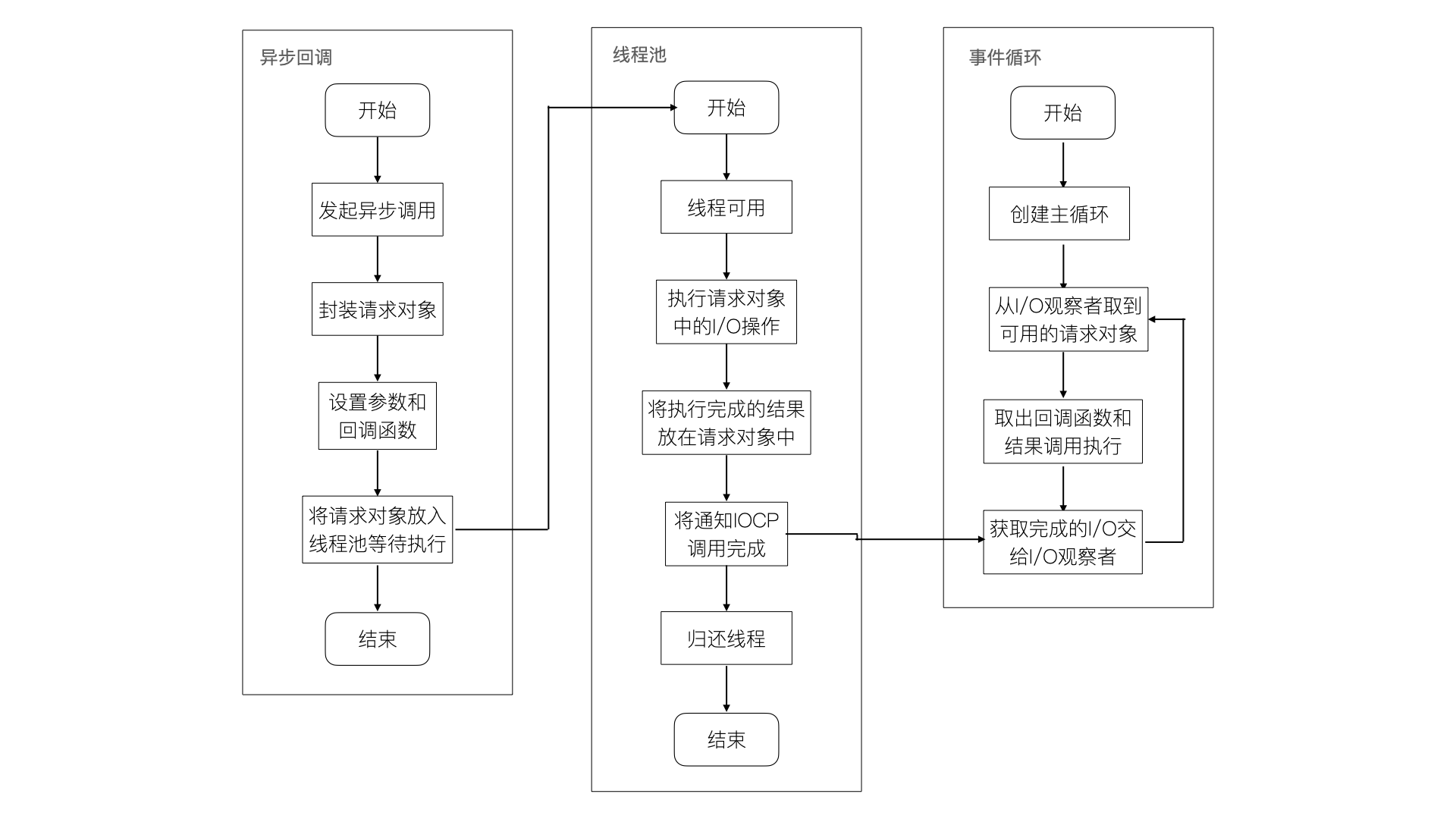
-
系统有 Windows 和 Linux 两个平台的实现,实际上是调用了这两个平台的
uv_fs_open()方法。在uv_fs_open()方法调用的时候,我们创建了一个FSReqWrap请求对象。从 JavaScript 层传入的参数和当前的方法都被封装在了这个请求对象中,其中的回调函数被设置在了对象的oncomplete_sym属性上。req_wrap -> object_ -> Set(oncomplete_sym, callback); -
对象包装完成以后,在 Windows 系统下,调用
QueueUserWorkItem()方法将FSReqWrap对象推入线程池中等待执行:QueueUserWorkItem(&uv_fs_thread_proc, req, WT_EXECUTEDEFAULT);参数说明:第一个参数是将要执行方法的引用(uv_fs_thread_proc),第二个参数是第一个
uv_fs_thread_proc方法运行时所需要的参数,第三个参数是执行标志。
到目前为止,JavaScript 的调用就直接返回了,我们的 JavaScript 代码继续往下执行,当前的 I/O 操作同时也会被放在线程池中执行,这也就完成了异步。
8.4.5 执行回调
封装好请求对象,放入 I/O 线程等待操作系统执行才是开始,接下来是通知回调。线程池中的 I/O 操作完毕后,会将获取到的结果存储到 req->result 属性上,然后调用 PostQueuedCompletionStatus() 通知IOCP,告知当前对象操作已经完成。
PostQueuedCompletionStatus((loop)->iocp, 0, 0, &(req)->overlapped)
每一个 Tick 当中都会调用 PostQueuedCompletionStatus 检查线程池中是否有执行完成的请求,如果有就会将请求对象加入到 I/O 观察者的队列上,然后再将它当作事件处理。PostQueuedCompletionStatus 的作用就是向IOCP提交状态,告诉它当前 I/O 已经完成了。
I/O 观察者回调函数的行为就是取出请求对象的result属性作为参数,取出 oncomplete_sym 作为方法,然后调用并执行,从而达到调用 JavaScript 中传入的回调函数的目的,至此也就完成了整 个I/O 过程。
Linux 则是通过epoll实现这个过程,FreeBSD则是通过kqueue实现,*nix系列下是由libuv自行实现的,只不过线程池是在Windows下由内核(IOCP)直接提供。
事件循环、观察者、请其对象、I/O线程池共同构成了异步I/O模型,JavaScript 是单线程的,而 Node.js 本身是多线程的,只不过I/O线程使用的CPU资源较少。还有一个需要知道的就是,除了用户代码无法并行执行以外,所有的I/O(磁盘I/O和网络I/O等)都是可以并行执行的。
8.5 Node.js中非I/O的异步API
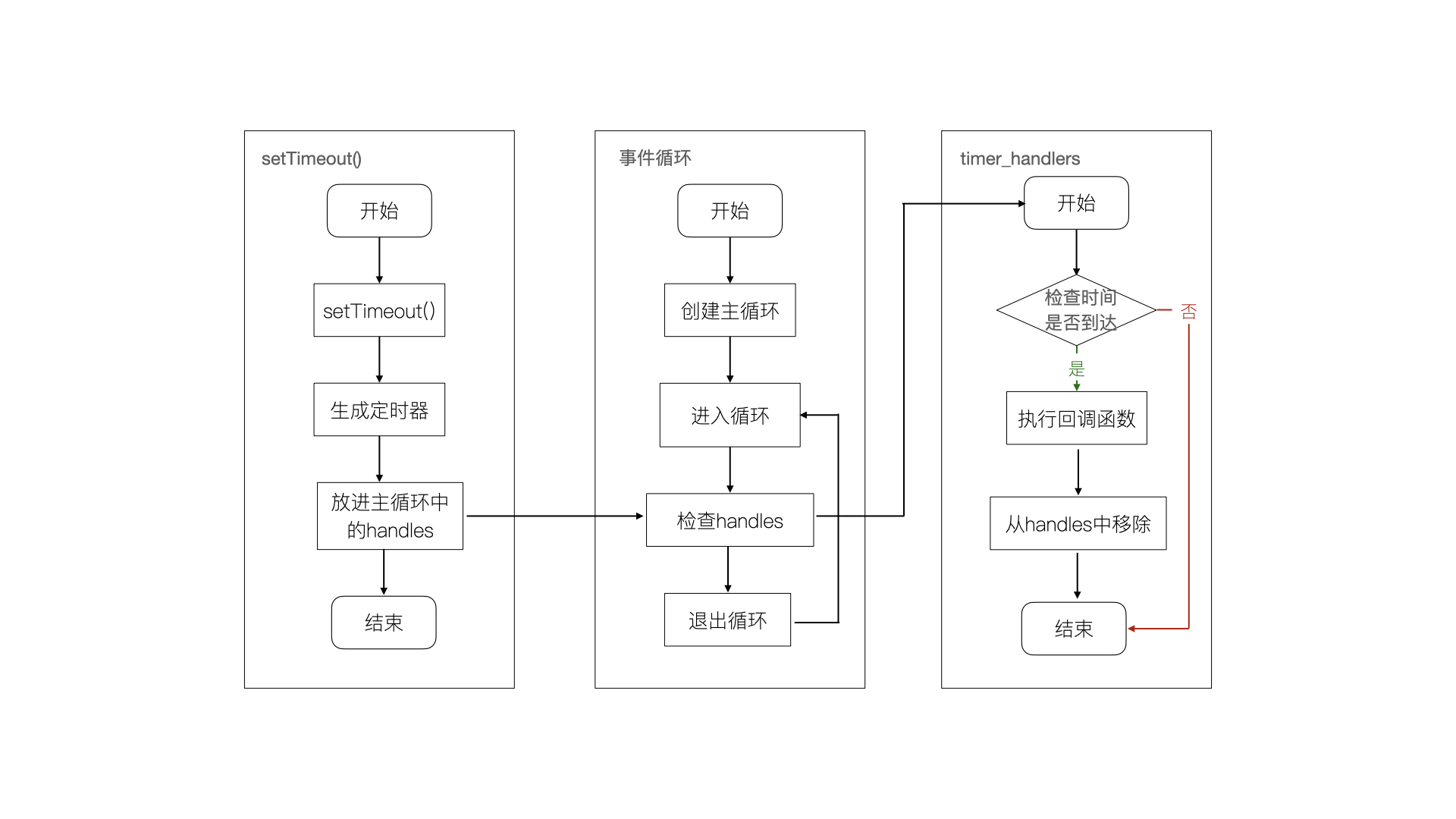
除了异步 I/O 以外,Node.js 中还存在一些与 I/O 无关的异步API,它们是设置超时定时器 setTimeout()、设置间隔定时器 setInterval()、设置马上执行定时器 setImmediate() 和 process.nextTick()。
setTimeout() 和 setInterval() 这两个函数和浏览器中的API是一样的,setTimeout() 执行单次任务,而 setInterval() 执行多次任务。这些函数的原理和异步I/O相类似,不同的是不需要线程池的参与,调用setTimeout() 和 setInterval() 这两个函数创建的定时器会被插入到定时器观察者内部的红黑树中去,每次执行Tick,都会从这个红黑树中迭代取出对应的定时器对象。setTimeout()函数的行为和 setInterval() 相类似,只不过 setInterval() 是重复的检测和执行。下面是 setTimeout() 行为的图示:
8.5.1 process.nextTick()
一般情况下使用异步都会想到 setTimeout() 这个函数,不过由于事件循环自身的特点,因此定时器的精确度不够。使用定时器需要使用红黑树,创建定时器对象并迭代,setTimeout()的方式就显得性能浪费了。而 process.nextTick() 的操作就显得非常轻量。
process.nextTick() 方法可以将回调函数放入微任务队列,等待当前阶段结束后立即执行。它的执行优先级比 setImmediate() 更高,会在下一个阶段之前立即执行。
process.nextTick = function(callback) {
// on the way out, don't bother.
// it won't get fired anyway
if (process._exiting) {
return;
}
if (tickDepth >= process.maxTickDepth) {
maxTickWarn();
}
var tock = { callback: callback };
if (process.domain) {
tock.domain = process.domain;
}
nextTickQueue.push(tock);
if (nextTickQueue.length) {
process._needTickCallback();
}
};
需要注意的是,process.nextTick() 的回调函数会在当前阶段中被递归调用,直到队列为空为止。因此,如果回调函数没有限制递归深度或者执行时间,可能会导致事件循环无法及时处理其他任务。
8.5.2 setImmediate()
setImmediate() 方法会将回调函数放入事件队列,等待下一轮事件循环执行。它的执行优先级较低,会在 I/O 操作和定时器之后执行。setImmediate() 和 process.nextTick() 比较相似,在 Node.js v0.9.1之前setImmediate()还没有实现以前,都是使用 process.nextTick() 来完成异步的。
console.log('Start');
setImmediate(() => {
console.log('Callback of setImmediate');
});
console.log('End');
但是,两者还是存在细微差别,process.nextTick() 的优先级会高一些,我们看一下示例代码:
setImmediate(() => {
console.log('Callback of setImmediate');
});
process.nextTick(() => {
console.log("Callback of nextTick")
})
使用 setImmediate() 可以避免某些情况下的死锁,例如递归调用一个函数或者在一个 I/O 操作的回调函数中再次发起 I/O 操作。在这种情况下,如果使用 setTimeout() 来调度回调函数,可能会因为定时器过早触发而导致死锁。
8.6 事件驱动与高性能服务器
Node.js 的异步 I/O 不只是用在了文件 I/O,还包括网络套接字,网络套接字上侦听到的请求都会形成事件,然后交给 I/O 观察者。事件循环会不停的处理这些网络 I/O 事件。利用 Node.js 构建的Web服务器就是建立在这样的基础之上,其设计理念和实现方式都与传统的多线程服务器模型有所不同。Node.js 的事件驱动机制和高性能服务器实现方式都基于非阻塞式的编程模型和异步 I/O 操作,在处理高并发、高吞吐量的网络应用和服务时具有较好的性能优势。
总结
Node.js 的异步 I/O 是通过libuv库实现的,它采用了非阻塞、事件驱动的模型来处理 I/O 操作。下面是对 Node.js 异步 I/O 的总结:
-
非阻塞:Node.js 使用异步 I/O 模型,使得在进行 I/O 操作时不会阻塞主线程或其他任务,提高程序的性能和响应能力。
-
libuv库:Node.js 的异步 I/O 功能是由libuv库提供的,它负责管理 I/O 线程池、事件循环和事件队列等。
-
事件驱动:异步 I/O 操作是通过事件驱动的方式进行的。当一个异步操作完成时,libuv会将结果保存起来,并将相应的回调函数添加到事件队列中,等待事件循环处理。
-
回调函数:在 Node.js 中,回调函数是处理异步操作结果的常用方式。当异步操作完成后,事件循环会调用相应的回调函数,并将操作结果传递给它。
-
异步控制流:为了处理多个异步操作的执行顺序和结果依赖关系,Node.js 提供了一些流程控制的工具,如回调嵌套、事件发布/订阅、Promise、async/await等。。
-
错误处理:在异步 I/O 中,错误处理尤为重要。Node.js 提供了一些机制来处理和捕获异步操作中的错误,如使用try-catch捕获异常、传递错误给回调函数等。
Node.js 的异步I/O模型使得它适合处理高并发的网络请求、实时数据处理等场景。通过合理地利用异步 I/O,开发者可以编写出高性能、高效率的 Node.js 应用程序。但同时,也需要注意回调地狱、错误处理等问题,以保证代码的可读性和稳定性。
9-事件
Node.js 采用基于事件驱动的非阻塞 I/O 模型,实现高效的异步编程。Node.js 的事件模块(events)是一个核心模块,它提供了一些用于处理事件的基本工具。
Node.js 中的事件模块(events)是指 EventEmitter 类,它是 Node.js 核心模块 events 的一部分。事件模块提供了一种基于观察者模式的事件驱动编程机制,允许开发者轻松地创建、触发和监听事件,并在事件发生时执行相应的回调函数。
9.1 EventEmitter 类
在事件模块中,EventEmitter 类是核心部分。它提供了多个方法来注册、触发和处理事件。
Node.js 的事件模块广泛应用于实现各种功能,包括网络编程(如 HTTP 服务器和客户端)、文件系统操作、消息队列、用户界面交互等。通过使用 EventEmitter 类,开发者可以实现高效的异步编程,同时保持代码简洁和可维护性。
下面是 EventEmitter 类的一些常见的方法(event表示事件字符串,listener事件处理函数,中括号里面的参数是可选的。):
| 方法 | 描述 |
|---|---|
| addListener(event, listener) | 对指定的事件绑定事件处理函数(监听器),接受event字符串和listener回调函数。 |
| on(event, listener) | 对指定的事件注册一个监听函数。 |
| once(event, listener) | 对指定的事件绑定一个只执行一次的函数。 |
| removeListener(event, listener) | 对指定的事件移除绑定的事件处理函数。 |
| removeAllListener(event, listener) | 对指定的事件移除所有事件处理函数。 |
| setMaxListeners(n) | 指定事件处理函数的最大数量,n为整数。 |
| lsteners(n) | 获取指定事件的所有事件处理函数。 |
| emit(event, [arg1], [arg2], […]) | 按照参数的顺序执行每个处理函数,如果有注册监听返回true,否则返回false。 |
9.1.1 创建 EventEmitter 实例
要使用事件模块,首先需要引入 events 模块,并创建一个 EventEmitter 实例:
const EventEmitter = require('events');
// 这将创建一个名为 emitter 的 EventEmitter 实例。
const emitter = new EventEmitter();
9.1.2 注册事件监听器
可以使用 on() 方法或 addListener() 方法来注册事件监听器,以便在特定事件发生时执行相应的回调函数。
emitter.on('eventName', (arg1, arg2) => {
// 处理事件
});
在上面的代码中,当 eventName 事件被触发时,注册的回调函数将被执行。
9.1.3 触发事件
使用 emit() 方法来触发特定的事件,并传递参数给注册的事件监听器。
emitter.emit('eventName', arg1, arg2);
在上面的代码中,emit() 方法将触发名为 eventName 的事件,并将 arg1 和 arg2 作为参数传递给事件监听器。
9.1.4 一次性监听事件
除了 on() 方法之外,还可以使用 once() 方法一次性监听事件。这意味着事件只会被触发一次,而不是每次事件发生时都触发。
emitter.once('eventName', () => {
// 处理事件
});
9.1.5 错误处理
EventEmitter 类还包含了处理错误的能力。当没有为 'error' 事件注册监听器时,EventEmitter 将会打印堆栈跟踪并退出程序。为了避免这种情况,建议始终为 'error' 事件注册至少一个监听器。
emitter.on('error', (err) => {
console.error('Error occurred:', err);
});
9.2 继承 EventEmitter
通常情况下,我们都是在对象中去继承 EventEmitter,包括 fs、net、 http 在内的支持事件响应的核心模块都是 EventEmitter 的子类。这是因为具有某个实体功能的对象实现事件符合语义,事件的监听和发生应该是一个对象的方法。再就是 JavaScript 的对象机制是基于原型的,支持部分多重继承,继承 EventEmitter 并不会打乱对象原有的继承关系。
总结
Node.js 的事件模型使得开发者可以基于事件驱动的方式编写高效的、非阻塞的程序。通过 EventEmitter,我们可以很方便地监听各种事件,当事件发生时,执行相应的代码逻辑,从而实现异步编程。
10-异步编程
Node.js 的异步编程是其高性能和高并发的关键。在 Node.js 中,异步编程采用了一系列机制,包括 回调函数、事件循环、Promise 和 async/await 等。下面将对这些机制进行详细介绍。
10.1 回调函数
回调函数是 Node.js 异步编程模型的核心。当一个异步操作完成时,会触发相应的事件,并执行对应的回调函数来处理事件。通过回调函数,我们可以在异步 I/O 操作完成后继续执行程序,而不必等待 I/O 操作完成。
例如,下面的代码演示了使用回调函数处理异步文件读取操作:
const fs = require('fs');
fs.readFile('/Users/ydcq/Desktop/msg.txt', function(err, data) {
if (err) {
throw err;
}
console.log(data);
});
readFile 方法是一个异步方法,它会读取指定路径下的文件,然后触发一个读取完成的事件。当读取完成事件被触发时,回调函数会被执行,并打印出文件内容。
readFile 就是一个典型的高阶函数,将回调函数作为参数传递给 readFile。随着业务逻辑的增加,这种传入回调的方式也存在着很大的弊端,例如下面这样:
const fs = require('fs');
fs.readFile('1.json', (err, data) => {
fs.readFile("2.json", (err, data) => {
fs.readFile('3.json', (err, data) => {
fs.readFile('3.json', (err, data) => {
console.log("data=", data);
}
}
}
}
像这种回调当中嵌套回调,也被称为 回调地狱,这种代码无论是可读性和维护性都是很差的。嵌套回调的层级太多还会导致这里面如果有失败都需要单独为每一个任务去处理,这样也就大大增加了代码的混乱程度。
10.2 事件发布/订阅模式
Node.js 的异步 I/O 操作,都会发送一个事件到时间队列中,当一个操作发起时,在事件驱动模型中会生成一个主循环来监听事件,当检测到事件后,会触发回调函数,如下图所示:
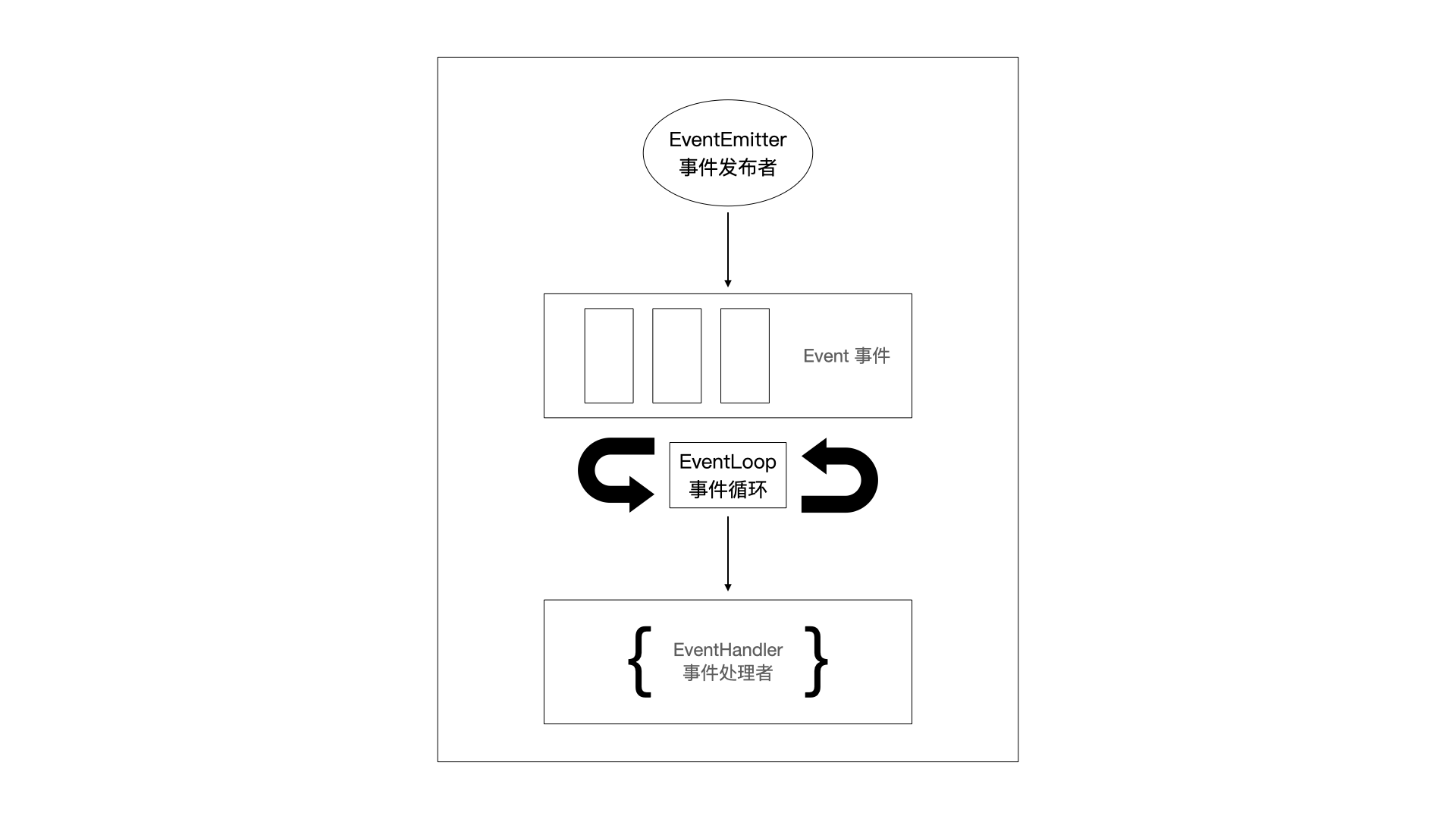
事件监听器模式是一种广泛用于异步编程的模式,它是函数回调的事件化,也被称为事件的发布/订阅模式。Node.js 的 events 模块其实就是发布/订阅模式的一个实现。
const EventEmitter = require('events');
// 创建一个名为 emitter 的 EventEmitter 实例
const emitter = new EventEmitter();
// 订阅
emitter.on('event', () => {
// 绑定事件
console.log("绑定事件event")
})
emitter.addListener('click', () => {
// 监听事件
console.log("监听click事件")
})
// 发布
emitter.emit('event'); // 提交事件
emitter.emit('click'); // 提交事件
通过上述步骤,我们可以实现模块之间的松散耦合,让不同的模块可以独立地定义和响应事件。事件发射器提供了一种简单而有效的方式来实现模块之间的通信,使得代码的组织和维护更加灵活和可扩展。Node.js 的事件发布/订阅模式为开发者提供了一种高效、灵活的编程范式,可以在异步环境中实现模块间的通信和协作。
10.3 Promise
Promise 是一种用于处理异步操作的编程模型,它可以将回调函数转换为链式调用的方式。Promise 可以通过 then 方法实现链式调用,从而使得代码更为简洁和易于维护。同时,Promise 还支持多个异步操作的并行处理和串行依赖关系的处理。
例如,下面的代码演示了使用 Promise 处理异步文件读取操作:
const fs = require('fs').promises;
fs.readFile('/Users/ydcq/Desktop/msg.txt')
.then(data => {
console.log(data);
})
.catch(err => {
console.error(err);
});
在上面的代码中,readFile 方法返回一个 Promise 对象。当 Promise 对象的状态变为 resolved 时,then 方法会被执行,并打印出文件内容。当 Promise 对象的状态变为 rejected 时,catch 方法会被执行,并打印出错误信息。
Promise 的链式调用在很大程度上避免了大量的嵌套带来的问题,也更加的复合人的思维逻辑,大大的方便了异步编程。
10.4 async/await
async/await 是 ES2017 中引入的新特性,它是一种基于 Promise 的异步编程模型。async/await 可以将异步操作的链式调用转换为顺序执行的方式,从而使得代码更为简洁和易于理解。同时,async/await 还支持多个异步操作的并行处理和串行依赖关系的处理。
async function readFile() {
try {
const data = await fs.readFile('/Users/ydcq/Desktop/msg.txt');
console.log(data);
} catch (err) {
console.error(err);
}
}
readFile();
readFile 方法定义为一个异步函数。在函数内部,使用 await 关键字等待 readFile 方法返回的 Promise 对象。当 Promise 对象的状态变为 resolved 时,await 表达式会返回 Promise 对象的结果,并将其赋值给变量 data。当 Promise 对象的状态变为 rejected 时,try-catch 语句会捕获错误并打印出错误信息。
async/await 使得异步代码也能够以同步的方式去编写,更加不需要借助第三方库来实现。
10.5 Generator
在 Node.js 中,Generator 是一种特殊的函数,它可以暂停和恢复执行,使得异步编程变得更加简洁和可读。通过使用 Generator,我们可以使用同步的方式编写异步代码,避免回调地狱和复杂的 Promise 链式调用。
下面是使用 Generator 实现异步编程的基本流程:
- 定义 Generator 函数:
function* asyncFunction() {
// 异步操作1
yield someAsyncOperation1();
// 异步操作2
yield someAsyncOperation2();
// ...
}
- 获取 Generator 对象:
const generator = asyncFunction();
- 执行 Generator 函数并获取结果:
const iterator = generator.next();
if (!iterator.done) {
// 异步操作的回调函数中通过调用 iterator.next() 恢复 Generator 的执行
iterator.value.then(() => {
generator.next();
});
}
- 重复执行步骤3,直到 Generator 函数执行完毕:
function run(generator) {
let iterator = generator.next();
function iterate(iterator) {
if (!iterator.done) {
iterator.value.then(() => {
iterate(generator.next());
});
}
}
iterate(iterator);
}
run(generator);
通过以上步骤,我们可以使用 Generator 和 yield 关键字来暂停和恢复异步操作的执行。当异步操作完成时,通过调用 iterator.next() 继续执行 Generator 函数中的下一步操作,从而实现了异步编程的简洁性和可读性。
需要注意的是,上述代码是基本的 Generator 实现异步编程的流程,为了提高代码的可读性和可维护性,通常会结合使用 Promise、async/await 等语法糖来更加方便地处理异步操作。
Node.js 的 Generator 提供了一种优雅的方式来处理异步编程,通过使用 yield 关键字暂停和恢复执行,可以让异步代码更加简洁和可读。然而,由于 Generator 的使用需要手动管理迭代器和回调函数,所以在实际开发中,一般会使用 async/await 或 Promise 等更加方便的异步编程方式。
总结
Node.js 的异步编程模型使得开发者能够高效地处理大量并发请求,避免阻塞和等待,提高系统的并发能力和响应性。开发者可以使用回调函数、Promise、Async/Await、事件触发器等方式来处理异步操作,从而实现更加简单、清晰和易于维护的异步代码。
11-util
util 是 Node.js 标准库中的一个内置模块,它提供了一些常用的工具函数和类,用于简化常见的 JavaScript 编程任务。这些函数包括格式化字符串、错误处理、对象检查等。下面是对 util 模块的一些详细介绍:
11.1 继承(Inheritance)
在 Node.js 中,util 模块提供了一些实用工具函数,其中包括用于继承的函数。
util.inherits(child, parent)
该方法用于实现对象之间的继承关系。它将子类的原型设置为父类的一个实例,从而实现了子类继承父类的属性和方法。
const util = require('util');
function Animal(name) {
this.name = name;
}
Animal.prototype.walk = function() {
console.log(this.name + ' is walking...');
};
function Bird(name) {
Animal.call(this, name);
}
util.inherits(Bird, Animal);
Bird.prototype.fly = function() {
console.log(this.name + ' is flying...');
};
let bird = new Bird('Sparrow');
bird.walk(); // output: Sparrow is walking...
bird.fly(); // output: Sparrow is flying...
11.2 类型判断(Type Checking
-
util.isPrimitive(input): 判断给定的值是否为原始类型(字符串、数字、布尔值、null 或 undefined)。
-
util.isArray(input): 判断给定的值是否为数组。
-
util.isDate(input): 判断给定的值是否为日期对象。
-
util.isError(input): 判断给定的值是否为错误对象。
const util = require('util');
console.log(util.isPrimitive('hello')); // true
console.log(util.isPrimitive(10)); // true
console.log(util.isPrimitive(true)); // true
console.log(util.isPrimitive(null)); // true
console.log(util.isPrimitive(undefined)); // true
console.log(util.isArray([1, 2, 3])); // true
console.log(util.isDate(new Date())); // true
console.log(util.isError(new Error('Something went wrong'))); // true
11.3 错误处理(Error Handling)
-
util.format(format, […args]): 根据指定的格式字符串和参数生成一个格式化的字符串。
-
util.inspect(object, [options]): 将给定的对象转换为字符串表示形式,用于调试目的。可以通过传递选项参数来自定义输出格式。
const util = require('util');
let name = 'John';
let age = 25;
console.log(util.format('My name is %s and I am %d years old', name, age));
// output: My name is John and I am 25 years old
class Person {
constructor(name, age) {
this.name = name;
this.age = age;
}
}
let person = new Person('John', 25);
console.log(util.inspect(person));
/* output:
Person {
name: 'John',
age: 25
}
*/
11.4 修饰器(Decorators)
- util.deprecate(function, warning): 返回一个包装后的函数,当该函数被调用时会发出警告。常用于标记已废弃的函数,提醒开发人员不要再使用。
const util = require('util');
function deprecatedFunction() {
console.log('This function is deprecated and will be removed in future versions');
}
let wrappedFunction = util.deprecate(deprecatedFunction, 'This function is deprecated');
wrappedFunction();
// output: This function is deprecated and will be removed in future versions
// (node:1234) DeprecationWarning: This function is deprecated
11.5 事件触发器(Event Emitter)
-
util.promisify(original): 将基于回调的异步函数转换为返回 Promise 的形式,方便使用 async/await 处理异步操作。
const util = require('util'); const fs = require('fs'); let readFileAsync = util.promisify(fs.readFile); async function readFile() { let data = await readFileAsync('file.txt', 'utf8'); console.log(data); } readFile(); // output: contents of file.txt
11.6 工具函数(Utility Functions)
-
util.format(format[, …args]):
util.format()方法根据指定的格式字符串返回格式化后的字符串。const util = require('util'); const formattedString = util.format('%s is %d years old', 'Alice', 30); console.log(formattedString); // 输出:'Alice is 30 years old' -
util.promisify(original):
util.promisify()方法用于将符合 Node.js 回调风格的函数(即以回调作为最后一个参数的函数)转换为基于 Promise 的函数。const util = require('util'); const fs = require('fs'); const readFileAsync = util.promisify(fs.readFile); readFileAsync('example.txt', 'utf8') .then(data => { console.log(data); }) .catch(err => { console.error(err); }); -
util.inspect(object, [options]):
util.inspect()方法返回对象的字符串表示,通常用于调试和日志输出。const util = require('util'); const obj = { name: 'John', age: 25 }; console.log(util.inspect(obj, { showHidden: true, depth: null })); // 输出对象的详细信息,包括隐藏属性和深度遍历所有属性 -
util.inherits(constructor, superConstructor):
util.inherits()方法用于实现对象间原型继承。const util = require('util'); function Animal(name) { this.name = name; } function Dog(name) { Animal.call(this, name); } util.inherits(Dog, Animal); -
util.deprecate(fn, message):
util.deprecate()方法接受两个参数:待标记为废弃的函数(或方法)和发出的警告消息。它返回一个新的函数,当调用该函数时,会打印警告消息。const util = require('util'); function oldMethod() { console.log('This method is deprecated. Please use the newMethod instead.'); } const deprecatedMethod = util.deprecate(oldMethod, 'oldMethod is deprecated.'); deprecatedMethod(); // 调用被标记为废弃的函数 // 输出警告消息: //This method is deprecated. Please use the newMethod instead. //(node:3282) DeprecationWarning: oldMethod is deprecated. //(Use `node --trace-deprecation ...` to show where the warning was created)
11.7 其他方法
-
callbackify:util.callbackify 方法可以将返回 Promise 的函数转换为基于回调的函数。这在与旧的回调风格代码交互时非常有用。
-
TextEncoder 和 TextDecoder:util 中的 TextEncoder 和 TextDecoder 类是用于处理文本编码和解码的工具类。它们提供了将字符串转换为字节数组(或反之)的功能。
这些只是 util 模块提供的一些常用方法和工具函数,还有其他一些函数和类可以在 Node.js 的文档中找到。
总结
Node.js 的 util 模块提供了一系列实用工具函数,用于扩展 Node.js 核心API的功能,以及简化开发过程。util 模块中包含了许多用于操作对象、处理数据和其他常见任务的函数和类。通过 util 模块,开发者可以更加便利地进行对象操作、错误处理、类型判断和格式化输出等常见任务,提高开发效率,减少重复工作。
12-文件系统 fs
fs(文件系统)模块是 Node.js 中用于进行文件系统操作的核心模块之一。它提供了许多方法来读取、写入、修改和删除文件,以及创建、删除和遍历目录等功能。下面将详细介绍 fs 模块的一些常见功能:
12.1 打开文件
fs.open(path, flags, [mode], callback) 方法用于在文件系统中打开文件。它接受文件路径和标志作为参数,并返回一个文件描述符(file descriptor)。
参数说明:
- path:要打开的文件的路径。
- flags:指定文件的打开方式,可以是以下之一:
- ‘r’:读取模式,文件不存在则抛出错误。
- ‘r+’:读写模式,文件不存在则抛出错误。
- ‘rs’:同步读取模式,文件不存在则抛出错误。
- ‘rs+’:同步读写模式,文件不存在则抛出错误。
- ‘w’:写入模式,文件不存在则创建文件。
- ‘wx’:排他写入模式,文件不存在则创建文件,存在则抛出错误。
- ‘w+’:读写模式,文件不存在则创建文件。
- ‘wx+’:排他读写模式,文件不存在则创建文件,存在则抛出错误。
- ‘a’:追加写入模式,文件不存在则创建文件。
- ‘ax’:排他追加写入模式,文件不存在则创建文件,存在则抛出错误。
- ‘a+’:读取追加写入模式,文件不存在则创建文件。
- ‘ax+’:排他读取追加写入模式,文件不存在则创建文件,存在则抛出错误。
- mode(可选):指定文件的权限,默认为
0o666。 - callback:回调函数,接收两个参数 (err, fd),其中
fd是文件描述符。
下面是一个打开文件的示例代码:
const fs = require('fs');
fs.open('/path/to/file.txt', 'r', (err, fd) => {
if (err) {
console.error(err);
return;
}
// 文件已打开,可以进行操作
console.log(`文件已打开,文件描述符为 ${fd}`);
// 关闭文件
fs.close(fd, (err) => {
if (err) {
console.error(err);
return;
}
console.log('文件已关闭');
});
});
注意:
1. 在回调函数中,我们可以进行文件操作,如读取、写入等。完成后,记得通过 fs.close() 方法关闭文件,以释放资源。
2. fs.open() 方法是异步的,也可以使用同步版本的 fs.openSync() 进行同步操作,但建议在大多数情况下使用异步方法,以避免阻塞进程。
12.2 文件读取
- fs.readFile(path, [options], callback):异步地读取指定路径的文件内容。
- fs.readFileSync(path, [options]):同步地读取指定路径的文件内容。
[options] 参数可以包含以下属性:
- encoding:指定文件的编码格式,可以是字符串形式的编码名称(如
'utf8'、'ascii'等),或者null。如果不指定编码格式,则返回原始的缓冲区数据。 - flag:指定打开文件时的标志位。常见的取值包括
'r'(默认值,表示以读取模式打开文件)、'w'(表示以写入模式打开文件)、'a'(表示以追加模式打开文件)等。 - mode:在创建新文件时用于指定文件的权限,默认为
0o666。 - autoClose:指定在读取完文件后是否自动关闭文件描述符,默认为
true。 - emitClose:指定在文件关闭时是否触发
'close'事件,默认为false。
下面是一个文件读取的示例代码:
const fs = require('fs');
// 异步读取文件
fs.readFile('/Users/ydcq/Desktop/hello.txt', 'Hello, World!', (err, data) => {
if (err) throw err;
console.log(data);
});
// 同步读取文件
const content = fs.readFileSync('/Users/ydcq/Desktop/hello.txt', 'utf8');
console.log(content);
上述代码中,首先通过 fs.readFile() 方法异步读取文件内容,并通过回调函数返回结果。然后使用 fs.readFileSync() 方法同步读取文件内容。
12.3 文件写入
- fs.writeFileSync(path, [options]):同步地将数据写入文件。
- fs.existsSync(path):检查指定路径的文件是否存在。
[options] 参数可以包含以下属性:
- encoding:指定要写入文件的编码格式,可以是字符串形式的编码名称(如
'utf8'、'ascii'等),或者null。如果不指定编码格式,则写入原始的Buffer或Uint8Array数据。 - mode:在创建新文件时用于指定文件的权限,默认为
0o666。 - flag:指定打开文件时的标志位。常见的取值包括
'w'(默认值,表示以写入模式打开文件)、'a'(表示以追加模式打开文件)等。
signal:一个 AbortSignal 对象,用于在中止写入操作时发出信号。
下面是一个文件写入的示例代码:
const fs = require('fs');
// 获取文件信息
fs.stat('/Users/ydcq/Desktop/hello.txt', (err, stats) => {
if (err) throw err;
console.log(stats);
});
// 检查文件是否存在
const exists = fs.existsSync('/Users/ydcq/Desktop/hello.txt');
console.log(exists);
在上述示例中,我们使用 fs.writeFile() 方法异步地将字符串 'Hello, World!' 写入名为 file.txt 的文件,并在回调函数中处理可能出现的错误。另外,使用 fs.writeFileSync() 方法同步地将字符串写入文件。
12.4 获取文件信息
- fs.stat(path, [options], callback):获取指定路径的文件信息。
- fs.statSync(path, [options]):用于获取给定文件路径的详细信息,这是一个同步方法,与异步方法
fs.stat()不同,fs.statSync()是阻塞的,会在获取完文件信息后立即返回结果。
[options] 参数可以包含以下属性:
- bigint:一个布尔值,用于指定是否返回
fs.Stats对象中的整数值为BigInt类型。默认值为false。 - throwIfNoEntry:一个布尔值,用于指定当文件不存在时是否抛出错误。默认值为
false,即不抛出错误,而是将错误作为参数传递给回调函数。 - signal:一个 AbortSignal 对象,用于在中止获取状态操作时发出信号。
示例代码:
const fs = require('fs');
// 获取文件信息
fs.stat('/Users/ydcq/Desktop/hello.txt', (err, stats) => {
if (err) throw err;
console.log(stats);
});
在上述代码中,我们使用 fs.stat() 方法获取名为 hello.txt 的文件信息,并在回调函数中打印该信息。
fs.statSync() 方法返回一个 fs.Stats 对象,其中包含了有关文件的各种属性和方法,如文件大小、创建时间、修改时间等。可以使用 fs.Stats 对象的属性和方法来进一步处理文件的信息。
| 属性 | 描述 |
|---|---|
| dev | 文件所在设备的标识符。对于网络文件系统(NFS)来说,该值可能为未定义。 |
| ino | 文件的 inode 编号。一般情况下,每个文件系统都会给文件分配一个唯一的编号。 |
| mode | 文件的权限和类型。它表示文件的访问权限(如读、写、执行)以及文件的类型(如普通文件、目录、符号链接等)。 |
| nlink | 文件的硬链接数量。硬链接是指多个文件名指向同一个 inode 的情况。 |
| uid | 文件所有者的用户标识符。它代表文件所属用户的唯一标识符。 |
| gid | 文件所有者的组标识符。它代表文件所属组的唯一标识符。 |
| rdev | 如果文件是特殊文件(如设备文件),则表示设备的标识符。对于普通文件来说,该值为未定义。 |
| size | 文件大小,以字节为单位。 |
| blksize | 文件系统用于 I/O 操作的块大小。在许多文件系统中,它是文件分配的最小单位。 |
| blocks | 文件占用的块数量。一个块通常是一个固定大小的存储单元。 |
| atimeMs | 上次访问时间的毫秒数。它表示文件最后一次被访问的时间。 |
| mtimeMs | 修改时间的毫秒数。它表示文件内容最后一次被修改的时间。 |
| ctimeMs | 变化时间的毫秒数。它表示文件的状态信息(如权限、所有者等)最后一次被修改的时间。 |
| birthtimeMs | 创建时间的毫秒数。它表示文件的创建时间。 |
12.5 追加内容
使用 fs.appendFile(filename, data, [options], callback) 方法可以异步地追加数据到指定文件末尾。它接受文件路径、要追加的数据和一个回调函数作为参数,回调函数中会返回追加完成或错误信息。
[options] 参数可以包含以下属性:
- encoding:指定要追加的数据的编码格式,可以是字符串形式的编码名称(如
'utf8'、'ascii'等),或者null。如果不指定编码格式,则直接将数据以Buffer或Uint8Array的形式追加到文件中。 - mode:在创建新文件时用于指定文件的权限,默认为
0o666。 - flag:指定打开文件时的标志位。常见的取值包括
'a'(默认值,表示以追加模式打开文件)和'ax'(表示以追加模式打开文件,但如果文件已存在则会抛出错误)等。 - signal:一个 AbortSignal 对象,用于在中止追加操作时发出信号。
示例代码:
const data = 'Hello, world!';
fs.appendFile('/Users/ydcq/Desktop/hello.txt', data, (err) => {
if (err) {
console.error(err);
return;
}
console.log('Data has been appended.');
});
上述代码将字符串 "Hello, world!" 异步地追加到名为 hello.txt 的文件末尾。如果文件不存在,则会创建该文件;如果文件已存在,则会在原有内容末尾追加新内容。追加完成后,通过回调函数输出成功信息或错误信息。
12.6 移动/重命名文件
使用 fs.rename(oldPath, newPath, callback) 方法可以异步地移动或重命名文件。它接受旧文件路径、新文件路径和一个回调函数作为参数,回调函数中会返回移动/重命名完成或错误信息。
fs.rename('/Users/ydcq/Desktop/web/node_demo/demo.js', '/Users/ydcq/Desktop/web/node_demo/demo_new.js', (err) => {
if (err) {
console.error(err);
return;
}
console.log('File has been renamed.');
});
上述代码将名为 demo.js 的文件重命名为 demo_new.js。如果重命名成功,将打印成功信息;如果重命名失败,将输出错误信息。
12.7 删除文件
-
fs.unlink(path, [callback(err)]):可以异步地删除指定的文件。它接受文件路径和一个回调函数作为参数,回调函数中会返回删除完成或错误信息。
-
fs.rmSync(path, [options]):用于同步删除文件或目录的方法。它的作用是删除指定路径的文件或目录,如果目标是一个目录,则会递归地删除该目录及其所有内容。
[options] 参数可以包含以下属性:
- force:一个布尔值,用于指定是否强制删除文件或目录。默认情况下,如果目录非空或文件不可写,则会抛出错误。将
force设置为true可以忽略这些错误并强制执行删除操作。 - maxRetries:一个整数,用于指定在删除失败时的最大重试次数。默认值为
0,表示不重试删除操作。 - recursive:一个布尔值,用于指定是否递归删除目录及其内容。默认情况下,如果删除的是目录且目录非空,则会抛出错误。将
recursive设置为true可以递归删除目录及其内容。 - retryDelay:一个整数,用于指定在重试删除操作之间的延迟时间(以毫秒为单位)。默认值为
100。 - retryDelayMultiplier:一个数字,用于指定重试删除操作的延迟时间乘数。默认值为
1。
- force:一个布尔值,用于指定是否强制删除文件或目录。默认情况下,如果目录非空或文件不可写,则会抛出错误。将
fs.unlink('file.txt', (err) => {
if (err) {
console.error(err);
return;
}
console.log('File has been deleted.');
});
// 递归删除目录及其内容
fs.rmSync('/Users/ydcq/Desktop/web', { recursive: true });
12.8 创建目录
- fs.mkdir(path, [options], callback):创建一个目录。
- fs.mkdirSync(path, [options]):同步创建一个目录。
[options] 参数可以包含以下属性:
- recursive:一个布尔值,用于指定是否递归创建目录。默认情况下,如果上级目录不存在,则会抛出错误。将
recursive设置为true可以递归创建目录及其上级目录。 - mode:一个整数或字符串,用于指定新目录的权限,默认为
0o777。如果指定为一个字符串,则表示权限的八进制字符串表示形式(如 ‘755’)。 - signal:一个
AbortSignal对象,用于在中止创建操作时发出信号。
示例代码:
const fs = require('fs');
// 异步创建目录
fs.mkdir('/Users/ydcq/Desktop/web', { recursive: true }, (err) => {
if (err) throw err;
console.log('目录已创建');
});
// 同步创建目录
try {
// recursive(布尔值):如果为 true,则会递归创建目录;默认为 false。
fs.mkdirSync('/Users/ydcq/Desktop/web', { recursive: true });
console.log('目录已创建');
} catch (err) {
console.error(err);
}
12.9 读取目录下的所有文件
- fs.readdir(path, [options], callback):可以异步地读取指定目录下的所有文件。它接受目录路径和一个回调函数作为参数,回调函数中会返回目录下的文件名列表。
- fs.readdirSync(path, [options]):同步读取指定的目录路径下的所有文件。可选参数对象,包括
withFileTypes(布尔值):如果为true,则返回fs.Dirent对象数组而不是文件名数组;默认为false。
[options] 参数可以包含以下属性:
- encoding:指定目录中文件名的编码格式,可以是字符串形式的编码名称(如
'utf8'、'ascii'等),或者null。如果不指定编码格式,则返回的文件名将以Buffer或Uint8Array的形式给出。 - withFileTypes:一个布尔值,用于指定是否返回
fs.Dirent对象而不是文件名的数组。默认情况下,返回的是文件名的数组。设置为true则返回fs.Dirent对象,该对象包含文件名以及文件类型等信息。 - signal:一个 AbortSignal 对象,用于在中止读取操作时发出信号。
示例代码:
const fs = require('fs');
// 异步读取指定的目录下的文件
fs.readdir('/Users/ydcq/Desktop/web', (err, files) => {
if (err) {
console.error(err);
return;
}
console.log(files);
});
// 同步读取指定的目录下的文件
const path = require('path');
function readDirFilesSync(dirPath) {
const files = fs.readdirSync(dirPath, { withFileTypes: true });
files.forEach((file) => {
const filePath = path.join(dirPath, file.name);
if (file.isDirectory()) {
// 如果是目录,则递归读取其下的所有文件
readDirFilesSync(filePath);
} else {
// 如果是文件,则输出其路径和大小
const stats = fs.statSync(filePath);
console.log(`${filePath} (${stats.size} bytes)`);
}
});
}
// 同步读取目录及其子目录下的所有文件
readDirFilesSync('/Users/ydcq/Desktop/web');
12.10 删除目录
- fs.rmdir(path, [options], callback):异步删除指定的目录。
- fs.rmdirSync(path, [options]):同步删除指定的目录。可选参数对象,包括
recursive(布尔值):如果为true,则递归删除目录和其子目录;默认为false。
[options] 参数可以包含以下属性:
- recursive:一个布尔值,用于指定是否执行递归目录删除。在这种模式下,如果找不到指定的路径并且在失败时重试该操作,则不会报告错误。默认值为
false。 - maxRetries:一个整数值,用于指定
Node.js由于任何错误而失败时将尝试执行该操作的次数。在给定的重试延迟后执行操作。如果递归选项未设置为true,则忽略此选项。默认值为0。 - retryDelay:一个整数值,用于指定重试操作之前的等待时间(以毫秒为单位)。如果递归选项未设置为
true,则忽略此选项。默认值为100毫秒。
示例代码:
const fs = require('fs');
// 异步删除目录
fs.rmdir('/Users/ydcq/Desktop/web', { recursive: true }, (err) => {
if (err) throw err;
console.log('目录已删除');
});
// 同步删除目录
try {
fs.rmdirSync('/Users/ydcq/Desktop/web', { recursive: true });
console.log('目录已删除');
} catch (err) {
console.error(err);
}
12.11 监听目录变更
使用 fs.watch() 方法可以异步地监听指定目录的变化。它接受目录路径和一个回调函数作为参数,回调函数中会返回变化的类型和文件名等信息。
示例代码:
const fs = require('fs');
fs.watch('/Users/ydcq/Desktop/web/demo', (eventType, filename) => {
console.log(`Event type: ${eventType}`);
console.log(`File name: ${filename}`);
});
上述代码监听当前目录的变化,将事件类型和文件名等信息打印出来。如果有文件被创建、修改或删除等操作,将触发回调函数并输出相应信息。
12.12 查询文件访问权限
fs.access(path, mode, callback) 方法用于检查文件或目录的访问权限。它可以检查文件/目录是否存在以及是否具有指定的权限。
- path:要检查的文件或目录路径。
- mode:一个可选的整数参数,用于指定要检查的权限,默认为
fs.constants.F_OK,表示检查文件/目录是否存在。其他可选的常量值包括:- fs.constants.R_OK:检查文件/目录是否可读。
- fs.constants.W_OK:检查文件/目录是否可写。
- fs.constants.X_OK:检查文件/目录是否可执行。
- callback:回调函数,接收一个可能出现的异常参数。如果没有错误发生,则表示具有所需权限。
示例代码:
const fs = require('fs');
// 检查文件是否可读
fs.access('path/to/file', fs.constants.R_OK, (err) => {
if (err) {
console.error('文件不可读');
} else {
console.log('文件可读');
}
});
// 检查目录是否存在
fs.access('path/to/directory', fs.constants.F_OK, (err) => {
if (err) {
console.error('目录不存在');
} else {
console.log('目录存在');
}
});
注意:
1. fs.access 方法是异步的,通过回调函数来处理结果。如果没有指定权限参数 mode,则默认为检查文件/目录是否存在。在回调函数中,如果出现错误,则表示文件/目录不具备所需的权限;如果没有错误,则表示具有所需权限。
2. fs.access 方法只是检查权限,并不能用于修改权限。另外,该方法在进行文件/目录访问前先检查权限是一个良好的实践,可以避免在访问时出现异常。
12.13 修改文件权限
fs 模块提供了 fs.chmod(path, mode, callback) 方法来修改文件的权限。该方法将更改指定路径上文件/目录的权限,具体更改的权限由参数 mode 决定。以下是 fs.chmod() 方法的基本信息:
参数:
- path:要更改权限的文件/目录的路径。
- mode:一个整数或字符串,用于指定新的文件/目录权限。可以使用八进制表示法或字符串形式,如
0o755或'rwxr-xr-x'。更多信息可以参考chmod()文档。 - callback:回调函数,接收一个可能出现的异常参数。
示例代码:
const fs = require('fs');
// 修改文件权限为 644
fs.chmod('path/to/file', 0o644, (err) => {
if (err) {
console.error(`更改文件权限失败: ${err}`);
} else {
console.log('文件权限已更改');
}
});
// 修改目录权限为 755
fs.chmod('path/to/directory', 'rwxr-xr-x', (err) => {
if (err) {
console.error(`更改目录权限失败: ${err}`);
} else {
console.log('目录权限已更改');
}
});
注意:
1. fs.chmod() 方法是异步的,通过回调函数来处理结果。在回调函数中,如果出现错误,则表示权限更改失败;如果没有错误,则表示权限已成功更改。
2. fs.chmod() 方法需要有足够的权限才能更改文件/目录的权限,否则将会抛出权限不足的错误。在使用该方法时,建议先通过 fs.access() 方法检查当前用户是否具备更改权限。
总结
fs 模块提供了丰富的文件系统操作功能,可以很方便地读取、写入、删除和管理文件。当需要进行文件系统操作时,可以使用 fs 模块来实现相应的功能。
13-路径模块 Path
path 模块是 Node.js 中一个核心模块,用于处理文件路径相关的操作。它提供了一组常用的函数来处理文件路径,包括路径解析、规范化、拼接、相对路径等等。
以下是 path 模块中常用的一些方法:
13.1 path.normalize(p)
将一个路径字符串转换为标准路径格式。它会解析出其中的 . 和 ..,并将多个路径分隔符转换为单个分隔符。
const path = require('path');
console.log(path.normalize('/foo/bar//baz/asdf/quux/..')); // '/foo/bar/baz/asdf'
13.2 path.join([…paths])
将多个路径拼接成一个完整的路径。它会自动处理多余的路径分隔符,并返回一个标准路径格式的字符串。
const path = require('path');
console.log(path.join('/foo', 'bar', 'baz/asdf', 'quux', '..')); // '/foo/bar/baz/asdf'
13.3 path.resolve([…paths])
将多个路径解析为一个绝对路径。它会从右到左地依次处理每个路径片段,并返回一个绝对路径格式的字符串。
const path = require('path');
console.log(path.resolve('/foo/bar', './baz')); // '/foo/bar/baz'
console.log(path.resolve('/foo/bar', '/tmp/file/')); // '/tmp/file'
13.4 path.relative(from, to)
获取从一个路径到另一个路径的相对路径。它会返回一个相对路径格式的字符串。
const path = require('path');
console.log(path.relative('/data/orandea/test/aaa', '/data/orandea/impl/bbb')); // '../../impl/bbb'
13.5 path.dirname(p)
获取一个路径的目录名。它会返回一个目录名格式的字符串。
const path = require('path');
console.log(path.dirname('/foo/bar/baz/asdf/quux')); // '/foo/bar/baz/asdf'
13.6 path.basename(p, [ext])
获取一个路径的文件名或者是目录名。可以通过第二个参数指定要去掉的文件扩展名。
const path = require('path');
console.log(path.basename('/foo/bar/baz/asdf/quux.html')); // 'quux.html'
console.log(path.basename('/foo/bar/baz/asdf/quux.html', '.html')); // 'quux'
13.7 path.extname(p)
获取一个路径的扩展名。它会返回一个扩展名格式的字符串。
const path = require('path');
console.log(path.extname('/foo/bar/baz/asdf/quux.html')); // '.html'
13.8 path.parse(pathString)
将一个路径字符串解析为一个对象。该对象包含以下属性:root、dir、base、name、ext。
const path = require('path');
console.log(path.parse('/foo/bar/baz/asdf/quux.html'));
// {
// root: '/',
// dir: '/foo/bar/baz/asdf',
// base: 'quux.html',
// ext: '.html',
// name: 'quux'
// }
总结
通过使用 path 模块的方法,可以方便地处理和操作文件路径和目录路径,避免手动处理字符串操作带来的错误和不兼容性。
14-Buffer
Buffer 是一个用于处理二进制数据的类。它的作用类似于 JavaScript 中的数组,但可以存储任意的二进制数据。
14.1 创建Buffer
Buffer 是以字节序列的形式表示二进制数据,并且可以在不同编码间进行转换。Buffer 在处理网络流、文件系统操作、加密和解密等方面都非常有用。在使用 Buffer 之前,需要先将它实例化。
可以使用以下方法之一来创建一个新的 Buffer 对象:
-
Buffer.alloc(sizem, [fill], [encoding]):创建一个指定大小的 Buffer 对象,并将其填充为0或其他指定的值。
const buf = Buffer.alloc(10); // 创建一个长度为10的 Buffer 对象,每个字节都填充为0 -
Buffer.from(array):从一个数组中创建一个新的 Buffer 对象。
const buf = Buffer.from([0x62, 0x75, 0x66, 0x66, 0x65, 0x72]); // 创建一个包含ASCII字符串“buffer”的Buffer对象 -
Buffer.from(string, [encoding]):从一个字符串中创建一个新的 Buffer 对象。
const buf = Buffer.from('Hello, Node.js!', 'utf8'); // 创建一个包含UTF-8编码的字符串的Buffer对象
通过使用以上任意一种方法,都可以创建一个新的 Buffer 对象。接下来,您可以对其进行读写操作。
例如,可以通过给 Buffer 对象赋值来设置其内容。可以使用下标来访问和修改 Buffer 中的数据:
const buf = Buffer.alloc(4);
buf[0] = 0x61; // 字符 'a' 的ASCII码为0x61
buf[1] = 0x62; // 字符 'b' 的ASCII码为0x62
buf[2] = 0x63; // 字符 'c' 的ASCII码为0x63
buf[3] = 0x64; // 字符 'd' 的ASCII码为0x64
console.log(buf); // <Buffer 61 62 63 64>
console.log(buf.toString()); // 'abcd'
另外,也可以使用 buf.write(string, [offset], [length], [encoding]) 方法向 Buffer 对象中写入数据。
参数说明:
- string:写入 buffer 的数据内容。
- offset:可选参数,
offset指的是写入到buffer的位置,默认为0。 - length:可选参数,写入到
buffer的内容长度。 - encoding:可选参数,写入内容的编码格式。
使用 buf.toString() 方法从 Buffer 对象中读取数据。
const buf = Buffer.alloc(11);
// 写入
const len = buf.write('Hello, Node');
console.log(`写入${len}个字节`);
const buf2 = Buffer.alloc(4);
// 写入
let len = buf2.write('abcd');
console.log(len); // 4
// 读取
console.log(buf2.toString()); // 'abcd'
在 Node.js 中,如果需要将多个 Buffer 对象拼接成一个 Buffer 对象时,可以使用 Buffer.concat(list, length) 方法:
const buf1 = Buffer.from('Hello');
const buf2 = Buffer.from('World');
const buf3 = Buffer.concat([buf1, buf2]);
console.log(buf3.toString()); // 'HelloWorld'
14.2 Buffer与字符编码
在处理文本数据时,我们需要将字符串转换为二进制数据类型,或者是将二进制数据转换为字符串类型,这时候需要用到字符串的编码格式。Buffer 对象用于处理二进制数据,由于字符编码是将字符映射到数字的过程,因此在处理字符串时需要考虑字符编码。
下面是字符串编码格式的详细说明:
| 编码 | 说明 |
|---|---|
| ASCII | ASCII编码是最早期的字符编码标准,使用7位二进制数表示128个字符,包括英文字母、数字和一些符号。它是一种单字节编码,每个字符占用一个字节的空间。 |
| UTF-8 | UTF-8是一种可变长度的Unicode字符编码,用于表示Unicode标准中的所有字符。在Node.js中,默认情况下使用UTF-8编码来处理字符串数据。这意味着大多数情况下,我们不需要显式地指定编码格式。 |
| UTF-16LE | UTF-16是一种针对Unicode的可变长度字符编码,使用1至2个16位编码单元(即2至4个字节)来表示一个字符。 |
| UCS-2 | UCS-2编码是一种定长编码格式,每个字符占用2个字节(16位),高位字节和低位字节分别存储字符的编码值。相比于UTF-8和UTF-16等可变长度编码格式,UCS-2编码的优势在于可以更方便地计算字符串的长度和索引。 |
| Base64 | Base64编码是一种常见的编码方式,用于将二进制数据转换为可打印字符的字符串表示。Base64编码由64个字符组成,通常包括A-Z、a-z、0-9以及两个额外的字符(通常是+和/),用于表示二进制数据中的各种字节组合。 |
| Binary | 这是二进制数据,字符串现在已经不推荐使用。 |
| HEX | Hex(十六进制)编码是一种常见的编码方式,用于将二进制数据转换为十六进制表示的字符串。Hex编码使用0-9和A-F这16个字符来表示一个字节的所有可能取值。 |
14.3 Buffer的转换
在 Node.js 中,可以使用 Buffer 类型来处理二进制数据。以下是一些常见的 Buffer 转换方法:
14.3.1 Buffer和字符串的转换
-
Buffer转换为字符串
使用 buf.toString([encoding], [start], [end]) 方法将 Buffer 对象转换为字符串。可以指定编码方式,默认为UTF-8编码。
参数说明:
- encoding:可选参数,指定要使用的字符编码。常见的编码方式包括
'utf8'、'ascii'、'latin1'等。 - start:可选参数,指定要开始读取的索引位置,默认为
0。 - end:可选参数,指定要结束读取的索引位置,默认为 Buffer 的长度。
const buf = Buffer.from('Hello, Node.js!', 'utf8'); const str = buf.toString('utf8'); console.log(str); // 'Hello, Node.js!' - encoding:可选参数,指定要使用的字符编码。常见的编码方式包括
-
字符串转换为Buffer:
使用 Buffer.from(string, [encoding]) 方法将字符串转换为 Buffer 对象。
参数说明:
- string:要转换为Buffer的字符串。
- encoding:可选参数,指定要使用的字符编码,默认为UTF-8编码。
const str = 'Hello, Node.js!'; const buf = Buffer.from(str, 'utf8'); console.log(buf); // <Buffer 48 65 6c 6c 6f 2c 20 4e 6f 64 65 2e 6a 73 21> -
Buffer转换为十六进制字符串
使用 Buffer.from(string, ‘hex’) 方法将十六进制字符串转换为 Buffer 对象。
参数说明:
- encoding:可选参数,指定要使用的字符编码,默认为
UTF-8编码。
const buf = Buffer.from('Hello, Node.js!', 'utf8'); const hexStr = buf.toString('hex'); console.log(hexStr); // '48656c6c6f2c204e6f64652e6a7321' - encoding:可选参数,指定要使用的字符编码,默认为
-
十六进制字符串转换为Buffer:
使用 Buffer.from(string, ‘hex’) 方法将十六进制字符串转换为 Buffer 对象。
const hexStr = '48656c6c6f2c204e6f64652e6a7321'; const buf = Buffer.from(hexStr, 'hex'); console.log(buf); // <Buffer 48 65 6c 6c 6f 2c 20 4e 6f 64 65 2e 6a 73 21>
这些转换方法使得在 Node.js 中处理不同数据格式之间的转换变得非常方便。需要注意的是,在进行转换时应确保所使用的编码方式是一致的,以避免出现数据解析错误或乱码的问题。
14.3.2 Buffer和JSON对象的转换
在 Node.js 中,Buffer 对象用于处理二进制数据,而 JSON 对象用于处理 JavaScript 对象的序列化和反序列化。因此,有时我们需要在它们之间进行转换,以便在处理数据时能够方便地在二进制数据和 JavaScript 对象之间进行转换。
以下是如何在 Node.js 中进行 Buffer 和 JSON 对象之间的转换:
-
将Buffer对象转换为JSON对象:
const buf = Buffer.from('Hello, 世界', 'utf8'); const jsonStr = buf.toJSON(); console.log(jsonStr); // 输出:{"type":"Buffer","data":[72,101,108,108,111,44,32,228,184,150,231,149,140]} -
将JSON对象转换为Buffer对象:
const jsonStr = '{"type":"Buffer","data":[72,101,108,108,111,44,32,228,184,150,231,149,140]}'; const buf = Buffer.from(JSON.parse(jsonStr).data); console.log(buf.toString('utf8')); // 输出:Hello, 世界
在上述示例中,使用 Buffer 对象的 toJSON 方法可以将 Buffer 对象转换为符合 JSON 格式的对象,其中包含了 Buffer 数据的类型和具体的字节数组。而使用 JSON 对象的 parse 方法可以将符合特定格式的 JSON 字符串转换为 JavaScript 对象,然后再通过 Buffer.from 方法将字节数组转换回 Buffer 对象。
在实际开发中,这种转换通常在处理网络数据、文件读写等场景中会经常用到。例如,当从网络接收到的数据是 Buffer 类型时,可以将其转换为 JSON 对象以便进行传输、存储或展示;相反,当需要将收到的 JSON 对象中的二进制数据恢复为 Buffer 对象时,也可以使用上述方法进行转换。
14.4 Buffer的其他方法
- buf.length:length 属性返回 Buffer 对象的长度。
- Buffer.byteLength(string, [encoding]):返回 Buffer 对象占用的字节数。
- buf.compare(otherBuffer):用于比较两个 Buffer 对象的内容是否相等。
- buf.copy(target, [targetStart], [sourceStart], [sourceEnd]):用于将当前
Buffer对象中的数据复制到另一个 Buffer 对象中。 - Buffer.isBuffer(obj):判断一个对象是否是一个 Buffer 对象。
- Buffer.isEncoding():用于判断一个字符串是否为一个有效的编码格式字符串。
总结
Buffer 类在 Node.js 中被广泛应用于处理文件、网络通信、加密解密等场景。由于它是基于原始二进制数据的,因此可以高效地进行数据操作和处理。
需要注意的是,在使用 Buffer 时应当小心处理内存的使用,避免出现内存泄漏或溢出的情况。同时,随着 Node.js 版本的更新,对 Buffer 的使用也有一些变化,开发者需要根据具体的 Node.js 版本来使用相应的 Buffer API。
15-Stream
Stream(流)是一种用于处理流式数据的抽象接口。它提供了一种逐块处理数据的方式,可以有效地处理大量的数据,同时减少内存占用和响应时间。Node.js 中的 Stream 模块提供了丰富的API来创建、读取、写入和处理流。
在 Node.js 中,流可以分为四种类型:
-
可读流(Readable Streams):可读流用于从数据源读取数据,例如文件读取流、HTTP 请求响应流等。可读流的特点是可以逐块地读取数据,而不需要一次性将所有数据存储在内存中。通过监听data事件或使用read()方法,可以逐块地获取数据。
-
可写流(Writable Streams):可写流用于向目标写入数据,例如文件写入流、HTTP 请求发送流等。可写流的特点是可以逐块地写入数据,而不需要一次性将所有数据存储在内存中。通过
write()方法将数据逐块写入目标。 -
双工流(Duplex Streams):双工流即可读又可写,既可以从数据源读取数据,又可以向目标写入数据。一个常见的例子是网络套接字,它既可以接收数据也可以发送数据。
-
转换流(Transform Streams):转换流是一种特殊的双工流,它可以通过对输入数据进行转换来生成输出数据。转换流通常用于对数据进行处理,例如数据压缩、加密、解密等操作。
Node.js 中的 Stream 对象通常会继承自 EventEmitter。由于 Stream 继承自 EventEmitter,因此 Stream 对象也具有 EventEmitter 的所有功能。Stream 对象可以发出各种事件,如:data、end、error等,这些事件可以被监听器捕获,并在事件发生时执行相应的回调函数。例如,在可读流中,当有新的数据可用时,可读流会触发 data 事件,此时监听器可以对数据进行处理。
下面是 Stream 对象中常见的事件:
- data:有新数据可用时触发。
- end:数据读取完毕时触发。
- error:数据写入缓冲区后触发。
- finish:数据写入完成时触发。
- drain:数据写入缓冲区后触发。
15.1 从Stream中读取数据
在 Node.js 中,可以通过可读流(Readable Stream)从数据源中读取数据。
// 1.引入fs模块
const fs = require('fs');
// 2.创建可读流对象
const readableStream = fs.createReadStream('file.txt');
// 设置编码为 utf8。(可选)
readerStream.setEncoding('UTF8');
// 3.为可读流添加事件监听器
readableStream.on('data', (chunk) => {
// 处理每个数据块(chunk)
console.log(chunk.toString()); // 可以转换或存储
});
readableStream.on('end', () => {
// 数据读取完毕,关闭可读流 (可选)
readableStream.close();
});
readableStream.on('error', (err) => {
// 处理错误,关闭可读流 (可选)
readableStream.close();
});
注意:
1. 在使用可读流读取大型文件时,数据可能会分为多个数据块,因此需要适当处理每个数据块的到达和结束的情况。
2. 通常情况下,不需要手动关闭可读流。当所有数据都被读取完毕时,可读流会自动触发end事件,表示数据读取结束。
3. 如果需要手动关闭可读流,可以调用close()方法进行关闭操作。
15.2 写入Stream
创建可写流对象,调用 write() 方法写入数据,最后使用 end() 方法结束写入操作。同时,可以通过事件机制监听数据写入缓冲区后、写入完成或发生错误时的情况。
// 1.引入fs模块
const fs = require('fs');
// 2.创建可写流对象
const writableStream = fs.createWriteStream('output.txt');
// 3.将数据写入目标
writableStream.write('Hello, world!', 'utf-8');
// 4.结束写入操作
writableStream.end();
writableStream.on('drain', () => {
// 数据写入缓冲区后触发
});
writableStream.on('finish', () => {
// 数据写入完成时触发
});
writableStream.on('error', (err) => {
// 处理错误
});
注意:
1. 在写入完所有数据后,应该调用end()方法来结束写入操作,这会触发 finish 事件,表示数据写入完成。
2. 通常情况下,也不需要手动关闭可写流。在调用 end() 方法后,可写流会自动完成关闭操作。
3. 如果需要手动关闭可写流,同样可以调用 end() 方法或 destroy() 方法来关闭可写流。
15.3 管道流
管道流(Piping)是一种将可读流(Readable Stream)和可写流(Writable Stream)连接起来的方式。通过管道流,可以将数据从一个流传输到另一个流,而无需手动处理数据缓冲区或流结束等情况。这样可以简化代码,并提高性能。以下是使用管道流的基本步骤:
// 1.引入fs模块
const fs = require('fs');
// 2.创建可读流和可写流对象
const readableStream = fs.createReadStream('input.txt'); // 创建一个从文件中读取数据的可读流
const writableStream = fs.createWriteStream('output.txt'); // 创建一个向文件中写入数据的可写流
// 3.建立管道连接
readableStream.pipe(writableStream); // // 读取 input.txt 文件内容,并将内容写入到 output.txt 文件中
以上就是使用管道流的基本步骤。通过建立管道连接,可以自动将可读流中的数据传输到可写流中,无需手动处理数据缓冲区或流结束等情况。管道流可以简化代码,并提高性能。
注意:在使用管道流时,应该避免出现循环管道(Circular Piping)的情况,这会导致程序死锁。例如,下面的代码就会导致循环管道:
readableStream.pipe(writableStream);
writableStream.pipe(readableStream);
15.4 链式流
链式流(Chained Streams)是一种将多个流(Stream)连接起来形成一个流处理管道的方式,通过串联多个流,可以方便地对数据进行多次处理。在Node.js中,链式流可以通过多次调用pipe()方法来实现。
// 1.引入fs模块
const fs = require('fs');
// 2.创建可读流和可写流对象
const readableStream = fs.createReadStream('input.txt'); // 创建一个从文件中读取数据的可读流
const writableStream = fs.createWriteStream('output.txt'); // 创建一个向文件中写入数据的可写流
// 3.创建转换流对象
// 使用Transform类或其他相关类创建转换流(Transform Stream)对象,用于对数据进行处理。例如,使用zlib.createGzip()方法创建一个压缩转换流。
const zlib = require('zlib');
const gzip = zlib.createGzip();
// 4.建立链式连接
// 使用pipe()方法建立链式连接,将多个流对象串联起来。这样,可读流中的数据会经过多个流对象自动传输,并进行相应的处理。
readableStream.pipe(gzip).pipe(writableStream);
以上就是使用链式流的基本步骤。通过建立链式连接,可以方便地对数据进行多次处理,例如将数据进行压缩、加密等操作后再写入文件。在链式流中,每个流对象都是一个独立的处理单元,可以根据需要添加或删除流对象。
注意:在使用链式流时,也应该避免出现循环链式(Circular Chaining)的情况,这会导致程序死锁。例如,下面的代码就会导致循环链式:
readableStream.pipe(gzip).pipe(writableStream);
writableStream.pipe(readableStream);
总结
Node.js 的流提供了一种高效处理数据的方式,特别适合处理大型数据集或需要实时处理的场景。通过使用流,可以减少内存占用、提高响应速度,并且提供了灵活的数据处理管道。
16-系统 os
Node.js 的 os 模块提供了一些与操作系统相关的实用方法,可以用于获取有关操作系统的信息。以下是 os 模块中一些常用的方法和属性:
| 方法 | 描述 | |
|---|---|
| os.EOL | 根据不同的操作系统生成不同的换行符。 |
| os.arch() | 返回当前计算机的处理器架构,如 x64、arm、ia32 等。 |
| os.cpus() | 返回一个对象数组,描述当前计算机的 CPU 内核信息,包括型号、速度、时间戳等。 |
| os.endianness() | 返回当前计算机的字节序(大端字节序或小端字节序)。 |
| os.freemem() | 返回当前计算机的空闲内存量(以字节为单位)。 |
| os.totalmem() | 返回当前计算机的总内存量(以字节为单位)。 |
| os.hostname() | 返回当前计算机的主机名。 |
| os.loadavg() | 返回最近 1 分钟、5 分钟和 15 分钟内的系统平均负载。 |
| os.networkInterfaces() | 返回当前计算机的网络接口信息,包括 IP 地址、子网掩码、MAC 地址等。 |
| os.platform() | 返回当前计算机的操作系统平台,如 win32、linux、darwin 等。 |
| os.release() | 返回当前计算机的操作系统版本号。 |
| os.tmpdir() | 返回操作系统的默认临时文件目录路径。 |
| os.type() | 返回当前计算机的操作系统类型,如 Linux、Windows_NT 等。 |
| os.uptime() | 返回当前计算机自上次启动以来的运行时间(以秒为单位)。 |
下面是os模块的一些示例:
const os = require('os');
console.log("Hello" + os.EOL + "World!"); // 换行
console.log(os.arch()); // 输出: x64
console.log(os.cpus()); // 输出cpu核心数
console.log(os.totalmem()); // 返回空闲系统内存的字节数
console.log(os.totalmem()); // 返回系统总内存的字节数
console.log(os.hostname()); // 返回主机名
console.log(os.networkInterfaces()); // 返回一个对象,其中包含有关网络接口的信息
console.log(os.platform()); // 返回操作系统平台
console.log(os.release()); // 返回操作系统版本
console.log(os.tmpdir()); // 返回默认临时文件目录的路径
console.log(os.type()); // 返回操作系统类型
console.log(os.uptime()); // 返回系统运行时间,以秒为单位
除了上述函数之外,os 模块还提供了其他一些函数和属性,可用于查询和与操作系统交互。例如,os.userInfo() 函数可用于获取当前用户的信息,os.constants 属性包含了操作系统的常量。
os 模块还提供了其他一些实用的方法,可以帮助开发者获取操作系统相关的信息,从而更好地编写跨平台的 Node.js 应用程序。如果有兴趣,可以查看 文档。
总结
os 模块可以帮助开发者获取操作系统和系统硬件相关的信息,从而更好地编写跨平台的 Node.js 应用程序。
17-url和queryString
17.1 url
Node.js 的 url 模块是用于处理URL(Uniform Resource Locator)的模块。它提供了一组方法,用于解析、格式化和处理URL的各个部分。
17.1.1 解析URL
-
url.parse(urlString, [parseQueryString], [slashesDenoteHost]) 方法将一个URL字符串解析为一个URL对象。
参数说明:
- urlString 是要解析的URL字符串。
- parseQueryString 是一个可选参数,用于指定是否解析查询字符串,默认为
false。 - slashesDenoteHost 也是一个可选参数,用于指定是否将双斜杠视为主机的标记,默认为
false。
解析后的结果以URL对象的形式返回,包含了URL的各个部分:
- protocol:协议部分(例如 http:)。
- slashes:是否有双斜杠。
- auth:认证信息部分(例如 username:password)。
- host:主机部分(例如 www.example.com:8080)。
- port:端口部分(字符串类型)。
- hostname:主机名部分(例如 www.example.com)。
- hash:片段标识符部分(例如 #section)。
- search:查询字符串部分(例如 ?name=John&age=25)。
- query:查询参数部分,以对象形式存储(例如 { name: ‘John’, age: ‘25’ })。
- pathname:路径部分(例如 /path)。
- path:路径和查询字符串部分(例如 /path?name=John&age=25)。
- href:完整的URL字符串。
17.1.2 格式化URL
-
url.format(urlObject) 方法将一个URL对象格式化为一个URL字符串。
- urlObject 是要格式化的URL对象,包含了URL的各个部分。
格式化后的URL字符串以字符串形式返回。
17.1.3 解析相对URL
-
url.resolve(from, to) 方法根据基础URL和相对URL生成一个完整的URL。
参数说明:
- from 是基础URL。
- to 是相对URL。
生成的完整URL以字符串形式返回。
17.1.4 URLSearchParams
- url.URLSearchParams 是一个构造函数,用于创建URL查询参数的实例。它提供了一组方法,用于操作URL查询参数,如添加、获取、删除参数等。
使用示例:
const url = require('url');
// 解析URL
const urlString = 'https://www.example.com:8080/path?name=John&age=25';
const parsedUrl = url.parse(urlString, true);
console.log(parsedUrl);
/*
输出:
{
protocol: 'https:',
slashes: true,
auth: null,
host: 'www.example.com:8080',
port: '8080',
hostname: 'www.example.com',
hash: null,
search: '?name=John&age=25',
query: { name: 'John', age: '25' },
pathname: '/path',
path: '/path?name=John&age=25',
href: 'https://www.example.com:8080/path?name=John&age=25'
}
*/
// 构建URL
const urlObject = {
protocol: 'https:',
host: 'www.example.com',
pathname: '/path',
search: '?name=John&age=25'
};
const formattedUrl = url.format(urlObject);
console.log(formattedUrl);
// 输出: https://www.example.com/path?name=John&age=25
// 解析相对URL
const base = 'https://www.example.com/';
const relative = 'about';
const resolvedUrl = url.resolve(base, relative);
console.log(resolvedUrl);
// 输出: https://www.example.com/about
// 使用URLSearchParams
const params = new url.URLSearchParams('name=John&age=25');
params.append('city', 'New York');
console.log(params.toString());
除了以上介绍的方法,url模块还提供了其他一些辅助方法,如 url.resolveObject()、url.domainToASCII()、url.domainToUnicode() 等,用于更详细地处理URL相关的操作。
url 模块是 Node.js 中处理URL的重要工具,它使得解析、构建和处理URL变得简单和方便。可以用于处理HTTP请求、路由匹配等场景。
17.2 queryString
queryString 模块是用于处理URL查询字符串的模块。查询字符串是URL中的一部分,通常用于将数据传递给服务器或从服务器接收数据。
queryString 模块提供了一组方法,可以解析和序列化查询字符串。下面是一些常用的方法:
-
queryString.parse(str, [sep], [eq], [options]):该方法将查询字符串解析为一个对象。其中,
str是要解析的查询字符串,sep是用于分隔键值对的字符,默认为'&',eq是用于分隔键和值的字符,默认为'=',options是一个可选的参数对象,可以用于定义其他选项。解析后的结果以键值对的形式存储在对象中。 -
queryString.stringify(obj, [sep], [eq], [options]]):该方法将一个对象序列化为查询字符串。其中,
obj是要序列化的对象,sep是键值对之间的分隔符,默认为'&',eq是键和值之间的分隔符,默认为'=',options是一个可选的参数对象,可以用于定义其他选项。序列化后的查询字符串以键值对的形式返回。 -
queryString.escape(str):该方法用于对字符串进行编码,使其可以安全地用作URL的一部分。编码后的字符串以URL编码的形式返回。
-
queryString.unescape(str):该方法用于对已编码的字符串进行解码,使其恢复为原始字符串。解码后的字符串以原始形式返回。
const queryString = require('querystring');
// 解析查询字符串
const params = queryString.parse('name=John&age=25');
console.log(params);
// 输出: { name: 'John', age: '25' }
// 序列化对象
const obj = { name: 'John', age: '25' };
const query = queryString.stringify(obj);
console.log(query);
// 输出: name=John&age=25
// 编码和解码
const encoded = queryString.escape('Hello, World!');
console.log(encoded);
// 输出: Hello%2C%20World%21
const decoded = queryString.unescape('Hello%2C%20World%21');
console.log(decoded);
// 输出: Hello, World!
以上是 queryString 模块的一些基本介绍和使用方法。它可以帮助你方便地处理URL查询字符串的解析和序列化操作。
总结
url 模块适用于操作和解析 URL,而 querystring 模块适用于操作和解析查询字符串。在 Node.js Web 开发中,这两个模块经常被用于处理 URL 和查询参数的相关操作。
18-dns
在 Node.js 中,dns 模块是用于进行DNS(域名系统)解析的核心模块。它提供了一系列方法来查询域名相关的信息,如 IP地址、主机名、MX记录等。
dns 模块提供了以下常用的方法:
18.1 dns.lookup(hostname, [options], callback)
该方法用于将域名解析为第一个找到的IPv4或IPv6地址。它接受三个参数:
- hostname:要解析的域名。
- options:一个可选的对象,用于配置解析行为。
- callback:一个回调函数,用于处理解析结果。
示例代码:
const dns = require('dns');
dns.lookup('www.example.com', (err, address, family) => {
console.log(`IP地址: ${address}`);
});
18.2 dns.resolve(hostname, [rrtype], callback)
该方法用于将域名解析为指定类型的记录。它接受三个参数:
-
hostname:要解析的域名。
-
rrtype:一个可选的字符串,表示要解析的记录类型,默认为
'A'。
以下是一些常见的 DNS 记录类型:-
‘A’:表示
IPv4地址记录。 -
‘AAAA’:表示
IPv6地址记录。 -
‘CNAME’:表示别名记录,将一个域名解析到另一个域名,以便重用现有的 DNS 信息。
-
‘MX’:表示邮件交换记录,指定邮件服务器的优先级和名称。
-
‘NS’:表示命名服务器记录,指定域名权威命名服务器的名称。
-
‘PTR’:表示指针记录,将
IP地址解析到主机名。 -
‘SOA’:表示起始授权记录,描述
DNS区域的属性和DNS服务器的配置。 -
‘SRV’:表示服务记录,指定提供特定服务的服务器的名称和端口号。
-
‘TXT’:表示文本记录,包含任意文本信息。
-
-
callback:一个回调函数,用于处理解析结果。
示例代码:
const dns = require('dns');
dns.resolve('www.example.com', 'MX', (err, addresses) => {
console.log('MX记录:');
addresses.forEach((address) => {
console.log(address);
});
});
18.3 dns.reverse(ip, callback)
该方法用于将IP地址解析为域名。它接受两个参数:
- ip:要解析的IP地址。
- callback:一个回调函数,用于处理解析结果。
示例代码:
const dns = require('dns');
dns.reverse('8.8.8.8', (err, hostnames) => {
console.log('域名:');
hostnames.forEach((hostname) => {
console.log(hostname);
});
});
除了上述方法,dns 模块还提供了其他一些方法,如 dns.resolve4() 用于解析 IPv4 地址,dns.resolve6() 用于解析 IPv6 地址,dns.resolveCname() 用于解析 CNAME 记录等。
| 方法 | 说明 |
|---|---|
| dns.resolve4(hostname, [options], callback) | 执行 DNS 解析以查找给定主机名的 IPv4 地址记录。可选的 options 参数用于指定查询的服务器。 |
| dns.resolve6(hostname, [options], callback) | 执行 DNS 解析以查找给定主机名的 IPv6 地址记录。可选的 options 参数用于指定查询的服务器。 |
| dns.resolveCname(hostname, callback) | 执行 DNS 解析以查找给定主机名的 CNAME 记录。返回结果是一个数组,包含该主机名的所有别名。 |
| dns.resolveMx(hostname, callback) | 执行 DNS 解析以查找给定主机名的 MX 记录。返回结果是一个数组,包含所有与该主机名关联的邮件交换服务器。 |
| dns.resolveNs(hostname, callback) | 执行 DNS 解析以查找给定主机名的 NS 记录。返回结果是一个数组,包含所有与该主机名关联的命名服务器。 |
| dns.resolvePtr(ip, callback) | 执行 DNS 解析以查找给定 IP 地址的 PTR 记录。返回结果是一个数组,包含与该 IP 地址关联的主机名。 |
| dns.resolveSrv(hostname, callback) | 执行 DNS 解析以查找给定主机名的 SRV 记录。返回结果是一个数组,包含提供特定服务的服务器的名称和端口号。 |
| dns.resolveTxt(hostname, callback) | 执行 DNS 解析以查找给定主机名的 TXT 记录。返回结果是一个数组,包含与该主机名关联的任意文本信息。 |
| dns.reverse(ip, callback) | 执行反向 DNS 查询以查找给定 IP 地址的主机名。返回结果是一个数组,包含与该 IP 地址关联的所有主机名。 |
options 参数是一个可选的对象,用于指定 DNS 查询的选项。该参数具有以下属性:
-
ttl(Time to Live):表示 DNS 查询结果的生存时间,以秒为单位。默认情况下,查询结果会被缓存一段时间,以减少对 DNS 服务器的负载。通过设置
ttl属性,可以控制查询结果的缓存时间。如果将ttl设置为0,则禁用缓存。 -
timeout:表示 DNS 查询的超时时间,以毫秒为单位。如果查询超过指定的超时时间仍未完成,将触发错误回调。默认超时时间为
0,表示无限制。 -
family:表示要查询的 IP 地址族(IPv4 或 IPv6)。可接受的值为
4或6。如果未指定此选项,则默认查询IPv4地址记录。 -
hints:表示查询期望返回的类型的提示。可接受的值为
dns.ADDRCONFIG、dns.V4MAPPED或dns.ALL。dns.ADDRCONFIG表示只返回与本地 IP 地址配置匹配的地址记录。dns.V4MAPPED表示返回IPv6地址记录时,同时返回映射到IPv4的地址记录。dns.ALL表示返回所有可能的地址记录。默认情况下,hints设置为dns.ADDRCONFIG。 -
all:表示是否返回所有符合查询条件的结果。默认情况下,只返回一个 IP 地址。如果将
all设置为true,则返回所有符合条件的 IP 地址。
需要注意的是,DNS解析是一个异步操作,所有的方法都接受一个回调函数作为最后一个参数,并使用回调函数来处理解析结果。
18.4 dns 模块中的错误代码
当进行 DNS 查询时,可能会返回错误代码以指示查询过程中发生的问题。以下是一些常见的 dns 模块中的错误代码:
-
dns.NODATA:表示没有找到与查询匹配的数据。
-
dns.FORMERR:表示 DNS 查询格式错误。
-
dns.SERVFAIL:表示 DNS 服务器内部错误或服务不可用。
-
dns.NOTFOUND:表示找不到指定的域名。
-
dns.NOTIMP:表示 DNS 服务器不支持请求的操作。
-
dns.REFUSED:表示 DNS 服务器拒绝了请求。
-
dns.BADQUERY:表示 DNS 查询格式错误。
-
dns.BADNAME:表示域名格式错误。
这些错误代码可用于在处理 DNS 查询时判断查询结果的状态,根据不同的错误代码采取相应的处理逻辑。在使用 dns 模块进行 DNS 查询时,可以根据需要捕获和处理这些错误代码来确保 DNS 查询的准确性和稳定性。
总结
通过使用 dns 模块,可以方便地进行 DNS 查询和解析,实现域名与 IP 地址之间的转换,以及获取其他 DNS 记录类型的信息。
19-其他模块
19.1 加密与解密
Node.js 的 crypto 模块是 Node.js 的核心模块之一,为开发者提供了一套完整的加密功能。该模块包括了用于OpenSSL散列、HMAC、加密、解密、签名以及验证的函数的封装。
在 crypto 模块中,包含了多种加密和解密的方式,如对称加密和非对称加密等。例如,你可以使用它进行哈希值的计算,或者使用HMAC进行数据的验证。同时,它还支持密码器和解密器的操作。
crypto.getCiphers() 是一个 Node.js 中的函数,用于获取当前系统支持的所有加密算法。它返回一个包含所有可用加密算法名称的数组。
以下是一个示例代码,演示如何使用 crypto.getCiphers() 函数
const crypto = require('crypto');
// 获取当前系统支持的所有加密算法
const ciphers = crypto.getCiphers();
console.log(ciphers);
crypto.getHashes() 是一个 Node.js 中的函数,用于获取当前系统支持的所有哈希算法。它返回一个包含所有可用哈希算法名称的数组。
以下是一个示例代码,演示如何使用 crypto.getHashes() 函数:
const crypto = require('crypto');
// 获取当前系统支持的所有哈希算法
const hashes = crypto.getHashes();
console.log(hashes);
19.1.1 随机数
在 Node.js 中,可以使用 crypto 模块来生成随机数和加密功能。下面我将介绍如何使用 crypto 模块生成随机数。
const crypto = require('crypto');
// 使用 crypto.randomBytes 方法可以生成具有指定字节数的随机数。例如,生成一个 16 字节(128 位)的随机数
const randomBytes = crypto.randomBytes(16);
console.log(randomBytes)
// randomBytes 是一个 Buffer 对象,如果需要将其转换为可读的字符串格式,可以使用 toString 方法,并指定编码格式。例如,将随机数转换为十六进制字符串:
const randomStringHex = randomBytes.toString('hex');
console.log(randomString)
// 可以将其转换为 base64 编码的字符串:
const randomString64 = randomBytes.toString('base64');
console.log(randomString64)
19.1.2 散列算法
散列算法,也称为哈希算法,是一种将任意长度的输入数据转换为固定长度输出(通常称为哈希值或摘要)的算法。这种转换是一种压缩映射,即哈希值的空间通常远小于输入的空间,可能存在不同的输入映射到相同的哈希值,这种情况称为冲突。
Node.js 提供了多种散列算法,包括MD5、SHA-1、SHA-256等。这些算法都是不可逆的,可以将任意长度的数据转换为固定长度的哈希值。
以下是 Node.js 中常用的散列算法:
-
MD5(Message-Digest Algorithm 5):将数据转换为一个128位的哈希值。由于其安全性较低,已经被证明存在漏洞,因此不建议在需要高安全性的场景中使用。
-
SHA-1(Secure Hash Algorithm 1):将数据转换为一个160位的哈希值。与MD5类似,SHA-1也存在安全问题,因此也不建议在需要高安全性的场景中使用。
-
SHA-256(Secure Hash Algorithm 256):将数据转换为一个256位的哈希值。SHA-256是目前最常用的安全哈希算法之一,被广泛应用于密码存储、数字签名等领域。
-
SHA-3(Secure Hash Algorithm 3):是SHA-2系列的第三个版本,将数据转换为一个224、256或384位的哈希值。SHA-3比SHA-2更安全,但目前还没有得到广泛的应用。
Node.js中,散列算法的常用方法主要包括 crypto 模块中的一些函数。以下是一些常用的散列方法:
-
crypto.createHash(algorithm):创建一个哈希对象,algorithm参数指定了使用的哈希算法,如
'sha256'、'md5'等。 -
hash.update(data, input_encoding):更新哈希对象的数据,data参数是要进行哈希计算的数据,input_encoding参数是数据的编码格式,如
'utf8'、'ascii'等。 -
hash.digest(output_encoding):计算哈希对象的哈希值,output_encoding参数是哈希值的编码格式,如
'hex'、'base64'等。
以下是一个使用SHA-256算法计算字符串哈希值的例子:
const crypto = require('crypto');
const hash = crypto.createHash('sha256');
hash.update('hello world', 'utf8');
console.log(hash.digest('hex')); // 输出哈希值的十六进制表示形式
此外,散列表(Hash Table)也是 Node.js 中常用的数据结构之一,它提供了快速的插入和取用操作。在散列表上插入、删除和取用数据是非常快的,但是对于查找操作来说却是效率低下。
19.1.3 HMAC
HMAC (Hash-based Message Authentication Code) 是一种基于哈希 HMAC HMAC(Hash-based Message Authentication Code)是一种基于哈希函数的消息认证码算法,用于验证消息的完整性和身份认证。在 Node.js 中,可以使用 crypto 模块提供的 createHmac() 方法来创建 HMAC 对象,并使用 update() 和 digest() 方法来计算HMAC值。
Node.js 中的 HMAC 算法的常用方法包括:
crypto.createHmac(algorithm, key):创建一个HMAC对象,并指定使用的哈希算法和密钥。
-
hmac.update(data):将数据添加到HMAC对象中。
-
hmac.digest(encoding):计算HMAC值,并以指定的编码格式输出。
-
hmac.final():结束计算HMAC值的过程,并将结果存储在内部缓冲区中。
-
hmac.copy(hmac):将一个HMAC对象的内容复制到另一个HMAC对象中。
-
hmac.reset():重置HMAC对象的状态,以便重新使用它。
-
hmac.setEncoding(encoding):设置HMAC对象的编码格式。
-
hmac.write(data):将数据写入HMAC对象中。
-
hmac.toString(encoding):将HMAC值转换为字符串,并以指定的编码格式输出。
-
hmac.toBuffer():将HMAC值转换为 Buffer 对象。
以下是一个简单的示例代码,演示如何使用 Node.js 中的HMAC算法:
const crypto = require('crypto');
// 定义密钥和消息
const secretKey = 'mysecretkey';
const message = 'Hello, world!';
// 创建HMAC对象,指定使用的哈希算法为SHA256
const hmac = crypto.createHmac('sha256', secretKey);
// 更新HMAC对象的数据
hmac.update(message);
// 计算HMAC值,并以十六进制字符串形式输出
console.log(hmac.digest('hex')); // 输出:'c8e4e9e0e7e8e9e0e7e8e9e0e7e8e9e0e7e8e9e0e7e8e9e0e7e8e9e0e7e8e9e'
在上面的示例中,我们首先引入了 crypto 模块,然后定义了一个密钥和一个消息。接着,我们使用 createHmac() 方法创建了一个 HMAC 对象,并指定了使用的哈希算法为 SHA256。然后,我们使用 update() 方法将消息添加到 HMAC 对象中。最后,我们使用 digest() 方法计算了 HMAC 值,并以十六进制字符串形式输出。
19.1.4 非对称加密
非对称加密是一种公钥加密算法,也被称为公钥密码学。与对称加密算法不同,非对称加密使用一对密钥:公钥和私钥。
公钥可以自由传播给其他人,而私钥必须严格保密。通过这对密钥,非对称加密算法可以实现以下功能:
- 加密:使用公钥加密数据。任何人都可以使用公钥对数据进行加密,但只有持有相应私钥的人才能解密。
- 解密:使用私钥解密数据。只有私钥的持有者才能使用私钥解密以公钥加密的数据。
- 数字签名:使用私钥对数据进行签名。私钥的持有者可以对数据进行签名,验证者可以使用公钥验证签名的真实性。
非对称加密算法的安全性基于数学上的难题,例如大数分解、离散对数等。常见的非对称加密算法包括RSA(Rivest-Shamir-Adleman)、DSA(Digital Signature Algorithm)和ECC(Elliptic Curve Cryptography)等。
在 Node.js 中,可以使用内置的 crypto 模块来实现非对称加密算法。crypto 模块提供了各种加密、解密、签名和验证等功能,包括 RSA 和 ECDSA 等非对称加密算法的实现。
下面详细介绍一下 crypto 模块中常用的非对称加密方法:
- crypto.generateKeyPair(type[, options], callback):生成公钥和私钥对。其中,type参数指定生成密钥对的算法,例如
'rsa'表示使用RSA算法,'ec'表示使用ECDSA算法。options参数为可选配置项,例如密钥长度、编码格式等。callback参数为生成密钥对完成后的回调函数,错误优先的回调风格(error-first callback)。
const crypto = require('crypto');
// 生成密钥对
crypto.generateKeyPair('rsa', {
modulusLength: 2048,
publicKeyEncoding: {
type: 'spki',
format: 'pem'
},
privateKeyEncoding: {
type: 'pkcs8',
format: 'pem'
}
}, (err, publicKey, privateKey) => {
if (err) {
console.error(err);
return;
}
console.log(publicKey);
console.log(privateKey);
});
- crypto.privateEncrypt(privateKey, data):使用私钥对数据进行加密。其中,privateKey参数为私钥,可以是PEM编码的字符串或者一个 Buffer 对象;data参数为需要加密的数据,可以是一个字符串或者一个 Buffer 对象。
// 私钥加密数据
const encryptedData = crypto.privateEncrypt(privateKey, Buffer.from('要加密的数据'));
console.log(encryptedData.toString('base64'));
- crypto.publicDecrypt(publicKey, encryptedData):使用公钥对数据进行解密。其中,publicKey参数为公钥,可以是PEM编码的字符串或者一个 Buffer 对象;encryptedData参数为加密后的数据,必须是一个 Buffer 对象。
// 公钥解密数据
const decryptedData = crypto.publicDecrypt(publicKey, encryptedData);
console.log(decryptedData.toString());
- crypto.sign(algorithm, data, privateKey[, format]):使用私钥对数据进行签名。其中,algorithm参数为签名算法,例如
'sha256'表示使用SHA-256算法;data参数为需要签名的数据,可以是一个字符串或者一个Buffer对象;privateKey参数为私钥,可以是PEM编码的字符串或者一个Buffer对象;format参数为可选参数,指定返回值的格式,默认为'buffer',也可以指定为'hex'、'base64'等。
// 数字签名
const sign = crypto.sign('sha256', Buffer.from('要签名的数据'), privateKey, 'hex');
console.log(sign);
- crypto.verify(algorithm, data, publicKey, signature[, format]):使用公钥验证数据的签名是否有效。其中,algorithm参数为签名算法,例如
'sha256'表示使用SHA-256算法;data参数为需要验证签名的数据,可以是一个字符串或者一个 Buffer 对象;publicKey参数为公钥,可以是PEM编码的字符串或者一个Buffer对象;signature参数为需要验证的签名,可以是一个字符串或者一个Buffer对象;format参数为可选参数,指定签名的格式,默认为'buffer',也可以指定为'hex'、'base64'等。
// 验证签名
const isValidSignature = crypto.verify('sha256', Buffer.from('需要验证的数据'), publicKey, sign, 'hex');
console.log(isValidSignature);
注意:
1. 使用公钥加密就需要私钥解密,使用私钥加密就必须使用公钥解密。
2. createCipher已被标记为不推荐使用,并在 Node.js 版本16.0中被移除。
使用这些方法可以实现非对称加密、解密和数字签名等功能。同时,由于非对称加密算法的安全性较高,建议在实际应用中选择合适的算法和密钥长度,以确保应用的安全性。
19.2 压缩与解压缩
zlib 模块是 Node.js 内置的压缩模块,它提供了多种压缩和解压缩算法,并且可以用于对数据进行流式压缩和解压缩。下面我们将详细介绍zlib模块的主要方法。
19.2.1 zlib.deflate(buf, [options], callback)
使用DEFLATE算法对buf数据进行压缩。options对象可以指定压缩级别(默认值为 zlib.constants.Z_DEFAULT_COMPRESSION),以及其他一些参数,例如内存限制、字典等。callback函数接收两个参数:err和buffer,其中buffer参数包含压缩后的数据。
const zlib = require('zlib');
const input = Buffer.from('hello world');
zlib.deflate(input, (err, buffer) => {
if (!err) {
console.log(buffer); // <Buffer 78 9c cb c9 2f 4a cd 55 c8 2c 28 56 00 01 61>
}
});
19.2.2 zlib.deflateRaw(buf, [options], callback)
使用DEFLATE算法对buf数据进行原始压缩,不带gzip文件头和尾。options对象可以指定压缩级别(默认值为 zlib.constants.Z_DEFAULT_COMPRESSION),以及其他一些参数,例如内存限制、字典等。callback函数接收两个参数:err 和 buffer,其中buffer参数包含压缩后的数据。
const zlib = require('zlib');
const input = Buffer.from('hello world');
zlib.deflateRaw(input, (err, buffer) => {
if (!err) {
console.log(buffer); // <Buffer cb c9 2f 4a cd 55 c8 2c 28 56 00>
}
});
19.2.3 zlib.inflate(buf, [options], callback)
对使用DEFLATE算法压缩的buf数据进行解压缩。options对象可以指定解压缩参数,例如内存限制、字典等。callback函数接收两个参数:err 和 buffer,其中buffer参数包含解压缩后的数据。
const zlib = require('zlib');
const input = Buffer.from('eJwryczLLSjJzy/KSQEAGwwK');
zlib.inflate(input, (err, buffer) => {
if (!err) {
console.log(buffer.toString()); // hello world
}
});
19.2.4 zlib.inflateRaw(buf, [options], callback)
对使用DEFLATE算法进行原始压缩的buf数据进行解压缩,不带gzip文件头和尾。options对象可以指定解压缩参数,例如内存限制、字典等。callback函数接收两个参数:err 和 buffer,其中buffer参数包含解压缩后的数据。
const zlib = require('zlib');
const input = Buffer.from('cb c9 2f 4a cd 55 c8 2c 28 56 00', 'hex');
zlib.inflateRaw(input, (err, buffer) => {
if (!err) {
console.log(buffer.toString()); // hello world
}
});
19.2.5 zlib.createGzip([options])
创建一个gzip压缩流对象,可用于对数据进行流式压缩。options对象可以指定压缩级别(默认值为 zlib.constants.Z_DEFAULT_COMPRESSION)和内存限制等参数。
const zlib = require('zlib');
const fs = require('fs');
const input = fs.createReadStream('input.txt');
const output = fs.createWriteStream('input.txt.gz');
input.pipe(zlib.createGzip()).pipe(output);
19.2.6 zlib.createGunzip([options])
创建一个 gzip 解压流对象,可用于对 gzip 格式的数据进行流式解压。options对象可以指定内存限制等参数。
const zlib = require('zlib');
const fs = require('fs');
const input = fs.createReadStream('input.txt.gz');
const output = fs.createWriteStream('input.txt');
input.pipe(zlib.createGunzip()).pipe(output);
19.2.7 zlib.createDeflate([options])
创建一个DEFLATE压缩流对象,可用于对数据进行流式压缩。options对象可以指定压缩级别(默认值为 zlib.constants.Z_DEFAULT_COMPRESSION)和内存限制等参数。
const zlib = require('zlib');
const fs = require('fs');
const input = fs.createReadStream('input.txt');
const output = fs.createWriteStream('input.txt.deflate');
input.pipe(zlib.createDeflate()).pipe(output);
19.2.8 zlib.createInflate([options])
创建一个DEFLATE解压流对象,可用于对使用DEFLATE算法压缩的数据进行流式解压。options对象可以指定内存限制等参数。
const zlib = require('zlib');
const fs = require('fs');
const input = fs.createReadStream('input.txt.deflate');
const output = fs.createWriteStream('input.txt');
input.pipe(zlib.createInflate()).pipe(output);
下面是 options 参数的详细介绍:
-
level:指定压缩级别,默认值为
zlib.constants.Z_DEFAULT_COMPRESSION。可以使用以下常量:- zlib.constants.Z_NO_COMPRESSION:不进行压缩。
- zlib.constants.Z_BEST_SPEED:最快速度的压缩。
- zlib.constants.Z_BEST_COMPRESSION:最佳压缩率,但速度较慢。
- zlib.constants.Z_DEFAULT_COMPRESSION:默认压缩级别。
- 0-9:数字越大,压缩级别越高。
-
memLevel:指定内存使用级别,默认值为
zlib.constants.Z_DEFAULT_MEMLEVEL。可以使用以下常量:- zlib.constants.Z_DEFAULT_MEMLEVEL:默认内存使用级别。
- 1-9:数字越大,内存使用越高。
-
strategy:指定压缩策略,默认值为
zlib.constants.Z_DEFAULT_STRATEGY。可以使用以下常量:- zlib.constants.Z_DEFAULT_STRATEGY:默认压缩策略。
- zlib.constants.Z_FILTERED:使用滤波器策略。
- zlib.constants.Z_HUFFMAN_ONLY:只使用Huffman编码策略。
- zlib.constants.Z_RLE:只使用游程编码策略。
- zlib.constants.Z_FIXED:只使用固定字典策略。
-
chunkSize:指定内部缓冲区的大小,默认值为
16 * 1024(16KB)。 -
windowBits:指定窗口大小,默认值为
zlib.constants.Z_DEFAULT_WINDOWBITS。可以使用以下常量:- zlib.constants.Z_DEFAULT_WINDOWBITS:默认窗口大小。
- -8:窗口大小为最小值。
- -15:窗口大小为最大值。
-
strategy:指定压缩策略,默认值为
zlib.constants.Z_DEFAULT_STRATEGY。可以使用以下常量:- zlib.constants.Z_DEFAULT_STRATEGY:默认压缩策略。
- zlib.constants.Z_FILTERED:使用滤波器策略。
- zlib.constants.Z_HUFFMAN_ONLY:只使用Huffman编码策略。
- zlib.constants.Z_RLE:只使用游程编码策略。
- zlib.constants.Z_FIXED:只使用固定字典策略。
- flush:指定刷新模式,默认值为zlib.constants.Z_NO_FLUSH。可以使用以下常量:
- zlib.constants.Z_NO_FLUSH:不刷新。
- zlib.constants.Z_PARTIAL_FLUSH:部分刷新。
- zlib.constants.Z_SYNC_FLUSH:同步刷新。
- zlib.constants.Z_FULL_FLUSH:完全刷新。
- zlib.constants.Z_FINISH:完成压缩。
以上就是zlib模块主要方法的介绍,该模块提供了多种压缩和解压缩算法,并且可以用于对数据进行流式压缩和解压缩,非常实用。
19.2.9 HTTP服务器里面压缩数据
当在HTTP服务器中传输数据时,可以使用压缩来减少传输的数据量,提高传输效率。以下是一个使用 Node.js 创建HTTP服务器并在其中压缩数据的示例代码:
const http = require('http');
const zlib = require('zlib');
const fs = require('fs');
// 创建一个HTTP服务器
const server = http.createServer((req, resp) => {
// 要被压缩的文件路径和名称
const filePath = 'test.txt';
// 获取文件的可读流
const readStream = fs.createReadStream(filePath);
// 设置响应头,表明服务器将发送经过gzip压缩的数据
res.writeHead(200, {
'Content-Type': 'text/plain',
'Content-Encoding': 'gzip'
});
// 创建一个gzip压缩流
const gzip = zlib.createGzip();
// 管道:读取文件 -> 压缩 -> 响应
readStream.pipe(gzip).pipe(resp);
// 监听压缩过程的事件
gzip.on('error', err => {
console.error(err);
});
});
// 监听端口
const PORT = 3000;
server.listen(PORT, () => {
console.log(`Server is running at http://localhost:${PORT}/`);
});
这段代码创建了一个HTTP服务器,当接收到请求时会将指定文件进行压缩并作为响应发送给客户端。在实际使用中,你可以根据需要添加其他的解压缩算法(如deflate)的支持,并根据自己的需求修改响应的Content-Type等内容。
19.2.10 HTTP请求并解压缩数据
当向HTTP服务器发送请求时,如果服务器返回的数据经过压缩,则客户端需要对其进行解压缩。以下是一个使用 Node.js 向HTTP服务器发送请求并解压缩响应数据的示例代码:
const http = require('http');
const zlib = require('zlib');
// 要请求的URL和请求头
const options = {
hostname: 'localhost',
port: 3000,
path: '/',
method: 'GET',
headers: {
'Accept-Encoding': 'gzip, deflate'
}
};
// 发送HTTP请求
const req = http.request(options, (resp) => {
const { statusCode, headers } = res;
// 检查响应头中是否包含压缩信息
const contentEncoding = headers['content-encoding'];
const writeStream = fs.createWriteStream("test.txt");
if (contentEncoding && contentEncoding.includes('gzip')) {
// 创建一个gzip解压缩流
const gunzip = zlib.createGunzip();
// 管道:响应 -> 解压缩 -> 控制台输出
//resp.pipe(gunzip).pipe(process.stdout);
// 管道:响应 -> 解压缩 -> 文件
resp.pipe(gunzip).pipe(writeStream);
} else if (contentEncoding && contentEncoding.includes('deflate')) {
// 创建一个deflate解压缩流
const inflate = zlib.createInflate();
// 管道:响应 -> 解压缩 -> 控制台输出
//resp.pipe(inflate).pipe(process.stdout);
// 管道:响应 -> 解压缩 -> 文件
resp.pipe(inflate).pipe(writeStream);
} else {
// 如果响应头中不包含压缩信息,则直接将响应输出到控制台
//resp.pipe(process.stdout);
// 如果响应头中不包含压缩信息,则直接将响应输出文件
resp.pipe(writeStream);
}
});
// 监听错误事件
req.on('error', error => {
console.error(error);
});
// 发送请求
req.end();
这段代码向指定的HTTP服务器发送了一个GET请求,并在响应中检查是否包含压缩信息,如果包含则对数据进行解压缩后输出到控制台或者是写入到程序的根目录。在实际使用中,你可以根据需要添加其他的解压缩算法(如deflate)的支持,并根据自己的需求修改请求的URL、请求头等内容。
19.3 readline
readline 模块是 Node.js 提供的内置模块之一,用于从可读流(如标准输入)中逐行读取数据。它提供了一个接口,可以监听用户的输入,并根据输入进行相应的处理。
19.3.1 创建 Interface 对象
Interface 是 readline 模块中的一个类,用于创建一个可以读取用户输入的接口,并构建交互式的命令行界面。
要使用 readline 模块,首先需要通过 require('readline') 引入该模块。然后,可以使用 createInterface(options) 方法创建一个 Interface 对象,该对象与指定的输入输出流相关联。
options 参数是一个包含以下属性的对象:
- input:指定输入流,可以是可读流(如
process.stdin)或文件流。默认值为process.stdin。 - output:指定输出流,可以是可写流(如
process.stdout)或文件流。默认值为process.stdout。 - prompt:指定命令行提示符。当调用
rl.prompt()方法时,会显示该提示符,并等待用户输入。默认值为'> '。 - completer:自动完成函数,用于为用户提供输入的自动补全建议。该函数接收两个参数:
line是用户输入的内容,callback是一个回调函数。回调函数应接受两个参数:err和result,其中result是一个包含建议的数组。默认值为null,表示禁用自动补全。 - terminal:指定终端模式。如果设置为
true,则终端会根据需要适应窗口大小和光标移动。如果设置为false,则终端将被视为非交互式,即不会自动换行或调整窗口大小。默认值为false。
const readline = require('readline');
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
在上面的示例中,我们通过 createInterface 方法创建了一个 Interface 对象,并将其关联到 process.stdin 和 process.stdout,分别表示标准输入和标准输出。
19.3.2 提问用户并获取输入
一旦创建了 Interface 对象,我们可以使用 question 方法向用户提问,并在用户输入回答后执行回调函数。
rl.question('What is your name? ', (name) => {
console.log(`Hello, ${name}!`);
rl.close();
});
在上面的示例中,我们使用 rl.question 方法向用户提问,并传入一个字符串作为提示信息。当用户输入回答后,回调函数将被调用,其中的参数 name 将包含用户输入的内容。在这个简单的示例中,我们将用户输入的内容打印到控制台。
下面是一个更完整的示例,演示了如何使用 readline 模块构建一个简单的命令行计算器:
const readline = require('readline');
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
rl.question('Enter the first number: ', (num1) => {
rl.question('Enter the second number: ', (num2) => {
const result = Number(num1) + Number(num2);
console.log(`The result is: ${result}`);
rl.close();
});
});
在这个示例中,我们首先向用户提问要求输入两个数字。然后,通过将用户输入转换为数字类型,计算并输出结果。
19.3.3 Interface 对象的方法和事件
Interface 对象提供了一些方法和事件,用于处理用户输入和输出。以下是 Interface 对象的一些常用方法:
-
rl.question(query, callback):向用户提出问题,并等待用户输入。当用户输入完成后,将调用回调函数,并将用户输入作为参数传递给回调函数。
rl.question('What is your name? ', (name) => { console.log(`Hello, ${name}!`); rl.close(); }); -
rl.write(data, [key]):向输出流写入数据。可以使用
data参数指定要写入的内容,也可以使用 key 参数指定按下的键。rl.write('Hello, world!'); -
rl.prompt([preserveCursor]):显示提示符,并等待用户输入。如果
preserveCursor参数设置为true,则光标位置将保持不变。默认情况下,会根据需要自动调整窗口大小和光标位置。 -
rl.setPrompt(prompt):设置提示符。你可以使用此方法在用户输入之前显示一个自定义的提示符。
-
rl.pause():暂停读取输入流。你可以使用此方法来暂停用户输入,并执行一些其他操作。
-
rl.resume():恢复读取输入流。你可以使用此方法来恢复用户输入,并继续等待用户输入。
-
rl.close():关闭 Interface 对象。这将结束输入流,并触发 ‘close’ 事件。
-
rl.on(event, callback):监听指定的事件,并在事件触发时执行回调函数。你可以使用此方法来处理用户输入和其他事件。
以下是 Interface 对象的一些常用事件:
-
‘line’:当用户输入完成一行文本时触发。回调函数将接收用户输入的文本作为参数。
-
‘pause’:当 Interface 对象暂停读取输入流时触发。例如,当用户按下
Ctrl + S(默认情况下)来暂停输入流时,此事件将被触发。 -
‘resume’:当 Interface 对象恢复读取输入流时触发。例如,当用户按下
Ctrl + Q(默认情况下)来恢复输入流时,此事件将被触发。 -
‘SIGINT’:当用户按下
Ctrl + C(默认情况下)来发送中断信号时触发。你可以监听此事件来处理用户中断操作。
-
const readline = require('readline');
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
rl.question('What is your name? ', (name) => {
console.log(`Hello, ${name}!`);
rl.prompt();
});
rl.on('line', (line) => {
console.log(`You entered: ${line}`);
});
rl.on('pause', () => {
console.log('Input stream paused');
});
rl.on('resume', () => {
console.log('Input stream resumed');
});
rl.on('SIGINT', () => {
rl.close();
});
// rl.on('close', callback) 方法在 Interface 对象被关闭时触发。当用户按下 Ctrl + D(或在 Windows 上是 Ctrl + Z)来结束输入流时,会触发 close 事件。
// 此外,你还可以调用 rl.close() 方法来关闭 Interface 对象,这也会触发 close 事件。
rl.on('close', () => {
console.log('Interface closed');
});
在这个示例中,我们创建了一个 Interface 对象,并使用 rl.question() 方法向用户提出问题。在回调函数中,我们打印出带有用户姓名的欢迎消息,并调用 rl.prompt() 方法以显示提示符,并等待用户输入。
我们还监听了 'line' 事件,在用户输入一行文本后执行回调函数,打印出用户输入的内容。
我们还监听了 'pause' 和 'resume' 事件,在输入流暂停和恢复时执行相应的回调函数。
最后,我们监听了 'SIGINT' 事件,以处理用户按下 Ctrl + C 的中断操作。在回调函数中,我们调用 rl.close() 方法来关闭 Interface 对象。
当用户完成输入并按下回车键后,'line' 事件将被触发,在回调函数中打印出用户输入的内容。当用户按下 Ctrl + C 来中断操作时,'SIGINT' 事件将被触发,并关闭 Interface 对象。在 Interface 对象关闭后,‘close’ 事件将被触发,在回调函数中打印出相应的消息。
readline 模块非常适合用于开发命令行工具、交互式应用程序和命令行界面。它简化了处理用户输入的过程,使得开发者可以更轻松地构建交互式的命令行界面。你可以根据需要使用 readline 模块提供的方法来满足自己的需求。
19.4 punycode
Punycode 模块是 Node.js 内置的一个模块,用于处理 Punycode 编码和解码。它提供了一些方法,可以将国际化域名(IDN)转换为 ASCII 字符串(Punycode 编码),以及将 Punycode 编码的字符串解码回原始的 Unicode 字符序列。
下面是 Punycode 模块提供的主要方法:
-
punycode.encode(domain):将给定的域名字符串编码为 Punycode 编码的字符串。如果域名中包含非 ASCII 字符,则会对其进行编码。返回编码后的字符串。
-
punycode.decode(domain):将给定的 Punycode 编码的域名字符串解码为原始的 Unicode 字符串。如果输入字符串不是有效的 Punycode 编码字符串,则会抛出一个错误。返回解码后的字符串。
-
punycode.toASCII(domain):将给定的域名字符串转换为 ASCII 字符串,包括对非 ASCII 字符的 Punycode 编码。返回转换后的 ASCII 字符串。
-
punycode.toUnicode(domain):将给定的 Punycode 编码的域名字符串转换回原始的 Unicode 字符串。返回转换后的 Unicode 字符串。
这些方法可以帮助你在处理国际化域名时进行编码和解码操作。以下是一些示例使用:
const domain = '中国.com';
const encodedDomain = punycode.encode(domain);
console.log(encodedDomain); // 输出: "xn--fiqs8s.com"
const decodedDomain = punycode.decode(encodedDomain);
console.log(decodedDomain); // 输出: "中国.com"
const asciiDomain = punycode.toASCII(domain);
console.log(asciiDomain); // 输出: "xn--fiqs8s.com"
const unicodeDomain = punycode.toUnicode(asciiDomain);
console.log(unicodeDomain); // 输出: "中国.com"
Punycode 模块是一个非常有用的工具,可用于在处理国际化域名时进行编码和解码操作,使其能够正确地与现有的域名系统进行交互和处理。
总结
Node.js 提供了丰富的工具模块,包括加解密、readline、punycode、压缩和解压缩等模块。下面对这些模块进行简要总结:
-
加解密模块:Node.js 提供了 crypto 模块用于加解密操作,包括对称加密(如 AES、DES)、非对称加密(如 RSA)和哈希算法(如 MD5、SHA-256)。使用 crypto 模块可以进行安全的数据传输和存储。
-
readline 模块:Node.js 的 readline 模块提供了一组 API,用于从标准输入流(stdin)读取数据,并在终端上输出提示信息和接收用户输入。它可以帮助我们方便地实现命令行交互式程序。
-
punycode 模块:Punycode 是一种编码方案,用于在互联网域名中表示非 ASCII 字符。Node.js 提供了 punycode 模块,可以将国际化域名(IDN)转换为 ASCII 字符串(Punycode 编码),以及将 Punycode 编码的字符串解码回原始的 Unicode 字符序列。
-
压缩和解压缩模块:Node.js 提供了 zlib 模块,用于对数据进行压缩和解压缩。zlib 模块支持 gzip、deflate 和 raw 三种压缩格式,可以帮助我们在网络传输和数据存储中节省带宽和存储空间。
这些模块是 Node.js 提供的核心模块,可以方便地使用 Node.js 进行加解密、读取用户输入、处理国际化域名、压缩和解压缩数据等操作。同时,Node.js 社区也提供了大量的第三方模块,可以扩展 Node.js 的功能,满足不同场景下的需求。
20-net
Node.js 的net模块是一个用于创建基于 TCP或 IPC(进程间通信)的网络服务器和客户端的核心模块。Node.js 提供了 net、dgram、http、https等模块,可用于处理 TCP、UDP、HTTP 和 HTTPS,适用于服务端和客户端。
net 模块主要包含以下几个核心类和方法:
-
net.createServer([options], [connectionListener]):用于创建一个 TCP 服务器。接受一个可选的options对象,用于配置服务器参数,例如指定服务器的本地地址、端口等。connectionListener是一个回调函数,用于处理每个新连接的客户端。
-
server.listen(port, [host], [backlog], [callback]):用于将服务器绑定到指定的主机和端口,并开始监听连接。port是要监听的端口号,host是可选的本地地址,默认为
'0.0.0.0',表示监听所有可用的网络接口。backlog是可选的参数,表示在拒绝连接之前,操作系统可以挂起的最大连接数,默认为511。callback是一个可选的回调函数,用于在服务器开始监听时触发。 -
server.close([callback]):关闭服务器,停止接受新的连接。callback是一个可选的回调函数,在服务器完全关闭后触发。
-
server.getConnections(callback):获取当前服务器的连接数量。callback是一个回调函数,它的参数是当前的连接数。
-
server.address():返回服务器的地址信息,包括address(IP地址)和port(端口号)。
-
server.maxConnections:一个数值属性,表示服务器允许的最大连接数。
-
server.on(event, callback):用于监听服务器的事件。常见的事件有
'listening'(服务器开始监听时触发)、'connection'(新连接建立时触发)、'close'(服务器关闭时触发)、'error'(服务器发生错误时触发)等。 -
net.createConnection(options, [connectionListener]):创建一个TCP或IPC的客户端连接。options是一个对象,包含要连接的服务器的地址和端口等信息。connectionListener是一个回调函数,用于处理连接建立后的操作。
-
socket.write(data, [encoding], [callback]):向连接的另一端发送数据。data是要发送的数据,可以是字符串或Buffer对象。encoding是可选的字符编码,默认为’utf-8’。callback是一个可选的回调函数,在数据写入底层操作系统缓存后触发。
-
socket.end([data], [encoding]):关闭连接。可以选择性地发送最后一次数据,并在数据发送完成后关闭连接。
-
socket.destroy():强制关闭连接,不会发送任何额外的数据。
20.1 TCP
TCP 服务在网络服务中非常的常见,目前大多数的应用都是基于 TCP 搭建而成的。
TCP(传输控制协议)是一种面向连接的、可靠的、基于字节流的网络传输协议。它在OSI模型中属于传输层协议,很多应用层协议都是基于 TCP 构建的,例如:HTTP、SMTP、IMAP 等协议。它是互联网中最常用的传输协议之一,广泛应用于各种网络应用程序,如网页浏览、电子邮件、文件传输等。
20.1.1 TCP服务端
Node.js 是一个基于事件驱动、非阻塞I/O模型的 JavaScript 运行时环境,它提供了 net 模块用于创建 TCP 服务器和客户端。
要创建一个 TCP 服务端,我们可以使用 Node.js 的 net 模块。下面是一个简单的示例:
server.js
const net = require('net');
// 创建TCP服务器
const server = net.createServer((socket) => {
// 当有新的客户端连接时触发
console.log('客户端已连接');
// 监听客户端发送的数据
socket.on('data', (data) => {
console.log('接收到客户端数据:', data.toString());
// 向客户端发送数据
socket.write('Hello Client!');
});
// 监听客户端断开连接事件
socket.on('end', () => {
console.log('客户端已断开连接');
});
});
// 监听指定端口和主机地址
const PORT = 3000;
const HOST = '127.0.0.1';
server.listen(PORT, HOST, () => {
console.log(`TCP服务器运行在:${HOST}:${PORT}`);
});
在上面的示例中,我们首先引入了 net 模块,然后使用 createServer 方法创建了一个 TCP 服务器。这个方法接受一个回调函数作为参数,该函数会在每次有新的客户端连接时被调用。在回调函数中,我们可以处理客户端的请求和数据。
通过使用 socket 对象,我们可以监听客户端发送的数据(通过data事件),向客户端发送数据(通过write方法),以及监听客户端断开连接事件(通过end事件)。
最后,我们使用 listen 方法指定服务器要监听的端口和主机地址。在本例中,我们将服务器运行在本地的3000端口上。
20.1.2 TCP客户端
Node.js 提供了 net 模块,可以用于创建 TCP 客户端。下面是一个简单的示例:
const net = require('net');
// 创建TCP客户端
const client = net.createConnection({ port: 3000, host: '127.0.0.1' }, () => {
console.log('已连接到TCP服务器');
// 向服务端发送数据
client.write('Hello Server!');
});
// 监听从服务端接收的数据
client.on('data', (data) => {
console.log('接收到TCP服务端数据:', data.toString());
// 关闭与服务端的连接
client.end();
});
// 监听与服务端断开连接事件
client.on('end', () => {
console.log('与TCP服务端断开连接');
});
在上面的示例中,我们首先引入了 net 模块,然后使用 createConnection 方法创建了一个 TCP 客户端连接。该方法接受一个配置对象作为参数,其中包含要连接的服务器的端口和主机地址。在连接成功时,回调函数会被调用。
通过 client 对象,我们可以向服务端发送数据(通过 write 方法),监听从服务端接收的数据(通过 data 事件),以及监听与服务端断开连接的事件(通过 end 事件)。
在本例中,我们连接到本地的3000端口上的服务器。当连接成功后,我们向服务端发送了一条数据,并监听从服务端返回的数据。最后,我们在与服务端断开连接时输出相应的消息。
20.1.3 测试TCP客户端和服务端
-
我们先打开一个命令行工具,然后调用
node server.js命令启动一个服务端应用,启动监听3000端口。
图1 运行TCP服务端 server.js
-
我们再打开一个命令行工具,然后调用
node client.js命令并按回车键使用客户端去访问server.js这个服务端应用,我们可以看到服务端返回给客户端的数据。
图2 运行TCP客户端 client.js
-
再看看服务端收到了客户端的请求,以及发送的数据。
图3 TCP服务端收到客户端的反馈消息
请注意你自己的 server.js 和 client.js 的所在地址。
20.2 UDP
UDP(User Datagram Protocol)是一种无连接的传输层协议,它提供了一种简单的数据传输机制,适用于那些对数据可靠性要求较低但速度要求较高的场景。与 TCP 不同,UDP 不保证数据的可靠传输和顺序交付,也不提供拥塞控制和流量控制。
在 Node.js 中,可以使用 dgram 模块进行 UDP 通信。该模块提供了创建 UDP 套接字、发送和接收 UDP 数据包的功能。
dgram模块主要提供了以下几个方法和事件:
-
dgram.createSocket(type, [callback]):创建一个UDP套接字,其中type参数指定套接字类型,可以是udp4或udp6。可选的callback函数在套接字绑定后会被调用。
-
socket.send(msg, [offset, length, port, address], [callback]):向指定地址和端口发送UDP数据包。msg参数是一个Buffer或Uint8Array,用于存储要发送的数据。offset和length参数可用于指定要发送的数据在msg中的位置和长度。port和address参数分别指定目标服务器的端口和IP地址。可选的callback函数在数据包发送完成后会被调用。
-
socket.bind([port], [address], [callback]):将套接字绑定到指定的端口和IP地址上。可选的port和address参数用于指定要绑定的端口和IP地址。可选的callback函数在绑定完成后会被调用。
-
socket.close([callback]):关闭套接字。可选的callback函数在套接字关闭完成后会被调用。
-
socket.on(‘message’, callback):监听message事件,当收到UDP数据包时触发回调函数。回调函数的参数包括接收到的数据和发送方的信息。
-
socket.on(‘error’, callback):监听error事件,当套接字发生错误时触发回调函数。回调函数的参数为错误对象。
20.2.1 UDP服务端
在 Node.js 中,可以使用 dgram 模块创建 UDP 服务器。以下是一个简单的示例:
server.js
const dgram = require('dgram');
// 创建UDP服务器
const server = dgram.createSocket('udp4');
// 监听消息事件
server.on('message', (msg, remote) => {
console.log(`接收到来自 ${remote.address}:${remote.port} 的消息: ${msg}`);
// 向客户端发送响应
const responseMsg = Buffer.from('Hello Client!');
server.send(responseMsg, 0, responseMsg.length, remote.port, remote.address, (err, bytes) => {
if (err) {
console.error('发送响应时发生错误:', err);
} else {
console.log(`已向客户端 ${remote.address}:${remote.port} 发送响应`);
}
});
});
// 监听错误事件
server.on('error', (err) => {
console.error('UDP服务器发生错误:', err);
server.close();
});
// 监听服务器启动事件
server.on('listening', () => {
const address = server.address();
console.log(`UDP服务器运行在:${address.address}:${address.port}`);
});
// 指定服务器要监听的端口和主机地址
const PORT = 3000;
const HOST = '127.0.0.1';
server.bind(PORT, HOST);
在上面的示例中,我们首先引入了 dgram 模块,然后使用 createSocket 方法创建了一个 UDP 服务器。该方法接受一个参数指定要使用的IP协议版本,例如 udp4 表示 IPv4。
通过监听 message 事件,我们可以获取到客户端发送的消息以及客户端的地址和端口信息。在回调函数中,我们可以处理接收到的消息,并向客户端发送响应。
通过监听 error 事件,我们可以处理服务器发生的错误,并在错误发生时关闭服务器。
通过监听 listening 事件,我们可以获取服务器实际绑定的地址和端口信息,并在服务器启动时进行相应的输出。
最后,我们使用 bind 方法指定服务器要监听的端口和主机地址,并开始监听 UDP 连接。
20.2.2 UDP客户端
在 Node.js 中,可以使用 dgram 模块创建 UDP 客户端。UDP 客户端可以发送 UDP 数据包到指定的服务器,并接收服务器返回的响应
以下是一个简单的 UDP 客户端示例:
client.js
const dgram = require('dgram');
// 创建UDP套接字
const client = dgram.createSocket('udp4');
// 监听消息事件
client.on('message', (msg, remote) => {
console.log(`接收到来自UDP服务器的消息: ${msg}`);
// 关闭客户端
client.close();
});
// 监听错误事件
client.on('error', (err) => {
console.error('发生错误:', err);
// 关闭客户端
client.close();
});
// 定义服务器地址和端口
const serverPort = 3000;
const serverHost = '127.0.0.1';
// 发送消息给服务器
const message = Buffer.from('Hello Server!');
client.send(message, 0, message.length, serverPort, serverHost, (err, bytes) => {
if (err) {
console.error('发送消息时发生错误:', err);
// 关闭客户端
client.close();
} else {
console.log(`已向UDP服务器 ${serverHost}:${serverPort} 发送消息`);
}
// 关闭客户端
//client.close();
});
在上述示例中,我们首先引入了 dgram 模块,然后使用 createSocket 方法创建了一个 UDP 套接字。
通过监听 message 事件,我们可以获取到服务器返回的消息以及服务器的地址和端口信息。在回调函数中,我们可以处理接收到的消息。
通过监听 error 事件,我们可以处理 UDP 客户端发生的错误,并在错误发生时关闭 UDP 套接字。
接下来,我们定义了服务器的地址和端口,并使用 send 方法发送 UDP 数据包到服务器。在回调函数中,我们可以处理发送数据包时发生的错误。
最后,我们使用 close 方法关闭 UDP 套接字。
需要注意的是,UDP 是无连接的,因此客户端可以在任何时候发送数据包,而不需要事先建立连接。这也意味着在 UDP 通信中,不保证数据包的可靠传输和顺序交付。
20.2.3 测试UDP客户端和服务端
-
同样的,我们先打开一个命令行工具,然后调用
node server.js命令启动一个服务端应用,启动监听3000端口。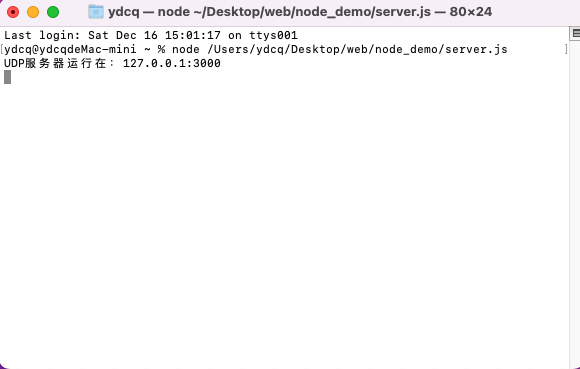
图4 运行UDP服务端 server.js
-
然后再打开一个命令行工具,然后调用
node client.js命令并按回车键使用客户端去访问server.js这个服务端应用,我们可以看到服务端返回给客户端的数据。
图5 运行UDP客户端 client.js
-
最后服务端也收到了客户端的请求以及数据。
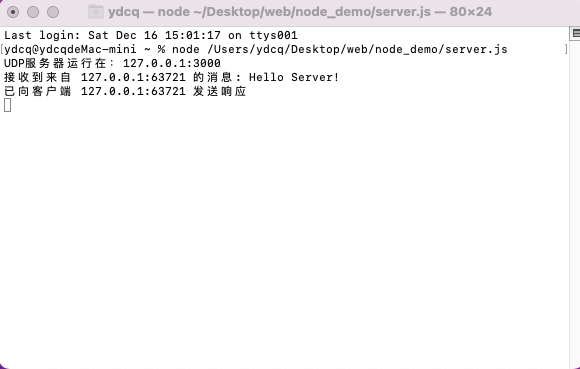
图6 UDP服务端收到客户端的反馈消息
请注意你自己的 server.js 和 client.js 的所在地址。
总结
Node.js 的 net 模块是一个内置模块,用于创建基于网络的服务器和客户端应用程序。它提供了一些函数和类,可用于实现 TCP 和 IPC(进程间通信)的网络通信。无论是构建 Web 服务器、聊天应用程序还是实现自定义的网络协议,net 模块都是一个强大且灵活的工具。
21-http
HTTP (Hypertext Transfer Protocol) 是一种用于传输超文本的应用层协议。它是构建在 TCP/IP 协议之上的,常用于Web应用中进行客户端和服务器之间的通信。
HTTP在Web应用中扮演着重要的角色,它使得浏览器能够向服务器请求网页并获取资源,也使得服务器能够向客户端发送数据和响应。通过HTTP,我们可以进行网页浏览、数据传输、API调用等各种Web应用场景。
21.1 http模块的常用方法
http 模块是 Node.js 内置的一个核心模块,用于创建基于 HTTP协议的网络服务器和客户端。它提供了一组API,使得在 Node.js 环境下可以轻松地实现 HTTP服务器和客户端功能。
以下是 Node.js 的 http 模块的一些详细介绍:
-
创建HTTP服务器:
- http.createServer([requestListener]):该方法用于创建一个HTTP服务器。接受一个可选的请求处理函数作为参数,该函数会在每个收到的请求上被调用。返回一个
http.Server对象。
- http.createServer([requestListener]):该方法用于创建一个HTTP服务器。接受一个可选的请求处理函数作为参数,该函数会在每个收到的请求上被调用。返回一个
-
HTTP服务器事件:
- request:当有新请求到达服务器时触发该事件。回调函数会接收到一个
http.IncomingMessage对象和一个http.ServerResponse对象,用于处理请求和发送响应。 - connection:当新的TCP连接建立时触发该事件。
- close:当服务器关闭时触发该事件。
- request:当有新请求到达服务器时触发该事件。回调函数会接收到一个
-
HTTP请求对象(http.IncomingMessage):
- req.url:获取请求的URL。
- req.method:获取请求的HTTP方法。
- req.headers:获取请求头。
- req.on(event, callback):监听请求对象的事件,如’data’、'end’等。
-
HTTP响应对象(http.ServerResponse):
- res.statusCode:设置响应的状态码。
- res.setHeader(name, value):设置响应头。
- res.write(data, [encoding], [callback]):将数据写入响应体。
- res.end([data], [encoding], [callback]):结束响应并发送给客户端。
-
创建HTTP客户端请求:
- http.request(options, [callback]):创建一个HTTP客户端请求。接受一个配置对象作为参数,用于指定请求的URL、方法、头部等信息。返回一个
http.ClientRequest对象。 - http.get(options, [callback]):与
http.request()类似,但使用GET方法,并自动调用req.end()。
- http.request(options, [callback]):创建一个HTTP客户端请求。接受一个配置对象作为参数,用于指定请求的URL、方法、头部等信息。返回一个
-
HTTP客户端请求对象(http.ClientRequest):
- req.write(chunk, [encoding], [callback]):将数据写入请求体。
- req.end([data], [encoding], [callback]):结束请求并发送给服务器。
除了上述的基本功能外,http 模块还提供了其他一些重要特性和方法,如:
- 在服务器中处理路由和URL路径。
- 支持 HTTPS 协议,通过 https 模块可以创建安全的 HTTPS 服务器和客户端。
- 支持 WebSocket 协议,通过 upgrade 事件可以将 HTTP 协议升级到 WebSocket。
- 支持代理服务器,可以实现反向代理和负载均衡等功能。
Node.js 的 http 模块非常强大且灵活,适用于构建各种类型的网络应用程序,包括Web服务器、API服务器、代理服务器等。它使得处理 HTTP 请求和响应变得简单高效。
21.2 HTTP服务端
通过使用 Node.js 的内置 http 模块的 http.createServer() 方法,开发者可以轻松地构建HTTP服务器,监听HTTP请求并响应客户端请求。
server.js
// 导入http模块
const http = require('http');
// 创建服务器
const server = http.createServer((req, res) => {
// 处理HTTP请求逻辑
if (req.method === 'GET' && req.url === '/') {
// 发送 HTTP 头部
// HTTP 状态码:200: OK
// 内容类型:text/plain
res.writeHead(200, {'Content-Type': 'text/plain'});
// 发送响应数据:'Hello, World!'
res.write('Hello, World!');
res.end();
} else {
// 其他请求路径访问为404
res.writeHead(404, {'Content-Type': 'text/plain'});
res.write('404 Not Found\n');
res.end();
}
});
//// 处理HTTP请求和发送响应
//server.on('request', (req, res) => {
// // 处理HTTP请求逻辑
//});
const port = 3000;
// 监听HTTP请求
server.listen(port, () => {
console.log(`Server running at http://localhost:${port}/`);
});
以上代码创建了一个简单的HTTP服务器,当请求根路径 / 时,返回一个包含 "Hello, World!";对于其他路径,返回 404 错误。
这只是 Node.js 的HTTP服务端的基本使用方式。你可以通过使用框架(如Express、Koa)来简化路由、中间件等功能的开发。另外,还可以使用其他第三方模块来处理更复杂的需求,如身份验证、数据解析等。
21.3 HTTP客户端
Node.js 提供了内置的 http 模块,可以用于创建HTTP客户端。使用 http 模块可以发送HTTP请求并接收服务器返回的响应。
client.js
const http = require('http');
const options = {
hostname: '127.0.0.1',
port: 3000,
path: '/',
method: 'GET',
};
const req = http.request(options, (res) => {
let data = '';
res.on('data', (chunk) => {
data += chunk;
});
res.on('end', () => {
console.log("请求结束 data=", data);
});
});
req.on('error', (error) => {
console.error(error);
});
req.end();
你可以使用http.ClientRequest对象的abort方法终止本次请求
request.abort();
还可以通过 request.setTimeout(timeout, [callback]) 设置请求的超时间
21.4 测试HTTP服务端和客户端
-
我们先使用
node server.js命令启动HTTP服务端。
图1 运行HTTP服务端 server.js
-
在使用
node client.js命令启动客户端并访问服务端,然后拿到相应数据。
图2 运行HTTP客户端 client.js
请注意你自己的 server.js 和 client.js 的所在地址。
总结
Node.js 的 http 模块非常强大且灵活,适用于构建各种类型的网络应用程序,包括Web服务器、API服务器、代理服务器等。它使得处理HTTP请求和响应变得简单高效。
22-https
HTTPS (HyperText Transfer Protocol Secure) 是基于传输层安全协议(TLS/SSL)的HTTP协议,用于在客户端和服务器之间进行加密和安全通信。
在HTTPS通信中,客户端和服务器之间的通信数据是经过加密处理的,这使得通信过程中的数据不容易被窃听和篡改。为了实现HTTPS通信,服务器需要使用数字证书来验证自己的身份并提供公钥,客户端则使用公钥对数据进行加密,然后通过互联网发送给服务器。服务器使用私钥解密数据并进行相应的操作,然后将响应数据通过公钥进行加密,并发送回客户端。在整个过程中,客户端和服务器之间的通信数据都是加密和安全的。
与HTTP相比,HTTPS具有以下优点:
-
数据安全性:HTTPS使用加密机制保护通信过程中的数据,防止数据被窃听和篡改。
-
身份验证:HTTPS使用数字证书验证服务器的身份,确保客户端与真正的服务器进行通信。
-
排名优化:搜索引擎通常会更倾向于显示使用HTTPS协议的网站。
虽然HTTPS具有很多优点,但也存在一些缺点:
-
加密处理会增加服务器的处理负荷,对服务器的性能要求较高。
-
需要购买数字证书,增加了网站运营成本。
Node.js 的 https 模块是对 http 模块的扩展,用于创建和处理HTTPS服务器和客户端。它提供了以下功能:
-
创建HTTPS服务器:
https.createServer(options, requestListener)方法用于创建一个HTTPS服务器,并返回一个Server对象,可以使用listen()方法指定服务器监听的端口号和IP地址。 -
发送HTTPS请求:
https.get(options, callback)方法用于向HTTPS服务器发起GET请求,并返回一个http.ClientRequest对象,可以使用on('data')和on('end')等事件处理器接收响应数据。 -
处理HTTPS请求:
https.Server对象继承自http.Server对象,在request事件回调中,可以使用req.connection.encrypted属性判断是否为HTTPS连接,使用res.writeHead()方法设置响应头,使用res.write()和res.end()方法返回响应数据。 -
HTTPS选项:https 模块还提供了一个
globalAgent对象,可以设置全局的HTTPS代理选项,例如最大套接字数、证书验证等。 -
证书和密钥:HTTPS服务器需要使用证书和私钥来进行加密通信,
https.createServer()方法的第一个参数可以传入一个包含key和cert属性的对象或字符串,分别表示私钥和证书文件路径或内容。此外,还可以使用https.request(options, callback)方法的options参数指定证书和私钥等选项。
在 Node.js 的 https 模块中,options 参数用于配置HTTPS请求和服务器的选项。这个参数是一个包含各种配置选项的 JavaScript 对象。下面介绍一些常用的 options 参数及其作用:
- key: 指定服务器的私钥。可以是一个包含私钥内容的字符串,也可以是一个指向私钥文件路径的字符串。
- cert: 指定服务器的证书。可以是一个包含证书内容的字符串,也可以是一个指向证书文件路径的字符串。
- ca: 指定证书颁发机构(CA)的证书列表。可以是一个包含 CA 证书内容的字符串数组,也可以是一个指向包含 CA 证书的文件路径的字符串数组。
- pfx: 指定一个包含私钥、证书和 CA 的 PFX 或 PKCS12 格式文件的路径。
- passphrase: 如果私钥文件被密码保护,使用此选项提供密码。
- ciphers: 指定可接受的加密算法列表,用于在客户端和服务器之间协商加密算法。
- secureProtocol: 指定要使用的安全协议。默认为 SSLv23_method,支持多个安全协议(如 TLSv1、TLSv1.1、TLSv1.2)。
- servername: 指定 server 的名称,用于服务器名称指示(SNI)扩展。
- rejectUnauthorized: 指定是否拒绝未经验证的证书,默认为 true。设置为 false 可以允许使用自签名证书。
- requestCert: 指定是否要求客户端提供证书,默认为 false。
- agent: 指定一个代理对象,用于自定义 HTTPS 代理的行为。
22.1 TLS/SSL
TLS (Transport Layer Security) 和 SSL (Secure Sockets Layer) 是用于保护网络通信的协议。它们都是在TCP/IP 协议之上工作的安全层,用于加密和验证客户端和服务器之间的通信。SSL 最初由 Netscape 公司开发,后来被标准化为 TLS 1.0。
TLS/SSL 使用了公开密钥加密技术(Public Key Cryptography)来确保通信的机密性、完整性和身份验证。在 TLS/SSL 协议中,客户端和服务器通过握手协议建立连接并进行身份验证。一旦连接建立,双方就可以使用对称密钥加密技术(Symmetric Key Cryptography)来加密和解密数据。
TLS/SSL 协议提供了以下主要功能:
- 数据加密:使用加密算法将数据转换为不可读的形式,以确保数据在传输过程中不会被窃听或篡改。
- 身份验证:通过证书验证来确保通信双方的身份,防止假冒和中间人攻击。
- 完整性保护:使用消息认证码(MAC)来确保数据在传输过程中不会被篡改。
- 抗重放攻击:使用时间戳和随机数等机制来防止攻击者使用已经传输过的数据来进行攻击。
在应用程序中使用 TLS/SSL 协议时,需要注意以下几点:
- 证书管理:使用受信任的证书颁发机构颁发的证书来确保通信的安全性。
- 协议版本:选择支持较新版本的协议,以获得更好的安全性和功能。
- 密钥管理:定期更换密钥,以防止密钥泄漏或被破解。
- 配置安全性:配置加密算法、密钥长度、身份验证方式等参数,以确保通信的安全性。
总之,TLS/SSL 协议是保护网络通信的重要协议,应用广泛。在实际使用中,需要合理配置和管理,以确保通信的安全性。
22.2 生成签名证书
创建HTTPS服务器之前,我们需要先创建好 公钥、私钥 及 证书。要生成HTTPS签名证书,你可以遵循以下步骤:
-
生成私钥(Private Key):
使用以下命令在终端中生成私钥文件(例如private.key):
# 这将生成一个1024位的RSA私钥。 openssl genrsa -out private.key 1024 -
生成证书签名请求(Certificate Signing Request,简称CSR):
使用以下命令生成CSR文件(例如csr.pem),其中common_name是你的域名:
openssl req -new -key private.key -out csr.pem在此过程中,你将需要提供一些相关信息,如组织名称、所在国家/地区、电子邮件地址等。这些信息将用于生成证书。
-
提交CSR并获取证书:
将生成的CSR文件提交给可信任的证书颁发机构(Certification Authority,简称CA),例如Symantec、Let’s Encrypt等,以获得签名证书。CA会验证你的域名和身份,并颁发相应的证书文件。
如果你正在开发环境中进行测试或个人使用,你可以使用自签名证书。使用以下命令生成自签名证书(例如certificate.crt):
openssl x509 -req -in csr.pem -signkey private.key -out certificate.crt -
将私钥和证书应用到HTTPS服务器:
将生成的私钥(private.key)和证书(certificate.crt)应用到你的HTTPS服务器配置中。具体步骤将取决于你使用的服务器软件,例如Node.js、Nginx、Apache等。
22.3 创建HTTPS服务端
https.createServer() 方法用于创建一个HTTPS服务器,并返回一个 Server 对象。该方法的第一个参数是一个包含 key 和 cert 属性的对象或字符串,分别表示私钥和证书文件路径或内容。如果使用自签名证书进行开发和测试,则可以使用以下代码来创建一个HTTPS服务器:
const https = require('https');
const fs = require('fs');
// 读取私钥和证书文件
const privateKey = fs.readFileSync('/path/to/private/key.pem', 'utf8');
const certificate = fs.readFileSync('/path/to/certificate.pem', 'utf8');
// ca证书
const ca = fs.readFileSync('/path/to/ca.crt', 'utf8');
const serverOptions = {
key: privateKey,
cert: certificate,
ca: [ca]
};
// 创建HTTPS服务器
const server = https.createServer(serverOptions, (req, resp) => {
// 设置响应头
resp.setHeader('Content-Type', 'text/plain');
resp.statusCode = 200;
// 返回响应消息
if (req.method === 'GET' && req.url === '/') {
resp.writeHead(200, {'Content-Type': 'text/plain'});
resp.write('Hello, World!');
resp.end();
} else {
resp.writeHead(404, {'Content-Type': 'text/plain'});
resp.write('404 Not Found\n');
resp.end();
}
});
// 监听端口443
server.listen(443, () => {
console.log('Server running on port 443');
});
需要注意的是,在生产环境中,应该使用受信任的证书颁发机构颁发的正式证书,以确保通信安全。
受信任的证书一般建议去阿里云、腾讯云等去申请下载。
https.Server 对象继承自 http.Server 对象,在 request 事件回调中,可以使用 req.connection.encrypted 属性判断是否为HTTPS连接。如果是HTTPS连接,则可以使用 resp.writeHead() 方法设置响应头,使用 resp.write() 和 resp.end() 方法返回响应数据。
22.4 HTTPS客户端
在 Node.js 中,https.get() 和 https.request() 是用于发送HTTPS GET和HTTPS请求的两个核心函数。
22.4.1 的http.get发起HTTPS请求
https.get() 方法用于发送HTTPS GET请求,并接收响应数据。它接受两个参数:
- options:一个对象,用于指定请求的URL、头部信息等配置。
- callback:一个回调函数,用于处理响应数据。
https.get() 方法返回一个 http.ClientRequest 对象,可以通过该对象设置请求的头部信息和监听请求事件。
client.js
const https = require('https');
// 发送HTTPS请求
https.get('https://www.example.com', (resp) => {
let data = '';
// 接收响应数据
resp.on('data', (chunk) => {
data += chunk;
});
// 响应结束
resp.on('end', () => {
// 打印响应数据
console.log(data);
});
}).on('error', (err) => {
console.error(err);
});
22.4.2 https.request发起HTTPS请求
https.request()方法用于发送HTTPS请求,可以进行更加灵活的配置。它接受两个参数:
- options:一个对象,用于指定请求的URL、头部信息等配置。
- callback:一个回调函数,用于处理响应数据。
https.request()方法返回一个http.ClientRequest对象,可以通过该对象设置请求的头部信息和监听请求事件。
22.4.3 加密HTTPS请求
使用https模块发起加密HTTPS协议和直接发送HTTPS请求的区别在于需要指定证书等参数。
如果服务器使用自签名的证书,那么我们需要在options对象中设置rejectUnauthorized为false,允许使用自签名证书。
client.js
const fs = require('fs');
const http = require('https');
const options = {
hostname: '127.0.0.1',
port: 443,
path: '/',
method: 'GET',
key: fs.readFileSync("client.key"),
cert: fs.readFileSync("client.key"),
ca: [fs.readFileSync("ca.crt")]
};
options.agent = https.Agent(options);
const req = https.request(options, (resp) => {
console.log("状态码 statusCode=", resp.statusCode);
console.log("响应体 headers=", JSON.stringify(resp.headers));
let data = '';
resp.on('data', (chunk) => {
data += chunk;
});
resp.on('end', () => {
console.log("请求结束 data=", data);
});
});
req.on('error', (error) => {
console.error(error);
});
req.end();
https模块还提供了一个 globalAgent 对象,可以设置全局的HTTPS代理选项,例如最大套接字数、证书验证等。该对象的默认值为 https.globalAgent,可以使用以下代码修改它的选项:
const https = require('https');
https.globalAgent.maxSockets = 10;
https.globalAgent.options.rejectUnauthorized = false;
上面的代码将全局的最大套接字数设置为10,将证书验证设置为不拒绝未经验证的证书。
注意:受信任的证书颁发机构颁发的证书的域名需要和HTTPS服务器的域名一致才能正常访问,不然请求会被拦截。
https 模块是用于创建和处理HTTPS服务器和客户端的 Node.js 模块。它提供了创建HTTPS服务器、发送HTTPS请求、处理HTTPS请求和配置HTTPS选项等功能。在使用HTTPS时,需要使用受信任的证书颁发机构颁发的正式证书,以确保通信安全。
总结
Node.js 的 https 模块是用于创建和处理HTTPS请求的模块。它提供了一些方法来操作HTTPS连接和服务器。
- https.get(options, callback): 发起一个GET请求到指定的HTTPS服务器,并在获取到响应时调用回调函数。
- https.request(options, callback): 发起一个自定义的HTTPS请求到指定的服务器,并在获取到响应时调用回调函数。
- https.createServer(options, requestListener): 创建一个HTTPS服务器,并传入一个用于处理传入请求的回调函数。
- https.globalAgent: 全局的HTTPS代理对象,可用于自定义HTTPS请求的行为。
这些方法可以帮助你创建安全的HTTPS连接、发送请求,并处理响应。你可以使用证书和私钥等配置来保护你的连接和服务器。https 模块提供了灵活的选项,以适应不同的需求。通过 https 模块你可以构建安全的HTTPS连接并与其他服务进行通信。
23-WebSocket
WebSocket 是一种在单个 TCP 连接上提供全双工通信的协议。与 HTTP 不同,WebSocket 的连接是持久的,客户端和服务器可以在任何时间点上进行双向通信,而不需要为每个请求创建新的连接。WebSocket 协议通过建立长连接,允许服务器主动向客户端推送数据,实现实时的双向通信。
以下是 WebSocket 和 HTTP 的一些主要区别:
-
连接方式:HTTP 协议使用短连接,每个请求-响应周期都会创建一个新的连接。而 WebSocket 协议使用长连接,在客户端和服务器之间建立持久的连接,以实现实时的双向通信。
-
通信方式:HTTP 是一种请求-响应模式的通信方式,客户端发送请求,服务器返回响应。而 WebSocket 允许客户端和服务器之间实时地双向通信,无需等待请求和响应。
-
数据格式:HTTP 通常使用文本或二进制格式传输数据,而 WebSocket 支持以原始二进制格式或文本格式传输数据。
-
端口:HTTP 默认使用 80 端口进行通信,HTTPS 使用 443 端口。而 WebSocket 通常使用 80 或 443 端口作为默认端口。同时,WebSocket 还可以使用其他非常用端口进行通信。
-
应用场景:HTTP 适用于传统的请求-响应模式,例如获取网页内容、上传文件等。而 WebSocket 更适用于实时性要求较高的应用场景,如实时聊天、实时协作、实时游戏等,其中需要服务器主动向客户端推送数据。
WebSocket 和 HTTP 是两种不同的协议,适用于不同的通信需求。HTTP 适合传统的请求-响应模式,而 WebSocket 提供了持久的双向通信能力,更适合实时性要求较高的应用。
23.1 ws
Node.js 的 ws(WebSocket)模块是一个轻量级的 WebSocket 实现,用于在 Node.js 服务器和客户端之间建立实时通信的连接。它使用了标准的 WebSocket 协议(RFC 6455),支持高速、双向、实时数据传输,非常适合构建实时应用程序,如聊天应用、实时游戏等。
ws 模块的主要特点包括:
- 简单易用:提供简单的 API,容易上手。
- 高效性能:采用 C++ 扩展编写,具有良好的性能。
- 跨平台兼容性:可运行于 Windows、Linux、macOS 等多种平台,并且与浏览器的 WebSocket API 兼容。
- 安全性:支持 WSS(WebSocket over SSL/TLS)协议,使用加密的 WebSocket 连接,保证通信安全。
使用 ws 需要先安装依赖:
npm install ws --save
下面是 ws 模块的一些主要 API:
23.1.1 服务端 API
WebSocket.Server
WebSocket.Server 是 WebSocket 的服务端类,用于创建和管理 WebSocket 服务器。可以通过实例化该类来创建 WebSocket 服务器,并使用其提供的方法管理连接。
构造函数
const WebSocket = require('ws');
const wss = new WebSocket.Server(options);
options:可选参数对象。包含以下属性:
- port:WebSocket 服务器监听的端口号,默认为 80。
- server:HTTP 服务器实例,用于绑定 WebSocket 服务器。
- clientTracking:是否记录客户端连接数,默认为 false。
- perMessageDeflate:是否开启压缩功能,默认为 true。
实例方法
-
wss.on(eventName, callback)
监听事件,可以监听以下事件:
- connection:新客户端连接成功后触发。
- error:发生错误时触发。
- headers:收到客户端 HTTP 请求头时触发。
- listening:WebSocket 服务器开始监听连接请求时触发。
wss.clients
获取所有连接到当前 WebSocket 服务器的 WebSocket 对象。
WebSocket
WebSocket 是 WebSocket 的客户端类,用于创建和管理 WebSocket 客户端。可以通过实例化该类来创建 WebSocket 客户端,并使用其提供的方法管理连接。
构造函数
const WebSocket = require('ws');
const ws = new WebSocket(url, [options]);
参数说明:
- url:WebSocket 服务器的 URL 地址。
- options:可选参数对象。包含以下属性:
- protocol:指定客户端使用的协议,默认为无协议。
- headers:指定客户端发送的 HTTP 请求头。
webSocket.readyState
readyState 表示 23.WebSocket 连接的当前状态,它是一个只读属性。readyState 属性的值是一个整数,代表不同的连接状态:
-
CONNECTING(值为 0):正在建立连接,WebSocket 对象已经创建,但尚未完成连接握手。
-
OPEN(值为 1):连接已经建立,可以进行通信。
-
CLOSING(值为 2):连接正在关闭中,数据传输已经停止,但是还没有完全关闭。
-
CLOSED(值为 3):连接已经关闭或无法打开。
在使用 ws 库时,你可以通过访问 WebSocket 实例的 readyState 属性获取当前连接状态。
实例方法
-
ws.send(data, [options], [callback])
向服务器发送数据。可以发送字符串、Buffer、ArrayBuffer 等类型的数据。 -
ws.close(code, [reason])
关闭 WebSocket 连接。 -
ws.on(eventName, callback)
监听事件,可以监听以下事件:- open:连接成功时触发。
- close:断开连接时触发。
- message:收到服务器发送的消息时触发。
- error:发生错误时触发。
23.1.2 客户端 API
new WebSocket(url, [protocols])
创建 WebSocket 实例,用于连接 WebSocket 服务器。
参数说明:
- url:WebSocket 服务器的 URL 地址。
- protocols:可选参数,指定使用的协议。
实例方法
-
ws.send(data)
向服务器发送数据。可以发送字符串、Buffer、ArrayBuffer 等类型的数据。 -
ws.close()
关闭 WebSocket 连接。 -
ws.addEventListener(eventName, callback)
监听事件,可以监听以下事件:- open:连接成功时触发。
- close:断开连接时触发。
- message:收到服务器发送的消息时触发。
- error:发生错误时触发。
23.1.3 创建 WebSocket 服务器
server.js
// 需要安装依赖:npm install ws --save
const WebSocket = require('ws');
const wss = new WebSocket.Server({ port: 8080 });
wss.on('connection', (ws) => {
console.log('新的连接已建立');
ws.on('message', (message) => {
console.log(`接收到消息:${message}`);
});
ws.send('欢迎连接 WebSocket 服务器');
});
上述代码创建了一个 WebSocket 服务器,并监听在本地的 8080 端口。当有新的连接建立时,会触发 connection 事件,并在回调函数中处理连接。
在连接建立后,可以通过 ws.on('message', callback) 方法监听来自客户端的消息。当接收到消息时,会触发 message 事件,并在回调函数中处理消息。
通过 ws.send(message) 方法可以向客户端发送消息。
23.1.4 创建 WebSocket 客户端
client.js
const WebSocket = require('ws');
const ws = new WebSocket('ws://localhost:8080');
ws.on('open', () => {
console.log('连接到 WebSocket 服务器');
ws.send('Hello, Server!');
});
ws.on('message', (message) => {
console.log(`接收到消息:${message}`);
});
上述代码创建了一个 WebSocket 客户端,并连接到本地的 8080 端口的服务器。
当连接成功后,会触发 open 事件,并在回调函数中处理。可以通过 ws.send(message) 方法向服务器发送消息。
同样地,通过 ws.on('message', callback) 方法可以监听来自服务器的消息,并在回调函数中处理。
注意:
1. ws 只能在 Node.js 环境中使用,在浏览器中不能使用,浏览器请直接使用原生的 WebSocket 构造函数。
2. ws 一般不会单独使用,更优的方案都是将 ws 集成到 Express 框架中去使用。
上述是使用 ws 模块创建 WebSocket 服务器和客户端的基本示例。你还可以使用其他第三方库或框架来实现 WebSocket 功能,如 socket.io、uws 等。
WebSocket 是一种用于在客户端和服务器之间进行双向通信的协议,在 Node.js 中可以使用 ws 模块来创建 WebSocket 服务器和客户端,实现实时的数据推送和双向通信功能。
总结
WebSocket 是一种在客户端和服务器之间进行双向通信的网络协议,它提供了实时性、低延迟和较小的数据包开销等优势。通过使用 WebSocket,可以构建实时的应用程序,实现即时通信和实时数据推送的功能。同时,Node.js 还提供了一些第三方模块和库,例如 socket.io 和 ws,使得开发者可以方便地构建实时性强的 WebSocket 应用程序。
24-进程和子进程
进程 是计算机中正在运行的程序的实例。每个 进程 都有独立的内存空间和系统资源,它们相互隔离,互不干扰。进程 是操作系统进行任务调度和资源分配的基本单位。
线程 是进程中的一个独立执行单元,它可以并行地执行多个任务。在一个多线程程序中,不同的线程可以同时处理不同的任务,从而提高程序的执行效率。然而,多线程编程也带来了一定的复杂性,如线程同步、死锁等问题。
Node.js 采用单线程模型来处理任务。这意味着在 Node.js 中,所有的 I/O 操作、事件循环和定时器等都是由同一个线程来处理的。
当谈到 Node.js 的 进程 和 子进程 时,我们需要了解 Node.js 是基于单线程事件循环模型构建的。然而,Node.js 提供了一些机制来处理并发操作,其中包括利用进程和子进程。
24.1 Node.js中的进程
在 Node.js 中,进程是指计算机系统中运行的程序的实例。每个进程都有自己独立的内存空间和系统资源。Node.js 可以在单个进程上执行 JavaScript 代码。
Node.js 提供了 process 全局对象,它表示当前 Node.js 进程的实例。通过 process 对象,你可以访问关于进程的信息,例如进程 ID、环境变量等。此外,还可以使用 process 对象来控制进程的行为,例如终止进程、捕获信号等。
24.1.1 process 对象的属性:
当涉及到 Node.js 的 process 对象时,它提供了许多方法和属性来控制和管理 Node.js 应用程序的执行环境。下面是一些常用的 process 方法和属性的详细解释以及示例代码:
-
process.argv:
argv是一个包含命令行参数的数组。其中,process.argv[0]表示 Node.js 的可执行文件路径,process.argv[1]表示当前脚本文件的路径,后续元素是传递给脚本的命令行参数。// 命令行执行:node app.js hello world console.log(process.argv); // 输出:[ 'node', '/path/to/app.js', 'hello', 'world' ] -
process.env:
env是一个对象,包含了当前进程的环境变量。通过process.env,你可以读取或设置环境变量的值。// 获取环境变量的值 console.log(process.env.HOME); // 设置环境变量的值 process.env.API_KEY = 'YOUR_API_KEY'; -
process.pid:
pid表示当前进程的进程 ID。console.log(`当前进程的进程 ID:${process.pid}`); // 输出:当前进程的进程 ID:1456 -
process.platform:
platform表示当前操作系统平台。console.log(process.platform); // 输出:darwin -
process.version:该属性返回一个字符串,表示当前 Node.js 的版本号。
console.log(process.version); // 输出:v18.17.1 -
process.versions:该属性是一个包含 Node.js 和其依赖的版本信息的对象。
console.log(process.versions); // 输出: // { // node: '18.17.1', // acorn: '8.8.2', // ada: '2.5.0', // ares: '1.19.1', // brotli: '1.0.9', // cldr: '43.1', // icu: '73.2', // llhttp: '6.0.11', // modules: '108', // napi: '9', // nghttp2: '1.55.1', // openssl: '3.1.2', // simdutf: '3.2.12', // tz: '2023c', // undici: '5.22.1', // unicode: '15.0', // uv: '1.46.0', // uvwasi: '0.0.18', // v8: '10.2.154.26-node.26', // zlib: '1.2.11' // } -
process.arch:该属性返回一个字符串,表示当前 Node.js 进程的处理器架构。
console.log(`当前处理器架构是:${process.arch}`); // 输出:当前处理器架构是:arm64 -
process.title:该属性用于设置或获取当前 Node.js 进程的进程名。
console.log(`当前进程的名称是:${process.title}`); process.title = 'MyProcess'; console.log(`修改后的进程名称是:${process.title}`); -
process.stdinout 和 process.stderr:
stdout和stderr分别表示标准输出流和标准错误流。你可以通过process.stdout.write()和process.stderr.write()方法向这些流写入数据。// 向标准输出流写入数据 process.stdout.write('Hello, world!\n'); // 向标准错误流写入数据 process.stderr.write('Error occurred!\n'); -
process.stdin:
process对象的一个可读流属性,用于从标准输入流(stdin)读取数据。process.stdin.setEncoding('utf-8'); // 监听用户输入的数据 process.stdin.on('data', (data) => { console.log(`用户输入了:${data.trim()}`); }); // 监听输入流结束事件 process.stdin.on('end', () => { console.log('输入流已经关闭'); }); -
process.config:提供了有关当前 Node.js 进程配置选项的信息。它返回一个包含各种配置值的对象。
console.log(process.config); // 输出: // { // target_defaults: { // cflags: [ '-msign-return-address=all' ], // default_configuration: 'Release', // defines: [ // 'NODE_OPENSSL_CONF_NAME=nodejs_conf', // 'NODE_OPENSSL_CERT_STORE', // 'ICU_NO_USER_DATA_OVERRIDE' // ], // include_dirs: [ // '/opt/homebrew/opt/libuv/include', // '/opt/homebrew/opt/brotli/include', // '/opt/homebrew/opt/c-ares/include', // '/opt/homebrew/opt/libnghttp2/include', // '/opt/homebrew/opt/openssl@3/include', // '/opt/homebrew/Cellar/icu4c/73.2/include' // ], // libraries: [ // '-lz', // '-L/opt/homebrew/opt/libuv/lib', // '-luv', // '-L/opt/homebrew/opt/brotli/lib', // '-lbrotlidec', // '-lbrotlienc', // '-L/opt/homebrew/opt/c-ares/lib', // '-lcares', // '-L/opt/homebrew/opt/libnghttp2/lib', // '-lnghttp2', // '-L/opt/homebrew/opt/openssl@3/lib', // '-lcrypto', // '-lssl', // '-L/opt/homebrew/Cellar/icu4c/73.2/lib', // '-licui18n', // '-licuuc', // '-licudata' // ] // }, // variables: { // arm_fpu: 'neon', // asan: 0, // coverage: false, // dcheck_always_on: 0, // debug_nghttp2: false, // debug_node: false, // enable_lto: false, // enable_pgo_generate: false, // enable_pgo_use: false, // error_on_warn: false, // force_dynamic_crt: 0, // host_arch: 'arm64', // icu_gyp_path: 'tools/icu/icu-system.gyp', // icu_small: false, // icu_ver_major: '73', // is_debug: 0, // libdir: 'lib', // llvm_version: '14.0', // napi_build_version: '9', // node_builtin_shareable_builtins: [ // 'deps/cjs-module-lexer/lexer.js', // 'deps/cjs-module-lexer/dist/lexer.js', // 'deps/undici/undici.js' // ], // node_byteorder: 'little', // node_debug_lib: false, // node_enable_d8: false, // node_enable_v8_vtunejit: false, // node_fipsinstall: false, // node_install_corepack: true, // node_install_npm: true, // node_library_files: [ // 'lib/_http_agent.js', // 'lib/_http_client.js', // 'lib/_http_common.js', // 'lib/_http_incoming.js', // 'lib/_http_outgoing.js', // 'lib/_http_server.js', // 'lib/_stream_duplex.js', // 'lib/_stream_passthrough.js', // 'lib/_stream_readable.js', // 'lib/_stream_transform.js', // 'lib/_stream_wrap.js', // 'lib/_stream_writable.js', // 'lib/_tls_common.js', // 'lib/_tls_wrap.js', // 'lib/assert.js', // 'lib/assert/strict.js', // 'lib/async_hooks.js', // 'lib/buffer.js', // 'lib/child_process.js', // 'lib/cluster.js', // 'lib/console.js', // 'lib/constants.js', // 'lib/crypto.js', // 'lib/dgram.js', // 'lib/diagnostics_channel.js', // 'lib/dns.js', // 'lib/dns/promises.js', // 'lib/domain.js', // 'lib/events.js', // 'lib/fs.js', // 'lib/fs/promises.js', // 'lib/http.js', // 'lib/http2.js', // 'lib/https.js', // 'lib/inspector.js', // 'lib/internal/abort_controller.js', // 'lib/internal/assert.js', // 'lib/internal/assert/assertion_error.js', // 'lib/internal/assert/calltracker.js', // 'lib/internal/async_hooks.js', // 'lib/internal/blob.js', // 'lib/internal/blocklist.js', // 'lib/internal/bootstrap/browser.js', // 'lib/internal/bootstrap/loaders.js', // 'lib/internal/bootstrap/node.js', // 'lib/internal/bootstrap/switches/does_not_own_process_state.js', // 'lib/internal/bootstrap/switches/does_own_process_state.js', // 'lib/internal/bootstrap/switches/is_main_thread.js', // 'lib/internal/bootstrap/switches/is_not_main_thread.js', // 'lib/internal/buffer.js', // 'lib/internal/child_process.js', // 'lib/internal/child_process/serialization.js', // 'lib/internal/cli_table.js', // 'lib/internal/cluster/child.js', // 'lib/internal/cluster/primary.js', // 'lib/internal/cluster/round_robin_handle.js', // 'lib/internal/cluster/shared_handle.js', // 'lib/internal/cluster/utils.js', // 'lib/internal/cluster/worker.js', // 'lib/internal/console/constructor.js', // 'lib/internal/console/global.js', // 'lib/internal/constants.js', // 'lib/internal/crypto/aes.js', // 'lib/internal/crypto/certificate.js', // 'lib/internal/crypto/cfrg.js', // 'lib/internal/crypto/cipher.js', // 'lib/internal/crypto/diffiehellman.js', // 'lib/internal/crypto/ec.js', // 'lib/internal/crypto/hash.js', // 'lib/internal/crypto/hashnames.js', // 'lib/internal/crypto/hkdf.js', // 'lib/internal/crypto/keygen.js', // 'lib/internal/crypto/keys.js', // 'lib/internal/crypto/mac.js', // 'lib/internal/crypto/pbkdf2.js', // 'lib/internal/crypto/random.js', // 'lib/internal/crypto/rsa.js', // 'lib/internal/crypto/scrypt.js', // 'lib/internal/crypto/sig.js', // 'lib/internal/crypto/util.js', // 'lib/internal/crypto/webcrypto.js', // 'lib/internal/crypto/webidl.js', // 'lib/internal/crypto/x509.js', // 'lib/internal/debugger/inspect.js', // 'lib/internal/debugger/inspect_client.js', // 'lib/internal/debugger/inspect_repl.js', // 'lib/internal/dgram.js', // 'lib/internal/dns/callback_resolver.js', // 'lib/internal/dns/promises.js', // 'lib/internal/dns/utils.js', // 'lib/internal/dtrace.js', // 'lib/internal/encoding.js', // 'lib/internal/error_serdes.js', // 'lib/internal/errors.js', // 'lib/internal/event_target.js', // 'lib/internal/file.js', // 'lib/internal/fixed_queue.js', // 'lib/internal/freelist.js', // 'lib/internal/freeze_intrinsics.js', // 'lib/internal/fs/cp/cp-sync.js', // ... 205 more items // ], // node_module_version: 108, // node_no_browser_globals: false, // node_prefix: '/opt/homebrew/Cellar/node@18/18.17.1', // node_release_urlbase: '', // node_shared: false, // node_shared_brotli: true, // node_shared_cares: true, // node_shared_http_parser: false, // node_shared_libuv: true, // node_shared_nghttp2: true, // node_shared_nghttp3: false, // node_shared_ngtcp2: false, // node_shared_openssl: true, // node_shared_zlib: true, // node_tag: '', // node_target_type: 'executable', // node_use_bundled_v8: true, // node_use_dtrace: true, // node_use_etw: false, // node_use_node_code_cache: true, // node_use_node_snapshot: true, // node_use_openssl: true, // node_use_v8_platform: true, // node_with_ltcg: false, // node_without_node_options: false, // openssl_is_fips: false, // openssl_quic: false, // ossfuzz: false, // shlib_suffix: '108.dylib', // single_executable_application: true, // target_arch: 'arm64', // v8_enable_31bit_smis_on_64bit_arch: 0, // v8_enable_gdbjit: 0, // v8_enable_hugepage: 0, // v8_enable_i18n_support: 1, // v8_enable_inspector: 1, // v8_enable_javascript_promise_hooks: 1, // v8_enable_lite_mode: 0, // v8_enable_object_print: 1, // v8_enable_pointer_compression: 0, // v8_enable_shared_ro_heap: 1, // v8_enable_webassembly: 1, // v8_no_strict_aliasing: 1, // v8_optimized_debug: 1, // v8_promise_internal_field_count: 1, // v8_random_seed: 0, // v8_trace_maps: 0, // v8_use_siphash: 1, // want_separate_host_toolset: 0 // } // }
24.1.2 process 对象的方法和事件:
Node.js 的进程对象 process 提供了一些方法和事件,用于管理当前 Node.js 进程的执行环境。下面是一些常用的进程对象方法和事件的详细介绍。
process对象的方法
-
process.uptime():该方法返回当前 Node.js 进程的运行时间,以秒为单位。
console.log(`当前进程已运行 ${process.uptime()} 秒`); -
process.cwd():
cwd()方法返回当前工作目录的路径。console.log(process.cwd()); // 输出:/path/to/current/directory -
process.exit([code]):
exit()方法用于终止当前进程,并返回一个指定的退出码(默认为0)。通过调用process.exit(),你可以在代码中主动退出应用程序。// 在某个条件满足时退出进程 if (someCondition) { process.exit(1); // 退出并返回退出码 1 } -
process.chdir(directory):该方法将 Node.js 应用程序的当前工作目录更改为指定的目录。它主要用于将
Node.js应用程序的工作目录更改为指定目录,以便访问其他文件或资源。process.chdir('/path/to/new/directory'); console.log(process.cwd()); // 输出:/path/to/new/directory -
process.memoryUsage():该方法返回一个对象,其中包含有关当前 Node.js 进程内存使用情况的信息,包括堆内存、RSS(常驻集大小)和虚拟内存等。
console.log(process.memoryUsage()); // 输出: // { // rss: 38518784, // heapTotal: 6406144, // heapUsed: 5313064, // external: 413654, // arrayBuffers: 17678 // } -
process.nextTick(callback, […args]):该方法将指定的回调函数添加到事件队列中,以在当前操作完成后尽快执行。它类似于
setImmediate(),但比setImmediate()更快且优先级更高。process.nextTick(() => { console.log('next tick'); }); console.log('current tick');在上面的示例代码中,
nextTick()回调函数会在当前操作完成后尽快执行,而不是等待下一个事件循环。因此,在输出current tick之后,将立即输出next tick。 -
process.on(eventName, callback):该方法用于注册事件监听器,以便在发生特定事件时触发回调函数。
process对象的事件
-
process.on(eventName, callback):该方法用于注册事件监听器,以便在发生特定事件时触发回调函数。
exit 事件:该事件在 Node.js 进程即将退出时触发,并返回退出码。
process.on('exit', (code) => { console.log(`进程即将退出,退出码:${code}`); });uncaughtException 事件:该事件在 Node.js 进程中捕获到未处理的异常时触发,允许开发者对异常进行适当的处理。
process.on('uncaughtException', (err) => { console.error('捕获到未处理的异常:', err); // 进行适当的处理,如记录日志等 process.exit(1); // 退出并返回退出码 1 });beforeExit 事件:该事件在 Node.js 进程即将退出之前触发,但在
exit事件之前。它允许程序在退出之前执行一些清理操作。process.on('beforeExit', () => { console.log('进程即将退出,开始清理资源...'); // 执行清理操作 });warning 事件:该事件在 Node.js 进程发出警告时触发,通常是由于使用了过时的 API 或其他不推荐使用的功能。
process.on('warning', (warning) => { console.warn('发出警告:', warning.name); console.warn(warning.message); console.warn(warning.stack); });unhandledRejection 事件:该事件在 Node.js 进程中发生未处理的
Promise拒绝时触发。process.on('unhandledRejection', (reason, promise) => { console.error('未处理的 Promise 拒绝:', reason); // 进行适当的处理,如记录日志等 }); -
abort():该方法会立即终止进程的执行并生成一个包含详细错误信息的核心转储文件。这个核心转储文件可以用于调试和分析进程崩溃的原因。该方法无需任何参数。
-
getgid():用于获取当前进程的组标识符(Group ID)的方法。Group ID 是用于标识用户所属组的数字。在 Node.js 中,
process.getgid()方法返回一个整数,表示当前进程的组标识符。console.log(`当前进程的组标识符是: ${process.getgid()}`); // 输出:当前进程的组标识符是: 20请注意,
process.getgid()方法只能在支持的操作系统上使用,并且可能需要适当的权限才能访问组标识符信息。如果无法获取组标识符,则该方法可能会抛出异常。 -
setgid(id):用于设置当前进程的组标识符(Group ID)的方法。
// 将当前进程的组标识符设置为 1000 process.setgid(1000); // 你也可以使用字符串形式的组名称来设置组标识符,例如: //process.setgid('staff'); // 将当前进程的组标识符设置为 "staff"请注意,设置组标识符需要适当的权限。如果你尝试设置一个无效的组标识符或者没有足够的权限进行设置,
process.setgid()方法可能会抛出异常 -
getuid():用于获取当前进程的用户标识符(User ID)的方法。User ID 是用于标识用户的数字。在 Node.js 中,
process.getuid()方法返回一个整数,表示当前进程的用户标识符。console.log(`当前进程的用户标识符是: ${process.getuid()}`); // 输出:当前进程的用户标识符是: 501请注意,
process.getuid()方法只能在支持的操作系统上使用,并且可能需要适当的权限才能访问用户标识符信息。如果无法获取用户标识符,则该方法可能会抛出异常。 -
setuid(id):用于设置当前进程的用户标识符(User ID)的方法。
// 将当前进程的用户标识符设置为 1000 process.setuid(1000); // 你也可以使用字符串形式的用户名来设置用户标识符,例如: //process.setuid('john'); // // 将当前进程的用户标识符设置为 "john"请注意,设置用户标识符需要适当的权限。如果你尝试设置一个无效的用户标识符或者没有足够的权限进行设置,
process.setuid()方法可能会抛出异常。 -
getgroups():用于获取当前进程所属的组列表的方法。在 Node.js 中,
process.getgroups()方法返回一个数组,包含了当前进程所属的组标识符(Group ID)。console.log(`当前进程所属的组列表:`, process.getgroups()); // 输出: // 当前进程所属的组列表: [ // 20, 12, 61, 79, 80, 81, // 98, 702, 704, 705, 703, 33, // 100, 204, 250, 395 // ]请注意,
process.getgroups()方法只能在支持的操作系统上使用,并且可能需要适当的权限才能访问组列表信息。如果无法获取组列表,则该方法可能会抛出异常。 -
setgroups(groups):方法需要一个数组作为参数,其中包含了进程的新组列表。
const newGroups = [100, 200, 300]; process.setgroups(newGroups);注意:
1. 由于设置组列表需要更高级别的特权和操作系统级别的支持,因此process.setgroups()在普通用户上下文中几乎不可能成功。实际上,大多数系统都禁止普通用户更改他们所属的组列表。
2. 使你拥有足够的权限来更改进程的组列表,也应该谨慎使用此方法。更改组列表可能会带来安全风险,并且可能会破坏系统的一致性和可靠性。通常情况下,只有超级用户或具有必要权限的用户才能更改进程的组列表。 -
initgroups():用于初始化进程的附加组列表,并不是设置或更改组列表。它通常在 Unix-like 系统中使用,用于设置进程的有效组 ID 和附加组 ID。该方法需要第一个参数为用户名,第二个参数为用户所属的组 ID。它会根据这些信息初始化进程的附加组列表。
注意:
1. 由于安全性和权限的考虑,Node.js 并没有提供直接的接口来执行此操作。如果你需要设置或更改进程的组列表,你需要使用适当的系统命令或平台特定的工具。
2. 在进行任何与组列表相关的操作时,务必谨慎,并确保你拥有足够的权限和了解可能带来的风险。 -
kill(pid, [signal]):Node.js 的内置方法,它将信号发送给进程(即进程id),信号是字符串类型,默认
SIGTERM。const process = require('process'); // 获取当前进程的 PID console.log(`当前进程的 PID: ${ process.pid}`); // 使用 process.kill() 方法终止指定进程 // 注意:这里只是演示,实际上不会终止当前进程 process.kill(currentPid, 'SIGTERM'); -
unmask([mask]):设置 Node.js 进程的文件模式创建掩码。子进程从父进程继承掩码。返回前一个掩码。
const newmask = 0o010 const oldmask = process.unmask(newmask); console.log("修改前的掩码:" + oldmask.toString(8) + " 修改后的掩码:" + oldmask.toString(8))
process的信号事件
- SIGINT:当用户按下
Ctrl+C时,会触发此信号。通常用于捕获中断操作。 - SIGTERM:当进程被要求终止时,会触发此信号。通常用于优雅地关闭进程。
- SIGHUP:当终端挂起或控制进程从控制终端断开连接时,会触发此信号。通常用于重新加载配置文件。
- SIGUSR1 和 SIGUSR2:这两个信号主要用于用户自定义用途。可以通过编写一个程序来监听这些信号,并在接收到信号时执行特定操作。
- SIGCHLD:当子进程结束时,会触发此信号。可以监听此信号以获取子进程的状态信息。
- SIGCONT:当进程从暂停状态恢复运行时,会触发此信号。通常用于恢复阻塞的操作。
- SIGSTOP:当进程被暂停时,会触发此信号。通常用于暂停进程。
- SIGTSTP:当用户按下
Ctrl+Z时,会触发此信号。通常用于暂停进程。 - SIGTTIN 和 SIGTTOU:这两个信号分别表示后台进程请求将自身放入后台运行以及前台进程请求将自身从后台切换到前台运行。
24.2 子进程
Node.js 的子进程(Child Process)是指在一个 Node.js 进程中启动另一个独立的 Node.js 进程。子进程可以用于执行一些耗时的任务,如文件读写、网络请求等,而不会阻塞主进程的执行。在 Node.js 中,可以使用 child_process 模块来创建和管理子进程。
child_process 模块提供了几种方法来创建子进程,包括 spawn()、exec()、execFile() 和 fork()。
-
spawn(command, args, options):创建一个子进程并返回一个
ChildProcess实例。command是要执行的命令,args是一个包含命令及其参数的数组,options是一个可选的配置对象。options 参数可以包含以下属性:
- cwd(字符串):子进程的工作目录。默认为当前进程的工作目录。
- env(对象):子进程的环境变量。默认为当前进程的环境变量。
- ext(字符串):可执行文件的扩展名。默认为
'.cmd'(Windows)或'.sh'(macOS/Linux)。 - execArgv(数组):传递给可执行文件的参数列表。默认为空数组。
- stdio(字符串):子进程的输入、输出和错误流。默认为
'inherit',表示继承父进程的流。其他可选值包括’pipe’(将子进程的输出发送到父进程的输入流)、'ignore'(忽略子进程的输出)和'ipc'(使用IPC通道进行通信)。 - detached(布尔值):是否将子进程与父进程分离。默认为
false。如果设置为true,则子进程将在后台运行,不会阻塞父进程。 - preexecPath(字符串):在启动子进程之前设置的
PATH环境变量。默认为当前进程的PATH环境变量。 - user(字符串):以指定用户身份运行子进程。默认为当前进程的用户。
- uid(数字):以指定用户ID运行子进程。默认为当前进程的用户ID。
- gid(数字):以指定组ID运行子进程。默认为当前进程的组ID。
- windowsVerbatimArguments(布尔值):是否在Windows上使用严格的参数解析。默认为
false。如果设置为true,则在Windows上使用严格的参数解析,以避免某些命令行注入攻击。
swpan 示例代码:
const { spawn } = require('child_process'); const child = spawn('ls', ['-lh', '/usr'], { cwd: '/tmp', env: { ...process.env, MY_ENV_VAR: 'my-value' }, stdio: 'inherit', detached: true, });spawn 创建多个子进程
const { spawn } = require('child_process'); // 创建多个子进程 const child1 = spawn('command1', ['arg1', 'arg2']); const child2 = spawn('command2', ['arg1', 'arg2']); const child3 = spawn('command3', ['arg1', 'arg2']); // 监听子进程的输出数据 child1.stdout.on('data', (data) => { console.log(`子进程1输出:${data}`); }); child2.stdout.on('data', (data) => { console.log(`子进程2输出:${data}`); }); child3.stdout.on('data', (data) => { console.log(`子进程3输出:${data}`); }); // 监听子进程的错误信息 child1.stderr.on('data', (data) => { console.error(`子进程1错误:${data}`); }); child2.stderr.on('data', (data) => { console.error(`子进程2错误:${data}`); }); child3.stderr.on('data', (data) => { console.error(`子进程3错误:${data}`); }); // 监听子进程的退出事件 child1.on('exit', (code, signal) => { if (code !== null) { console.log(`子进程1退出,退出码:${code}`); } else if (signal !== null) { console.log(`子进程1被信号 ${signal} 终止`); } else { console.log('子进程1正常退出'); } }); child2.on('exit', (code, signal) => { if (code !== null) { console.log(`子进程2退出,退出码:${code}`); } else if (signal !== null) { console.log(`子进程2被信号 ${signal} 终止`); } else { console.log('子进程2正常退出'); } }); child3.on('exit', (code, signal) => { if (code !== null) { console.log(`子进程3退出,退出码:${code}`); } else if (signal !== null) { console.log(`子进程3被信号 ${signal} 终止`); } else { console.log('子进程3正常退出'); } }); -
exec(command, callback):同步地执行一个命令,当命令执行完成后,会调用回调函数。回调函数接收两个参数:
error和stdout。示例代码:
const { exec } = require('child_process'); exec('ls -lh /usr', (error, stdout, stderr) => { if (error) { console.error(`执行错误: ${error}`); return; } console.log(`输出: ${stdout}`); console.error(`错误输出: ${stderr}`); });exec 创建多个子进程
const { exec } = require('child_process'); // 创建第一个子进程 const child1 = exec('command1', (error, stdout, stderr) => { if (error) { console.error(`执行错误: ${error}`); return; } console.log(`输出: ${stdout}`); console.error(`错误: ${stderr}`); }); // 创建第二个子进程 const child2 = exec('command2', (error, stdout, stderr) => { if (error) { console.error(`执行错误: ${error}`); return; } console.log(`输出: ${stdout}`); console.error(`错误: ${stderr}`); }); // 等待所有子进程完成 child1.on('exit', () => { console.log('子进程1已完成'); }); child2.on('exit', () => { console.log('子进程2已完成'); }); -
execFile(file, args, options, callback):类似于
spawn方法,但接受一个文件路径作为命令。其他参数与spawn方法相同。示例代码:
const { execFile } = require('child_process'); execFile('ls', ['-lh', '/usr'], (error, stdout, stderr) => { if (error) { console.error(`执行错误: ${error}`); return; } console.log(`输出: ${stdout}`); console.error(`错误输出: ${stderr}`); });execFile 创建多个子进程
const { execFile } = require('child_process'); // 创建第一个子进程 execFile('command1', [], (error, stdout, stderr) => { if (error) { console.error(`执行错误: ${error}`); return; } console.log(`输出: ${stdout}`); console.error(`错误: ${stderr}`); }); // 创建第二个子进程 execFile('command2', [], (error, stdout, stderr) => { if (error) { console.error(`执行错误: ${error}`); return; } console.log(`输出: ${stdout}`); console.error(`错误: ${stderr}`); }); -
fork(modulePath, [args], options):创建一个子进程,并加载指定的模块。子进程将继承父进程的代码,因此它们可以共享相同的内存空间。
modulePath是要加载的模块的路径,args是一个可选的参数数组,options是一个可选的配置对象。options 参数可以包含以下属性:
- execArgv(Array):传递给子进程的可执行文件的参数列表。默认值为
undefined,表示使用父进程的argv数组。 - env(Object):传递给子进程的环境变量对象。默认值为
undefined,表示使用父进程的环境变量。 - ext(String):可执行文件的扩展名。默认值为
'.js'。 - cwd(String):子进程的工作目录。默认值为
undefined,表示使用父进程的工作目录。 - detached(Boolean):是否将子进程与父进程分离。默认值为
false。如果设置为true,则子进程将在后台运行,不会继承父进程的文件描述符。 - stdio(String):子进程的标准输入、输出和错误流。默认值为
'inherit',表示从父进程继承这些流。其他有效值包括'pipe'(创建一个管道)、'ignore'(忽略子进程的输出)和'ipc'(使用IPC通道进行通信)。 - silent(Boolean):是否禁止子进程的输出。默认值为
false。如果设置为true,则子进程的输出将被丢弃。 - uid(Number):子进程的用户ID。默认值为
undefined,表示使用父进程的用户ID。 - gid(Number):子进程的组ID。默认值为
undefined,表示使用父进程的组ID。 - signal(String):要发送给子进程的信号。默认值为
undefined,表示不发送任何信号。其他有效值包括'SIGTERM'、'SIGINT'等。
示例代码:
const { fork } = require('child_process'); const child = fork('./child.js');fork 创建多个子进程
main.js
const { fork } = require('child_process'); const child1 = fork('./child1.js'); const child2 = fork('./child2.js'); child1.on('message', (msg) => { console.log(`子进程1收到消息: ${msg}`); }); child2.on('message', (msg) => { console.log(`子进程2收到消息: ${msg}`); }); - execArgv(Array):传递给子进程的可执行文件的参数列表。默认值为
-
kill(pid[, signal]):终止一个子进程。
pid是要终止的子进程的进程ID,signal是一个可选的信号名称,默认为SIGTERM。const { kill } = require('child_process'); kill(child.pid, 'SIGKILL'); -
unref():取消子进程的引用计数。当子进程不再被引用时,它将自动退出。这在某些情况下可以提高性能,例如在事件循环空闲时。
const { spawn } = require('child_process'); const child = spawn('ls', ['-lh', '/usr']); child.unref();
24.3 cluster
Node.js 的 cluster 模块是一个用于创建多进程程序的工具。它允许你将一个大的任务分解成多个子任务,然后使用多个进程并行地执行这些子任务,从而提高程序的性能和吞吐量。
24.3.1 cluster的工作原理
Node.js 的 cluster 模块允许你利用多核CPU的优势,通过将一个大型的 Node.js 的 cluster 模块允许你利用多核CPU的优势,通过将一个大型的计算任务分解成多个子任务并行处理,从而提高应用程序的性能和吞吐量。
在 cluster 模式中,存在两个主要的概念:master 和 worker。 master 即主进程,负责创建和管理所有的子进程(即worker)。 在 Node.js 程序启动时,首先由主进程生成多个子进程。每个子进程都是一个独立的 Node.js 实例,它们共享相同的代码和数据,但各自拥有自己的内存空间和事件循环,彼此之间不会相互影响。
Master 进程负责监听新的连接请求,当有新的请求到达时,它将请求分配给其中一个 Worker 进程。如果某个 Worker 进程因某种原因崩溃或无法处理请求,Master 进程将会重新分配该请求给其他 Worker 进程。
此外,Worker 进程之间可以通过 process.send() 方法来发送信息,主进程和其他 Worker 进程则可以通过监听 'message' 事件来接收这些信息。
cluster 模块的主要功能如下:
-
创建进程:
cluster.fork()方法用于创建一个新的子进程。这个方法接受一个回调函数作为参数,当子进程创建成功后,这个回调函数会被调用。setupPrimary()方法则用于设置主进程的配置 -
监听事件:cluster 对象提供了一些事件,如
'exit'、'message'等,可以用来监听子进程的状态变化。 -
发送消息:可以使用
process.send()方法向主进程或其他子进程发送消息。 -
接收消息:可以使用
process.on('message')方法监听并处理来自其他进程的消息。
cluster方法和事件
cluster 模块提供了一些方法和事件,用于在 Node.js 应用程序中创建和管理多个子进程。下面是对 cluster 模块常用的方法和事件的详细介绍:
cluster的属性和方法:
- cluster.isMaster: 判断当前进程是否为主进程。
- cluster.fork(): 创建一个新的子进程。
- cluster.setupMaster([settings]): 设置主进程的工作模式。
- cluster.workers: 返回所有子进程的引用。
- cluster.disconnect(callback): 断开与子进程的连接。
- cluster.kill(pid, signal): 终止指定的子进程。
- cluster.exec(command, args, options): 在主进程中执行命令。
- cluster.schedulingPolicy(): 获取或设置工作调度策略。
- cluster.maxSockets: 获取或设置最大文件描述符数。
- cluster.openPort(port[, address], callback): 打开指定端口并返回一个端口对象。
- cluster.registerDomain(options, callback): 注册一个自定义域名。
- cluster.unregisterDomain(domain, callback): 注销一个自定义域名。
cluster 模块也定义了一些特定的事件,主要包括:
- cluster.on(‘fork’, callback): 用于监听子进程创建事件。当一个新的子进程被创建时,会触发这个事件。回调函数
callback会在子进程创建后执行,接收一个参数worker,表示新创建的子进程对象。 - cluster.on(‘exit’, callback): 用于监听子进程退出事件。当一个子进程退出时,会触发这个事件。回调函数
callback会在子进程退出后执行,接收两个参数:worker表示退出的子进程对象,code表示子进程退出时的退出码。 - cluster.on(‘message’, callback): 用于监听主进程与子进程之间的消息传递。当主进程向子进程发送消息时,会触发这个事件。回调函数
callback会在收到消息后执行,接收两个参数:worker表示发送消息的子进程对象,message表示发送的消息内容。 - cluster.on(‘online’, callback): 用于监听子进程启动成功事件。当一个子进程启动成功后,会触发这个事件。回调函数
callback会在子进程启动成功后执行,接收一个参数:worker 表示启动成功的子进程对象。 - cluster.on(‘listening’, callback): 用于监听服务器开始监听指定端口的事件。当服务器开始监听指定端口时,会触发这个事件。回调函数
callback会在服务器开始监听后执行,接收一个参数:server 表示服务器对象。 - cluster.on(‘message’, callback): 用于监听主进程与子进程之间的消息传递。当主进程向子进程发送消息时,会触发这个事件。回调函数
callback会在收到消息后执行,接收两个参数:worker表示发送消息的子进程对象,message表示发送的消息内容。 - cluster.on(‘disconnect’, callback): 用于监听主进程
cluster.on('disconnect', callback)是一个事件监听器,用于监听主进程与子进程之间的连接断开事件。当主进程与子进程之间的连接断开时,会触发这个事件。回调函数callback会在连接断开后执行,接收一个参数:worker表示断开连接的子进程对象。
这些方法和事件可以帮助我们创建和管理多个子进程,并与它们之间进行通信。通过合理地使用 cluster 模块,我们可以利用多核处理器的能力,提高应用程序的性能和可扩展性。
worker的方法和事件
Worker 对象是 cluster 模块中表示工作进程的引用,它提供了一些方法和事件,用于在工作进程中进行操作和处理事件。下面是对 Worker 对象常用的方法和事件的详细介绍:
worker 对象的属性和方法:
- worker.process: 返回当前
worker进程的引用。 - worker.id: 返回当前
worker的唯一标识符。 - worker.send(message): 向主进程发送消息。
- worker.disconnect(): 断开与主进程的连接。
- worker.kill(): 终止
worker进程。 - worker.restart(): 重启
worker进程。 - worker.stdout.write(data): 向标准输出流写入数据。
- worker.stderr.write(data): 向标准错误流写入数据。
- worker.stdin.pause(): 暂停从标准输入流读取数据。
- worker.stdin.resume(): 恢复从标准输入流读取数据。
- worker.nextTick(callback): 将回调函数添加到事件队列中,在下一个
tick时执行。 - worker.setImmediate(callback): 将回调函数添加到事件队列中,在当前
tick结束时执行。 - worker.uncaughtException(err): 监听未捕获的异常事件。
- worker.unhandledRejection(reason, promise): 监听未处理的
Promise拒绝事件。
worker 对象的事件
- worker.on(‘fork’): 用于监听子进程的衍生
fork事件。当 Node.js 进程通过 cluster.fork() 方法衍生出一个新的子进程时,就会触发这个事件。回调函数接收一个参数,表示新创建的子进程对象。 - worker.on(‘listening’): 用于监听子进程开始监听指定端口的事件。当子进程成功启动并开始监听指定的端口时,就会触发这个事件。回调函数接收一个参数,表示服务器对象。
- worker.on(‘message’): 用于监听子进程发送消息的事件。当主进程向子进程发送消息时,就会触发这个事件。回调函数接收两个参数,第一个参数是发送消息的子进程对象,第二个参数是发送的消息内容。
- worker.on(‘exit’): 是一个事件监听器,用于监听子进程退出的事件。当子进程正常退出时,就会触发这个事件。回调函数接收两个参数,第一个参数是退出码,第二个参数是信号。
- worker.on(‘online’): 是一个事件监听器,用于监听子进程成功连接到主进程的事件。当子进程成功连接到主进程时,就会触发这个事件。回调函数接收一个参数,表示子进程对象。
- worker.on(‘disconnect’): 用于监听主进程与子进程之间的连接断开的事件。当主进程与子进程之间的连接断开时,就会触发这个事件。回调函数接收一个参数,表示子进程对象。
- worker.on(‘error’): 用于监听子进程发生错误的事件。当子进程发生错误时,就会触发这个事件。回调函数接收两个参数,第一个参数是发送消息的子进程对象,第二个参数是错误对象。
- worker.on(‘setup’): 用于监听子进程启动时执行的设置操作的事件。当子进程启动并开始执行任务之前,就会触发这个事件。回调函数没有参数。
- worker.on('cleanup): 用于监听子进程退出时执行的清理操作的事件。当子进程正常退出时,就会触发这个事件。回调函数没有参数。
Worker 对象的方法和事件使我们能够在工作进程中发送消息、结束进程、处理事件等。通过这些方法和事件,我们可以更好地管理工作进程的行为,并与主进程进行通信和协作。
24.3.2 父进程开启多个子进程
在 Node.js 中,可以使用 cluster 模块来创建多个子进程。cluster 模块允许开发者将一个 Node.js 应用分解成多个独立的工作进程,每个工作进程可以独立地处理请求,从而提高应用的性能和可伸缩性。
多个子进程运行服务器并监听同一个地址:
服务端
server.js
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`主进程 ${process.pid} 正在运行`);
// 衍生工作进程。
for (let i = 0; i < numCPUs; i++) {
const worker = cluster.fork();
// 为子进程的worker注册listening事件
worker.on('listening', (address) => {
console.log("子进程中服务器的地址:" + address.address + ":" + address.port);
});
// 使用子进程的wroker向主进程发送消息
worker.send("message");
worker.on('message', (msg) => {
console.log("主进程收到子进程的消息:", msg.toString())
});
// 强制关闭子进程
//worker.kill();
//worker.destroy();
// 子进程退出
worker.on('exit', (code, signal) => {
console.log("子进程退出,code", code);
});
}
// fork事件
cluster.on('fork', (worker) => {
console.log("子进程:" + worker.id);
});
// 主进程接接收子进程的反馈信息
cluster.on('online', (worker) => {
console.log("已收到子进程:" + worker.id + " 反馈信息");
});
// 主进程退出事件
cluster.on('exit', (worker, code, signal) => {
console.log(`工作进程 ${worker.process.pid} 已退出`);
});
} else {
// 工作进程代码
process.on('message', (message) => {
console.log(`Received message from master: ${JSON.stringify(message)}`);
});
// 工作进程可以共享任何TCP连接。
// 在本例子中,共享的是一个HTTP服务器。
const server = http.createServer();
const serverPort = 9000;
const serverHost = '127.0.0.1';
server.listen(serverPort, serverHost, () => {
console.log("子进程中服务器已经创建");
})
server.on('request', (req, resp) => {
console.log("请求路径:", req.url);
resp.writeHead(200, {'Content-Type': 'text/plain'});
resp.write('hello client!');
resp.end();
resp.on('error', (err) => {
console.log("发生错误 error:", err);
})
// 向主进程发送消息
process.send("sub_process message");
});
console.log(`工作进程 ${process.pid} 已启动`);
}
在上面的代码中,首先引入了 cluster 模块。然后使用 cluster.isMaster 判断当前进程是否为主进程。如果是主进程,则通过循环调用 cluster.fork() 方法创建多个子进程。
需要注意的是,在工作进程中使用 process.send() 方法向主进程发送消息。在主进程中,可以通过监听 worker.on('message') 事件来接收来自工作进程的消息,并进行处理。
在主进程中使用 worker.send() 方法向工作进程发送消息,同时在工作进程中使用 process.on()方法监听子进程中发送的消息。
工作进程中,首先会输出当前工作进程的进程ID。然后,创建一个HTTP服务器,并输出服务器已经创建的消息。当有请求到达服务器时,会输出请求路径,并向客户端返回一个简单的响应。同时,工作进程还会向主进程发送一条消息。
如果不是主进程,则表示该进程是子进程。在这个例子中,子进程会创建一个HTTP服务器并监听9000端口。最后输出相应的日志信息。
以上代码使用了 cluster 模块创建了多个子进程,并实现了主进程与子进程之间的通信。主进程和子进程之间可以相互发送消息,而且每个子进程都运行着一个独立的HTTP服务器。
客户端
使用 Node.js 的 http 模块发送10个GET请求到本地服务器(IP地址为127.0.0.1,端口号为9000)。
client.js
const http = require('http');
const numCPUs = require('os').cpus().length;
const options = {
hostname: '127.0.0.1',
port: 9000,
path: '/',
method: 'GET',
};
for (let i = 0; i < 10; i++) {
const req = http.request(options, (resp) => {
let data = '';
resp.on('data', (chunk) => {
data += chunk;
});
resp.on('end', () => {
console.log("请求结束 data=", data);
});
});
req.on('error', (error) => {
console.error(error);
});
req.end();
}
总结
当涉及到在 Node.js 中处理多任务和系统资源利用率时,进程和子进程是非常重要的概念。下面是进程和子进程的总结:
-
进程:进程是操作系统中正在运行的程序的实例。在 Node.js 中,每个应用程序都是一个进程。通过 process 模块,我们可以控制和管理当前进程。这包括获取和设置进程的环境变量、命令行参数、工作目录等信息,并且可以使用
process.exit()方法来退出当前进程。 -
子进程:子进程是由父进程创建的新进程。在 Node.js 中,我们可以使用
child_process模块来创建和控制子进程。子进程通常用于执行一些耗时的或需要额外计算资源的任务,例如执行外部程序或脚本。- spawn(): 通过流的方式将数据传输到子进程中,适用于长时间运行的进程。
- exec(): 在新的Shell中执行命令,并将结果输出到回调函数中。
- execFile(): 直接执行一个文件,无需先打开一个 Shell。
- fork(): 在新的Node.js进程中执行指定的模块,用于创建可独立运行的进程。
通过使用进程和子进程,我们可以实现并发处理和更高的系统资源利用率。Node.js 提供了方便的工具和API来控制和管理进程,从而实现多任务处理的需求。
25-数据库访问
对于 Node.js 应用程序中的数据库访问,通常会使用一些流行的数据库管理系统,比如 MongoDB、MySQL、PostgreSQL、Redis 等。下面我们将简要介绍如何在 Node.js 应用程序中进行数据库访问:
-
使用 Node.js 驱动程序
大多数数据库系统都提供了针对 Node.js 的官方或第三方驱动程序库,可以通过这些驱动程序来连接和操作数据库。比如对于 MongoDB,你可以使用官方的 mongodb 驱动程序,对于 MySQL 和 PostgreSQL,你可以使用 mysql 和 pg 等驱动程序。
-
使用 ORM 或 ODM 框架
ORM(对象关系映射)和 ODM(对象文档映射)框架可以帮助开发人员更轻松地与数据库进行交互,而不必直接编写 SQL 或 MongoDB 查询。在 Node.js 中,一些流行的 ORM 框架包括 Sequelize(适用于关系型数据库)和 TypeORM,而流行的 ODM 框架包括 Mongoose(适用于 MongoDB)。
-
异步操作
Node.js 以其异步非阻塞的特性而闻名,因此在进行数据库访问时,通常会使用数据库驱动程序提供的异步 API 或者利用 Promise、async/await 等语法来处理异步操作,以避免阻塞整个应用程序。
-
连接池管理
为了提高数据库访问的性能和效率,通常会使用连接池管理工具来管理数据库连接。例如,在 Node.js 中,可以使用 generic-pool 等库来实现数据库连接池管理,以便在需要时从池中获取连接,并在使用完毕后释放连接。
25.1 MySQL
在web项目中我们经常要用到 MySQL 数据库,现在我们介绍一下在 Node.js 中该如何使用 MySQL 数据库。
25.1.1 安装依赖
要在 Node.js 中操作 MySQL ,首先需要安装一个名为 mysql 或 mysql2 的npm包。这两个模块都可以用于在 Node.js 中连接和操作 MySQL 数据库。可以通过以下命令安装:
# 安装mysql依赖包
npm install mysql
# 安装mysql2依赖包
npm install mysql2
25.1.2 MySQL 和 mysql2
mysql 和 mysql2 都是 Node.js 中用于连接和操作 MySQL 数据库的库。它们之间的主要区别如下:
-
安装方式:
mysql是官方推荐的库;而mysql2是一个第三方库,需要通过 npm 安装。 -
API 差异:
mysql和mysql2的 API 基本相同,但在某些细节上有所不同。例如,mysql2提供了 Promise 支持,使得异步操作更加方便。 -
性能:由于
mysql2使用了流式处理,因此在处理大量数据时,它的性能可能会优于 mysql。 -
社区支持:
mysql2是由 MySQL 官方维护的,因此它得到了更多的社区支持和更新。
如果您正在使用 Node.js,并且已经熟悉 mysql 库,那么继续使用它是完全可以的。但是,如果你想要一个更现代化、功能更丰富的库,或者你正在寻找更好的社区支持,那么可以考虑使用 mysql2。我们主要以 mysql2 为例。
25.1.3 建立连接
mysql.createConnection() 是 Node.js 中用于创建与 MySQL 数据库连接的方法。它创建一个表示与 Mysql 连接的 Connection 对象。
该方法接受一个包含连接配置的对象作为参数,并返回一个表示数据库连接的连接对象。通过该连接对象,可以执行各种数据库操作,如查询、插入、更新和删除等。
以下是 mysql.createConnection 方法的参数说明:
- host(可选):数据库服务器的主机名或 IP 地址。默认值为 localhost。
- user(可选):用于连接到数据库的用户名。默认值为 root。
- password(可选):用于连接到数据库的密码。默认值为空字符串。
- database(可选):要连接的数据库名称。默认值为 test。
- port(可选):数据库服务器的端口号。默认值为 3306。
- socketPath(可选):当未指定主机时使用的 Unix 套接字路径。默认值为空字符串。
- flags(可选):传递给底层驱动程序的标志。默认值为 ‘’。
- charset(可选):指定字符集编码。默认值为 ‘utf8mb4’。
- timezone(可选):指定时区。默认值为 ‘local’。
- connectTimeout(可选):连接超时时间,单位为毫秒。
- stringifyObjects:决定是否将对象转换为字符串。
- debug(可选):是否启用调试模式。默认值为 false。
- typeCast(可选):决定是否应该自动将从数据库接收的数据类型转换为JavaScript类型。
如果不需要数据库,可以使用 connection 的 end 或者 destroy 方法关闭数据库连接。
需要注意的是,mysql.createConnection 方法只会创建一个新的连接对象,但并不会建立实际的数据库连接。实际的连接会在调用 connection.connect 方法时建立。另外,每次使用 createConnection 创建数据库连接时,都会创建一个新的连接对象,因此在使用完毕后,应该及时调用 connection.end 方法关闭数据库连接,释放资源。
除了 mysql.createConnection 方法,mysql2 模块还提供了其他创建数据库连接的方法,如 mysql.createPool 和 mysql.createPoolCluster,它们适用于连接池和多个数据库服务器的情况。根据具体的需求,选择合适的方法来创建数据库连接。
const mysql = require('mysql');
// 创建连接对象
const connection = mysql.createConnection({
host: '127.0.0.1', // 数据库地址
user: 'root', // 数据库用户名
password: '123456', // 数据库密码
database: 'db_test', // 数据库名称
});
// 连接到数据库
connection.connect((err) => {
if (err) {
console.error('连接失败 err:', err);
return;
}
console.log('成功连接到数据库');
});
// 关闭数据库连接
connection.end();
注意:您需要自己先安装好 MySQL 软件,才能正常访问 MySQL 数据库。如果没有安装 MySQL 可以参考这篇文章:超详细的MySQL下载安装教程(免费社区版)
报错: Error: ER_NOT_SUPPORTED_AUTH_MODE: Client does not support authentication protocol requested by server; consider upgrading MySQL client
原因:MySQL 8.0.4开始,MySQL默认身份验证插件从 mysql_native_password 改为 caching_sha2_password 导致。
解决方法:
安装 mysql2 依赖:npm install mysql2,引入依赖 const mysql = require('mysql2'); 然后再次运行即可。
以下是 connection 对象常用的一些方法:
-
query(sql, values, callback):执行数据库查询操作。该方法接收一个 SQL 查询字符串或预处理语句,一个可选的参数数组 values,以及一个回调函数 callback。当查询完成时,callback 函数将被调用,它接收两个参数,第一个参数为错误信息(如果有),第二个参数为查询结果。
-
execute(sql, values, callback):执行数据库查询操作,并返回一个结果集对象。该方法接收一个 SQL 查询字符串或预处理语句,一个可选的参数数组 values,以及一个回调函数 callback。当查询完成时,callback 函数将被调用,它接收两个参数,第一个参数为错误信息(如果有),第二个参数为一个结果集对象,代表查询结果。
-
beginTransaction(callback):开启一个新的事务。该方法接收一个回调函数 callback。当事务开启后,callback 函数将被调用。
-
commit(callback):commit(callback):提交当前事务。该方法接收一个回调函数 callback。当提交成功后,callback 函数将被调用。
-
rollback(callback):回滚当前事务。该方法接收一个回调函数 callback。当回滚成功后,callback 函数将被调用。
-
ping(callback):测试数据库连接是否可用。该方法接收一个回调函数 callback。当连接可用时,callback 函数将被调用。
-
changeUser(options, callback):更改数据库连接的用户信息。该方法接收一个包含新用户信息的对象 options,以及一个回调函数 callback。当更改成功后,callback 函数将被调用。
-
end([callback]):关闭数据库连接。接受一个可选的回调函数作为参数,在连接关闭后执行。如果没有提供回调函数,则默认打印一条消息到控制台。该方法返回一个 Promise,当连接关闭时 resolve。
-
escape(value):将字符串转义为安全的 SQL 字符串。该方法接收一个字符串类型的参数 value,并返回一个已经转义的字符串。
-
format(sql, values):格式化 SQL 语句,并将参数列表中的值替换到 SQL 语句中。该方法接收一个 SQL 查询字符串或预处理语句,一个参数数组 values,并返回一个已经格式化的 SQL 语句。
-
promise():返回一个 Promise 对象,用于执行异步操作。
使用这些方法可以实现各种数据库操作,如查询、插入、更新、删除等。但是,在使用 query 或 execute 方法执行查询时,需要小心防范 SQL 注入攻击,避免在查询中使用未经过验证和转义的字符串。同时还需要注意,使用 beginTransaction 方法开启事务时,务必要确保在事务结束前使用 commit 或 rollback 方法结束事务,避免出现数据不一致的情况。
25.1.4 查询
connection.query 是一个用于执行 SQL 查询的方法,通常在 Node.js 中使用 mysql 模块与 MySQL 数据库进行交互时使用。它接受一个 SQL 查询语句作为参数,并返回一个 Promise,当查询完成时 resolve。
我们先创建一个数据表:
# 创建一张用户表
CREATE TABLE `t_user` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`name` VARCHAR(20) DEFAULT '' COMMENT '姓名',
`age` INT(11) DEFAULT 18 COMMENT '年龄',
`balance` DECIMAL(10,2) COMMENT '金额',
PRIMARY KEY(`id`)
)ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
#添加数据
INSERT INTO t_user(name, balance) VALUES('张三', 1200), ('李四', 500);
以下是一个示例代码,演示如何使用 connection.query 方法执行查询操作:
const mysql = require('mysql2');
// 创建连接对象 port(默认3306端口号)
const connection = mysql.createConnection({
host: '127.0.0.1', // 数据库地址
user: 'root', // 数据库用户名
password: '123456', // 数据库密码
database: 'db_test', // 数据库名称
});
// 连接到数据库
connection.connect((err) => {
if (err) {
console.error('连接失败:', err);
return;
}
console.log('成功连接到数据库');
});
// 执行查询操作(单条)
connection.query('SELECT * FROM t_user where id=1;', (err, results, fields) => {
if (err) {
console.error('查询失败:', err);
return;
}
console.log('查询结果:', results);
});
// // 执行查询操作(所有)
// connection.query('SELECT * FROM t_user', (err, results, fields) => {
// if (err) {
// console.error('查询失败:', err);
// return;
// }
// console.log('查询结果:', results);
// });
// 关闭数据库连接
connection.end();
注意:生产环境中尽量避免使用 select * 查询语句,应该使用 select 字段名1, 字段名2, ... 的方式去查询数据。
25.1.5 插入、更新和删除
connection.query 是一个用于执行 SQL 查询的方法可以完成插入、更新和删除等操作。
插入
下面是插入数据的例子:
const mysql = require('mysql2');
// 创建数据库连接 port(默认3306端口号)
const connection = mysql.createConnection({
host: '127.0.0.1', // 数据库地址
user: 'root', // 数据库用户名
password: '123456', // 数据库密码
database: 'db_test', // 数据库名称
});
// 连接到数据库
connection.connect((err) => {
if (err) {
throw err;
}
console.log('已连接到数据库');
// 插入一条数据
const sql = 'INSERT INTO t_user(name, age, balance) VALUES (?, ?, ?);';
const values = ['王五', 20, 0];
connection.query(sql, values, (err, result) => {
if (err) throw err;
console.log('数据插入成功');
console.log('插入的数据ID为:', result.insertId);
});
// 关闭数据库连接
connection.end();
});
注意:插入多条数据,可以使用for循环,先拼接好sql和values,然后去执行 connection.query 方法。
更新
下面是更新数据的示例:
const mysql = require('mysql2');
// 创建数据库连接 port(默认3306端口号)
const connection = mysql.createConnection({
host: '127.0.0.1', // 数据库地址
user: 'root', // 数据库用户名
password: '123456', // 数据库密码
database: 'db_test', // 数据库名称
});
// 连接到数据库
connection.connect((err) => {
if (err) {
throw err;
}
console.log('已连接到数据库');
// 更新数据
const sql = 'UPDATE t_user SET balance = ? WHERE id = ?;';
const values = [1000, 3]; // 假设要更新id为3的数据
connection.query(sql, values, (err, result) => {
if (err) throw err;
console.log('数据更新成功');
});
// 关闭数据库连接
connection.end();
});
注意:更新多条数据同样可以使用for循环来完成。
删除
下面是一条删除数据的案例:
const mysql = require('mysql2');
// 创建数据库连接 port(默认3306端口号)
const connection = mysql.createConnection({
host: '127.0.0.1', // 数据库地址
user: 'root', // 数据库用户名
password: '123456', // 数据库密码
database: 'db_test', // 数据库名称
});
// 连接到数据库
connection.connect((err) => {
if (err) {
throw err;
}
console.log('已连接到数据库');
// 删除数据
const sql = 'DELETE FROM t_user where id=?;';
const values = [3]; // 假设要删除id为3的数据
connection.query(sql, values, (err, result) => {
if (err) throw err;
console.log('数据更新成功');
});
// 关闭数据库连接
connection.end();
});
连接池
在 mysql2 中,连接池是一种管理数据库连接的机制,用于提高应用程序的性能和可靠性。连接池维护了一个固定数量的数据库连接,并将这些连接存储在一个池中。当应用程序需要访问数据库时,它从连接池中获取一个可用的连接,并在使用完毕后将连接返回到连接池中,以便其他请求可以重复利用该连接。
mysql2 提供了 mysql.createPool 方法用于创建连接池。该方法接收一个配置对象,其中包含连接池的参数,例如最大连接数、最小连接数、连接超时时间等。下面是一个创建连接池的示例代码:
const mysql = require('mysql2');
// 创建连接池
const pool = mysql.createPool({
host: '127.0.0.1', // 数据库地址
user: 'root', // 数据库用户名
password: '123456', // 数据库密码
database: 'db_test', // 数据库名称
connectionLimit: 10, // 最大连接数
queueLimit: 0 // 请求队列长度,0 表示不限制
});
// 从连接池中获取一个连接
pool.getConnection((err, connection) => {
if (err) {
console.error('无法获取数据库连接:', err);
return;
}
console.log('成功获取数据库连接');
// 执行数据库操作
connection.query('SELECT * FROM t_user', (err, results, fields) => {
if (err) {
console.error('执行查询失败:', err);
return;
}
console.log('查询结果:', results);
// 将连接返回到连接池中
connection.release();
console.log('成功返回数据库连接');
// 关闭连接池
pool.end((err) => {
if (err) {
console.error('关闭连接池失败:', err);
return;
}
console.log('成功关闭连接池');
});
});
});
在上面的代码中,首先使用 mysql.createPool 方法创建了一个连接池对象 pool,并设置了最大连接数为 10。然后使用 pool.getConnection 方法从连接池中获取一个连接对象 connection,并通过 connection.query 方法执行了一条查询语句。在查询完成后,通过 connection.release 方法将连接对象返回到连接池中,并使用 pool.end 方法关闭连接池。
需要注意的是,使用连接池时,应该始终在使用完毕后,将连接对象返回到连接池中,以便其他请求可以重复利用该连接。另外,在使用连接池时,应该遵循最佳实践,例如避免在查询中使用未经过验证和转义的字符串,避免在事务中同时使用多个连接对象等。
使用连接池可以有效地提高应用程序的性能和可靠性,减少因创建和释放连接而带来的开销和风险。在实际应用中,应该根据具体的需求和负载情况,合理地配置连接池的参数,以获得最佳的性能和可靠性。
25.1.7 事物操作
以下是一个使用 mysql2 实现事务操作的示例代码:
const mysql = require('mysql2');
// 创建连接池
const pool = mysql.createPool({
host: '127.0.0.1', // 数据库地址
user: 'root', // 数据库用户名
password: '123456', // 数据库密码
database: 'db_test', // 数据库名称
connectionLimit: 10
});
// 获取连接
pool.getConnection((err, connection) => {
if (err) {
console.error('无法获取数据库连接:', err);
return;
}
console.log('成功获取数据库连接');
// 开始事务
connection.beginTransaction((err) => {
if (err) {
console.error('开启事务失败:', err);
connection.release();
return;
}
// 执行事务中的 SQL 命令
connection.query('UPDATE t_user SET balance = balance - 100 WHERE id = 1', (err, result) => {
if (err) {
console.error('执行 SQL 失败:', err);
connection.rollback(() => {
console.log('回滚事务');
connection.release(); // 释放连接
});
return;
}
console.log('更新用户1余额:', result.affectedRows);
connection.query('UPDATE t_user SET balance = balance + 100 WHERE id = 2', (err, result) => {
if (err) {
console.error('执行 SQL 失败:', err);
connection.rollback(() => {
console.log('回滚事务');
connection.release(); // 释放连接
});
return;
}
console.log('更新用户2余额:', result.affectedRows);
// 提交事务
connection.commit((err) => {
if (err) {
console.error('提交事务失败:', err);
connection.rollback(() => {
console.log('回滚事务');
connection.release(); // 释放连接
});
return;
}
console.log('成功提交事务');
connection.release(); // 释放连接
// 关闭连接池
pool.end((err) => {
if (err) {
console.error('关闭连接池失败:', err);
return;
}
console.log('成功关闭连接池');
});
});
});
});
});
});
在上述示例中,首先使用 mysql2 创建了一个连接池对象 pool,然后使用 pool.getConnection 方法获取了一个连接对象 connection。接着,通过调用 connection.beginTransaction 方法开始了一个事务,并在事务中执行了两条 SQL 命令:一条更新用户余额的命令和一条创建订单的命令。如果执行 SQL 出现错误,将会回滚事务并释放连接。如果两条 SQL 命令都执行成功,将通过调用 connection.commit 方法提交事务,并在提交事务后释放连接。
需要注意的是,在使用事务时,应该始终将相关操作放在事务中,并确保在事务结束后,通过调用 connection.commit 方法提交事务或者调用 connection.rollback 方法回滚事务。另外,在使用事务时,应该遵循最佳实践,例如避免在事务中同时使用多个连接对象等。
25.1.8 防止 SQL 注入
mysql2 本身并不能直接防止 SQL 注入攻击。然而,通过合理使用 mysql2 提供的功能和一些最佳实践,可以有效地防止 SQL 注入。
以下是一些方法来防止 SQL 注入攻击:
- 使用参数化查询:使用占位符或预处理语句来将用户输入作为参数传递给查询,而不是将其直接嵌入到 SQL 查询字符串中。这样可以确保用户输入不会被误解为 SQL 代码,从而减少了 SQL 注入的风险。
const mysql = require('mysql2/promise');
const connection = await mysql.createConnection({/* connection config */});
const query = 'SELECT * FROM users WHERE username = ? AND password = ?';
const [rows, fields] = await connection.execute(query, [username, password]);
在上面的示例中,? 是占位符,后面的数组 [username, password] 是实际的参数值。mysql2 会在执行查询时自动将这些参数转义,以避免注入攻击。
-
输入验证与过滤:在将用户输入用作查询参数之前,进行必要的验证和过滤。验证可以确保输入符合预期的格式和类型,而过滤可以去除敏感字符或特殊字符,以防止恶意注入。
-
使用存储过程或函数:将复杂的查询逻辑封装在数据库的存储过程或函数中,并通过调用这些过程或函数来执行查询。这样可以减少直接在应用程序中编写 SQL 查询的机会,从而降低注入攻击的风险。
-
最小权限原则:为数据库用户分配最小的权限,只给予其执行必要操作的权限。这样即使发生注入攻击,攻击者也只能获得有限的权限,减少了损害的范围。
为了确保应用程序的安全性,还应该定期更新 mysql2 和其他相关库,并遵循最新的安全建议。
25.2 MongoDB
MongoDB 是一个流行的开源 NoSQL 数据库,它以文档的形式存储数据。在 Node.js 中操作 MongoDB 数据库通常使用 mongodb 或 mongoose 模块,这两个模块都可以用于在 Node.js 中连接和操作 MongoDB 数据库。下面我们将详细介绍如何使用 MongoDB 数据库的操作。
25.2.1 安装MongoDB驱动
Node.js 提供了许多模块来连接和操作 MongoDB 数据库,其中最常用的是官方的 MongoDB 驱动程序模块。
安装依赖
# 安装 mongodb 依赖包
npm install mongodb
25.2.2 MongoClient
MongoClient 是 MongoDB 官方提供的用于连接和与 MongoDB 数据库进行交互的驱动程序。它是 MongoDB Node.js 驱动程序的核心组件之一。
MongoClient 类提供了一组方法,使您能够在 Node.js 环境中连接到 MongoDB 数据库,并执行各种数据库操作,例如插入、查询、更新和删除文档等。
下面是 MongoClient 类的一些常用属性和方法:
属性
-
db 属性是一个函数,用于选择指定的数据库并返回一个 Db 对象。您可以在 Db 对象上执行各种数据库操作。
-
topology:topology 属性是一个表示 MongoDB 连接拓扑结构的对象。它提供了一些有用的信息,例如连接状态、服务器列表、拓扑结构类型等。您可以使用 topology 属性来了解 MongoDB 客户端与 MongoDB 服务器之间的连接情况。
方法
-
connect():连接到 MongoDB 数据库并返回一个 Promise 对象。
-
close(force?: boolean, callback?: function):关闭数据库连接。您可以选择是否强制关闭连接(即忽略未完成的操作)。如果不提供回调函数,则返回一个 Promise 对象。
-
db(dbName: string, options?: object):选择指定的数据库。这将返回一个 Db 对象,它表示对特定数据库的操作。您可以在 Db 对象上执行各种数据库操作。
options参数说明:
-
authSource: 一个字符串,表示用于进行身份验证的数据库名称。如果 MongoDB 使用了身份验证,并且要连接的数据库与身份验证数据库不同,则需要设置此选项。
-
authMechanism: 一个字符串,指定要使用的身份验证机制。常用的机制包括 MONGODB-CR、SCRAM-SHA-1 和 SCRAM-SHA-256 等。默认情况下,驱动程序会自动选择适当的机制。
-
authMechanismProperties: 一个对象,包含要传递给身份验证机制的属性。这个选项通常与 authMechanism 一起使用。例如:{ SERVICE_NAME: ‘mongodb’, CANONICALIZE_HOST_NAME: true }。
-
readConcern: 一个对象,表示读取的一致性保证级别。常用的级别包括 local、majority 和 linearizable 等。
-
readPreference: 一个字符串或对象,表示读取偏好。常用的偏好类型包括 primary、secondary 和 nearest 等。
-
pkFactory: 一个对象,用于自定义主键生成算法。这个选项通常用于自定义主键字段的名称和值生成方法。
-
retryWrites:指定在写操作失败时是否自动重试,默认true。
client.db(dbName) 返回的是一个 MongoDB 数据库对象(db)。这个对象代表了与指定数据库名称相对应的数据库。
使用数据库对象后,您可以执行各种数据库操作,如创建集合、插入数据、查询数据等。
以下是一些常用的数据库操作方法:
- db.collection(collectionName):获取指定集合名称的集合对象。通过集合对象可以执行与该集合相关的操作,如插入文档、更新文档、删除文档等。
- db.dropDatabase():删除当前数据库。谨慎使用此方法,因为删除数据库将会同时删除该数据库中的所有集合和数据。
- db.listCollections():获取当前数据库中的所有集合列表。
- db.createCollection(collectionName, options):创建一个新的集合。collectionName 参数指定要创建的集合的名称,options 是一个可选的配置对象,用于指定集合的创建选项,例如指定索引、存储引擎等。
-
-
startSession(options?: object):启动一个会话对象。会话对象可用于执行事务或使用事务相关的操作。
options参数说明:
-
causalConsistency: 一个布尔值,表示会话是否支持因果一致性。默认情况下,会话是支持因果一致性的。启用因果一致性可以确保操作按照它们在应用程序中执行的顺序进行提交。
-
defaultTransactionOptions: 一个对象,表示会话的默认事务选项。事务选项用于指定事务的隔离级别、超时时间等参数。默认情况下,会话的默认事务选项为空对象。
-
snapshot: 一个布尔值,表示在会话中的读操作是否使用快照隔离。如果设置为 true,则读操作将在事务开始时获取快照,并在整个事务期间保持一致性。默认情况下,会话的读操作不使用快照隔离。
-
readConcern: 一个对象,表示会话的读取一致性级别。常用的级别包括 local、majority 和 linearizable 等。默认情况下,会话的读取一致性级别与数据库的默认读取一致性级别相同。
-
writeConcern: 一个对象,表示会话的写入一致性级别。常用的级别包括 majority、j 和 wtimeout 等。默认情况下,会话的写入一致性级别与数据库的默认写入一致性级别相同。
-
defaultTransactionOptions: 一个对象,表示会话的默认事务选项。事务选项用于指定事务的隔离级别、超时时间等参数。默认情况下,会话的默认事务选项为空对象。
-
-
withSession(callback: function):在一个新会话中执行给定的回调函数。此方法简化了使用会话对象的流程。
-
watch():方法用于实时监视 MongoDB 中的变化。它可以监听集合的插入、更新和删除操作,并在发生这些操作时触发回调函数。
其他方法:listDatabases()、listCollections() 等。
连接MongoDB数据库
new MongoClient(uri, options) 是使用 Node.js 客户端连接 MongoDB 数据库时创建 MongoClient 实例的方式之一。MongoClient 是 MongoDB 官方提供的用于连接和与 MongoDB 数据库进行交互的驱动程序。
options参数说明:
-
appname: 一个字符串,表示应用程序名称。在 MongoDB 4.4 及以上版本中引入,可以通过查看 system.sessions 集合来了解哪些应用程序正在访问数据库。
-
auth: 一个对象,包含要使用的身份验证凭证。常用的凭证类型包括
user和password。例如:{ user: 'john', password: 'secret' }。 -
authMechanism: 一个字符串,指定要使用的身份验证机制。常用的机制包括 MONGODB-CR、SCRAM-SHA-1 和 SCRAM-SHA-256 等。默认情况下,驱动程序会自动选择适当的机制。
-
authMechanismProperties: 一个对象,包含要传递给身份验证机制的属性。这个选项通常与
authMechanism一起使用。例如:{ SERVICE_NAME: 'mongodb', CANONICALIZE_HOST_NAME: true }。 -
authSource: 一个字符串,表示用于进行身份验证的数据库名称。如果 MongoDB 使用了身份验证,并且要连接的数据库与身份验证数据库不同,则需要设置此选项。
-
compressors: 一个字符串数组,表示要使用的压缩算法。可用的算法包括 snappy、zlib 和 zstd 等。默认情况下,驱动程序会自动选择适当的算法。
-
connectTimeoutMS: 一个整数,表示连接超时时间(毫秒)。如果在指定的时间内无法连接到 MongoDB 服务器,则会引发异常。
-
directConnection: 一个布尔值,表示是否直接连接 MongoDB 服务器。如果设置为 false,则使用 MongoDB 路由器进行连接。
-
family: 一个整数,表示要使用的 IP 地址族。可选值包括 4 和 6,分别表示 IPv4 和 IPv6。如果未指定,则自动检测。
-
ha: 一个布尔值,表示是否启用高可用性(HA)模式。如果设置为 true,则驱动程序会自动重试连接多个副本集成员或多个分片节点。
-
ignoreUndefined: 一个布尔值,表示是否忽略未定义的属性。如果设置为 true,则在插入文档时不会包含未定义的属性。
-
maxPoolSize:一个数字值,表示连接池中的最大连接数。默认情况下,其值为 100。当达到最大连接数时,新的连接请求将等待直到有可用的连接。增加 maxPoolSize 可以增加并发连接的能力,但也会增加系统资源的使用。
-
minPoolSize:一个数字值,表示连接池中的最小连接数。默认情况下,其值为 0。连接池会在启动时创建 minPoolSize 个连接,并保持这个数量的空闲连接。如果连接池中没有足够的空闲连接,则会按需创建新的连接,直到达到 maxPoolSize。
-
maxStalenessSeconds: 一个整数,表示最大允许的数据延迟时间(秒)。如果指定了此选项,则在查询时会优先选择数据比本地更新的节点。这个选项通常与读取偏好一起使用。
-
readConcern: 一个对象,表示读取的一致性保证级别。常用的级别包括 local、majority 和 linearizable 等。
-
readPreference: 一个字符串或对象,表示读取偏好。常用的偏好类型包括 primary、secondary 和 nearest 等。
-
replicaSet: 一个字符串,表示要连接的副本集名称。如果要连接的是分片集群,则不需要设置此选项。
-
serverSelectionTimeoutMS: 一个整数,表示选择服务器的超时时间(毫秒)。如果在指定的时间内无法选择服务器,则会引发异常。
-
socketTimeoutMS: 一个整数,表示套接字超时时间(毫秒)。如果在指定的时间内没有收到响应,则会引发异常。
-
ssl: 一个布尔值,表示是否使用 SSL/TLS 加密连接到 MongoDB 服务器。
-
tls: 一个布尔值或对象,表示是否使用 TLS 加密连接到 MongoDB 服务器。如果设置为 true,则使用默认的 TLS 设置。如果是一个对象,则可以指定自定义的 TLS 设置。
-
tlsAllowInvalidCertificates: 如果设置为 true,则在建立 TLS 连接时不会验证服务器证书。默认情况下,驱动程序会验证服务器证书,并在证书无效时引发异常。
-
tlsCAFile: 一个字符串,表示要使用的 CA 文件的路径。这个选项通常用于指定自签名证书的 CA。如果未指定,则使用操作系统的默认 CA。
-
tlsCertificateKeyFile: 一个字符串,表示要使用的客户端证书和私钥文件的路径。如果要使用 X.509 证书进行身份验证,则需要设置此选项。
-
tlsCertificateKeyFilePassword: 一个字符串,表示客户端证书和私钥文件的密码。如果证书和私钥文件加密了,则需要设置此选项。
-
w: 一个整数或字符串,表示写入的一致性保证级别。常用的级别包括 majority、j 和 wtimeout 等。
-
waitQueueTimeoutMS: 一个整数,表示等待队列的超时时间(毫秒)。如果等待队列已满,并且在指定的时间内没有可用连接,则会引发异常。
使用 MongoClient 类连接 MongoDB 的基本流程如下:
-
创建一个
MongoClient实例,并传递 MongoDB 连接字符串和选项(可选)。 -
调用
connect()方法来连接到 MongoDB 数据库。在成功连接后,您可以选择指定的数据库。 -
在所选数据库上执行各种数据库操作,例如插入、查询、更新和删除文档等。
-
使用
close()方法关闭数据库连接。
下面是使用 new MongoClient 创建 MongoClient 实例并连接到 MongoDB 数据库的示例代码:
const { MongoClient } = require('mongodb');
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
const client = new MongoClient(uri);
async function connectToMongo() {
try {
await client.connect();
console.log('Connected to MongoDB');
const db = client.db('db_crm');
// 继续执行其他操作...
// 关闭连接
await client.close();
} catch (err) {
console.error('Failed to connect to MongoDB', err);
}
}
connectToMongo();
在上述代码中,我们首先创建了一个 MongoClient 实例,将 MongoDB 连接 URL 和选项传递给构造函数。然后使用 connect 方法来连接到 MongoDB 数据库。在成功连接后,可以选择指定的数据库,并执行数据库操作。最后,使用 close 方法关闭数据库连接。
uri解析:
uri中的crm是用户名;:123456的密码是123456;@127.0.0.1:27017指定mongodb数据库服务器的地址;/db_crm就是数据库;authSource表示这个数据库将用于验证用户的凭证。
注意:authSource 是 MongoDB 连接选项中的一个参数,用于指定身份验证数据库。当使用 MongoDB 的身份验证功能时,需要在连接时指定身份验证的数据库。默认情况下,MongoDB 客户端会在 admin 数据库上进行身份验证。
通常情况下 authSource 默认为admin数据库。MongoDB 会将用户凭证存储在 admin 数据库中,如果您的用户凭证是在其他数据库,那么就必须明确指定 authSource。
25.2.3 连接池
在使用 MongoClient 连接 MongoDB 数据库时,可以使用连接池来管理和重用数据库连接,以提高性能和效率。连接池可以在应用程序启动时创建一组初始连接,并在需要时将连接分配给请求,完成后将连接返回到连接池中。
以下是使用连接池的示例代码:
const { MongoClient } = require('mongodb');
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
const client = new MongoClient(uri);
const options = {
maxPoolSize: 50, // 设置最大连接数为 50
minPoolSize: 10 // 设置最小连接数为 10
};
const client = new MongoClient(uri, options);
async function connectToDatabase() {
try {
await client.connect();
console.log('Connected to the database!');
} catch (err) {
console.error('Failed to connect to the database:', err);
}
}
connectToDatabase();
在这个示例中,我们使用 MongoClient 创建了一个连接池,并设置了 maxPoolSize 和 minPoolSize 参数。然后我们通过调用 MongoClient.connect() 方法来获取一个 MongoClient 实例。
请注意,我们在 finally 代码块中使用 client.close() 方法关闭了 MongoClient 实例。这非常重要,因为它会释放连接池中的连接,以便其他客户端可以使用它们。
25.2.4 插入数据
需要通过 MongoClient.connect() 方法来连接到 MongoDB 服务器,并获取一个数据库实例。然后,使用数据库实例的 collection() 方法获取要插入数据的集合。
下面我们将详细介绍一些常用的插入数据的方法。
插入单个文档
如果您想插入单个文档(也就是一条记录),可以使用集合的 insertOne() 方法。这个方法接受一个文档对象作为参数,并返回一个 Promise,当 Promise 被解析时,表示插入操作成功。
const { MongoClient } = require('mongodb');
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
const client = new MongoClient(uri);
async function insertDocument() {
try {
await client.connect();
console.log('Connected to MongoDB');
const db = client.db('db_crm');
const collection = db.collection('student');
const document = { name: 'John', age: 30 };
const result = await collection.insertOne(document);
console.log('Inserted document with _id:', result.insertedId);
} catch (e) {
console.error(e);
} finally {
await client.close();
}
}
insertDocument();
在这个示例中,我们首先创建一个 MongoClient 实例,并调用 connect() 方法连接到 MongoDB 服务器。然后,我们使用 collection() 方法获取名为 mycollection 的集合。接下来,我们定义一个要插入的文档对象,并使用 insertOne() 方法将文档插入到集合中。最后,我们打印插入文档的 _id 值。
插入成功后返回id:
ydcq@ydcqdeMac-mini ~ % node /Users/ydcq/Desktop/web/node_demo/demo.js
Connected to MongoDB
Inserted document with _id: new ObjectId('658bf88696586ce3528da6d4')
ydcq@ydcqdeMac-mini ~ %
插入多个文档
如果您想一次性插入多个文档,可以使用集合的 insertMany() 方法。这个方法接受一个文档数组作为参数,并返回一个 Promise,当 Promise 被解析时,表示插入操作成功。
以下是一个示例:
const { MongoClient } = require('mongodb');
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
const client = new MongoClient(uri);
async function insertDocuments() {
try {
await client.connect();
console.log('Connected to MongoDB');
const db = client.db('db_crm');
const collection = db.collection('student');
const documents = [
{ name: 'John', age: 30 },
{ name: 'Alice', age: 25 },
{ name: 'Bob', age: 35 }
];
const result = await collection.insertMany(documents);
console.log('Inserted', result.insertedCount, 'documents');
} catch (e) {
console.error(e);
} finally {
await client.close();
}
}
insertDocuments();
在这个示例中,我们使用 insertMany() 方法将多个文档一次性插入到集合中。我们定义了一个包含多个文档的数组,并将其作为参数传递给 insertMany() 方法。最后,我们打印插入的文档数量。
成功后返回插入的数据个数:
ydcq@ydcqdeMac-mini ~ % node /Users/ydcq/Desktop/web/node_demo/demo.js
Connected to MongoDB
Inserted 3 documents
ydcq@ydcqdeMac-mini ~ %
除了上述的 insertOne() 和 insertMany() 方法之外,MongoDB 还提供了其他一些插入数据的方法,例如 insert()。这些方法具有相似的用法,但可能在细节上有一些差异。根据你的需求选择适合的方法即可。
需要注意的是,插入操作是原子的,要么全部成功,要么全部失败。如果插入过程中出现错误,整个操作将会回滚,并且不会插入部分数据。
25.2.5 查询
MongoClient 是 MongoDB 官方提供的 Node.js 驱动程序,用于与 MongoDB 数据库进行交互。通过 MongoClient 对象,您可以执行各种数据库操作,包括查询数据。
以下是一些常见的查询方法:
findOne()
如果您想查询集合中的单个文档(即一条记录),可以使用集合的 findOne(query, projection) 方法。它接受两个参数:query 是一个可选的查询条件对象,用于指定要查询的文档,projection 是一个可选的投影对象,用于指定要返回的字段,并返回一个 Promise,当 Promise 被解析时,表示查询操作成功。
以下是一个示例:
const { MongoClient } = require('mongodb');
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
const client = new MongoClient(uri);
async function findOneDocument() {
try {
await client.connect();
console.log('Connected to MongoDB');
const db = client.db('db_crm');
const collection = db.collection('student');
const query = { name: 'John' };
const document = await collection.findOne(query);
console.log('Document=', document);
} catch (e) {
console.error(e);
} finally {
await client.close();
}
}
findOneDocument();
在这个示例中,我们首先创建一个 MongoClient 实例,并调用 connect() 方法连接到 MongoDB 服务器。然后,我们使用 collection() 方法获取名为 mycollection 的集合。接下来,我们定义一个查询条件对象,并使用 findOne() 方法查找符合条件的文档。最后,我们打印查询到的文档对象。
find()
如果您想查询集合中的多个文档,可以使用集合的 find(query, projection) 方法。它接受两个参数:query 是一个可选的查询条件对象,用于指定要查询的文档,projection 是一个可选的投影对象,用于指定要返回的字段,并返回一个游标对象(cursor)。通过游标对象,您可以逐个遍历查询结果集中的文档。
以下是一个示例:
const { MongoClient } = require('mongodb');
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
const client = new MongoClient(uri);
async function findDocuments() {
try {
await client.connect();
console.log('Connected to MongoDB');
const db = client.db('db_crm');
const collection = db.collection('student');
const query = { age: { $gt: 25 } }; // 查询年龄大于 25 岁的文档
const cursor = collection.find(query);
await cursor.forEach((document) => {
console.log(document);
});
} catch (e) {
console.error(e);
} finally {
await client.close();
}
}
findDocuments();
在这个示例中,我们使用 find() 方法查询年龄大于 25 岁的文档。查询结果以游标对象的形式返回,并可以通过 forEach() 方法逐个遍历结果集中的文档。在循环体内,我们打印每个文档对象。
要实现分页、限制个数和排序,可以在 find() 方法中使用以下几个选项:
skip():用于指定要跳过的文档数量,实现分页效果。
limit():用于限制返回的文档数量。
sort():用于指定排序规则。
以下是示例代码,演示了如何使用 find() 方法实现分页、限制个数和排序:
const { MongoClient } = require('mongodb');
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
const client = new MongoClient(uri);
async function findDocuments() {
try {
await client.connect();
console.log('Connected to MongoDB');
const db = client.db('db_crm');
const collection = db.collection('student');
const query = { age: { $gt: 25 } }; // 查询年龄大于 25 岁的文档
const skip = 0; // 跳过的文档数量,即起始位置
const limit = 10; // 返回的文档数量
const sort = { age: 1 }; // 根据年龄升序排序
const cursor = collection.find(query).skip(skip).limit(limit).sort(sort);
await cursor.forEach((document) => {
console.log(document);
});
} catch (e) {
console.error(e);
} finally {
await client.close();
}
}
findDocuments();
在上述示例中,我们使用 find() 方法查询年龄大于 25 岁的文档,并根据指定的选项进行分页、限制个数和排序。具体地:
- skip(0) 跳过了
0个文档,可以根据当前页数和每页显示的数量计算出要跳过的文档数量。 - limit(10) 限制返回的文档数量为 10,可以根据每页显示的数量设置该值。
- sort({ age: 1 }) 按照年龄字段升序进行排序,可以根据需求指定其他字段和排序规则。
通过上述代码,您可以实现分页、限制个数和排序的查询操作,并根据具体需求进行相应的调整。
countDocuments()
countDocuments(query) 方法用于计算满足查询条件的文档数量。它接受一个查询条件对象作为参数(query 是一个可选的查询条件对象,用于指定要查询的文档。),并返回一个 Promise,当 Promise 被解析时,表示查询操作成功,并返回满足条件的文档数量。
以下是 countDocuments() 方法的示例用法:
const { MongoClient } = require('mongodb');
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
const client = new MongoClient(uri);
async function countDocuments() {
try {
await client.connect();
console.log('Connected to MongoDB');
const db = client.db('db_crm');
const collection = db.collection('student');
const query = { age: { $gt: 25 } }; // 查询年龄大于 25 岁的文档
const count = await collection.countDocuments(query);
console.log('Count:', count);
} catch (e) {
console.error(e);
} finally {
await client.close();
}
}
countDocuments();
在上述示例中,我们使用 countDocuments() 方法查询年龄大于 25 岁的文档数量,并将结果打印出来。
distinct()
distinct(field, query) 方法用于获取指定字段的唯一值列表。它接受一个字段名和一个查询条件对象作为参数,并返回一个 Promise,当 Promise 被解析时,表示查询操作成功,并返回该字段的唯一值数组。
以下是 distinct() 方法的示例用法:
const { MongoClient } = require('mongodb');
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
const client = new MongoClient(uri);
async function distinctFieldValues() {
try {
await client.connect();
console.log('Connected to MongoDB');
const db = client.db('db_crm');
const collection = db.collection('student');
const fieldName = 'age';
const query = { name: 'John' };
const values = await collection.distinct(fieldName, query);
console.log('Distinct values:', values);
} catch (e) {
console.error(e);
} finally {
await client.close();
}
}
distinctFieldValues();
在上述示例中,我们使用 distinct() 方法获取名为 age 字段的唯一值列表,查询条件为 name: 'John'。最后,我们将结果打印出来。
aggregate()
aggregate(pipeline) 方法用于执行复杂的聚合操作。它接受一个聚合管道数组作为参数 (pipeline 是一个由多个聚合阶段组成的数组,每个阶段都是一个对象,表示要执行的具体操作。),并返回一个游标对象(cursor)。通过聚合管道,您可以按照指定的顺序对文档进行多个阶段的处理,例如筛选、排序、分组、计算等。
以下是 aggregate() 方法的示例用法:
const { MongoClient } = require('mongodb');
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
const client = new MongoClient(uri);
async function performAggregation() {
try {
await client.connect();
console.log('Connected to MongoDB');
const db = client.db('db_crm');
const collection = db.collection('student');
const pipeline = [
{ $match: { age: { $gt: 25 } } }, // 筛选年龄大于 25 岁的文档
{ $group: { _id: '$gender', count: { $sum: 1 } } }, // 按性别分组并计数
{ $sort: { count: -1 } } // 按计数结果降序排序
];
const cursor = collection.aggregate(pipeline);
await cursor.forEach((document) => {
console.log(document);
});
} catch (e) {
console.error(e);
} finally {
await client.close();
}
}
performAggregation();
在上述示例中,我们使用 aggregate() 方法执行了一个聚合操作。聚合管道数组包含三个阶段:筛选年龄大于 25 岁的文档、按性别分组并计数、按计数结果降序排序。最后,我们通过游标对象遍历查询结果集中的文档,并将每个文档打印出来。
25.2.6 更新
通过 MongoClient,您可以执行各种数据库操作,包括更新数据。以下是一些常用的 MongoClient 更新方法:
updateOne(filter, update, options)
更新满足指定条件的单个文档。
参数说明:
- filter 参数是一个对象,用于指定要更新的文档的筛选条件。
- update 参数是一个对象,用于指定要应用于匹配文档的更新操作。
- options 参数是一个可选的对象,用于指定更新操作的选项,如 upsert(如果匹配的文档不存在,则插入新文档)和 multi(如果存在多个匹配的文档,是否更新所有文档)等。
示例:
const { MongoClient } = require('mongodb');
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
const client = new MongoClient(uri);
async function updateDocument() {
try {
await client.connect();
console.log('Connected to MongoDB');
const db = client.db('db_crm');
const collection = db.collection('student');
const filter = { name: 'John' }; // 筛选条件为 name 字段等于 'John'
const update = { $set: { age: 30 } }; // 更新 age 字段为 30
const result = await collection.updateOne(filter, update);
console.log(result.modifiedCount); // 输出修改的文档数量
} catch (e) {
console.error(e);
} finally {
await client.close();
}
}
updateDocument();
updateMany(filter, update, options)
更新满足指定条件的多个文档,使用方法与 updateOne() 类似。
示例:
const { MongoClient } = require('mongodb');
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
const client = new MongoClient(uri);
async function updateDocuments() {
try {
await client.connect();
console.log('Connected to MongoDB');
const db = client.db('db_crm');
const collection = db.collection('student');
const filter = { category: 'electronics' }; // 筛选条件为 category 字段等于 'electronics'
const update = { $inc: { quantity: -1 } }; // 将 quantity 字段减 1
const result = await collection.updateMany(filter, update);
console.log(result.modifiedCount); // 输出修改的文档数量
} catch (e) {
console.error(e);
} finally {
await client.close();
}
}
updateDocuments();
replaceOne(filter, replacement, options)
替换满足指定条件的单个文档。
参数说明:
- filter 参数是一个对象,用于指定要替换的文档的筛选条件。
- replacement 参数是一个对象,表示用于替换文档的新文档。
示例:
const { MongoClient } = require('mongodb');
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
const client = new MongoClient(uri);
async function replaceDocument() {
try {
await client.connect();
console.log('Connected to MongoDB');
const db = client.db('db_crm');
const collection = db.collection('student');
const filter = { name: 'Alice' }; // 筛选条件为 name 字段等于 'Alice'
const replacement = { name: 'Bob', age: 25 }; // 替换为新文档
const result = await collection.replaceOne(filter, replacement);
console.log(result.modifiedCount); // 输出修改的文档数量
} catch (e) {
console.error(e);
} finally {
await client.close();
}
}
replaceDocument();
通过使用这些更新方法,您可以根据指定的筛选条件更新满足条件的单个或多个文档,并且可以选择替换文档或应用特定的更新操作。
请注意,这些方法返回的结果对象包含有关更新操作的信息,如修改的文档数量等。
25.2.7 删除
通过 MongoClient,您可以执行各种数据库操作,包括删除数据。以下是一些常用的 MongoClient 删除方法
deleteOne(filter, options)
删除满足指定条件的单个文档。
参数说明:
- filter 参数是一个对象,用于指定要删除的文档的筛选条件。
- options 参数是一个可选的对象,用于指定删除操作的选项,如 collation(指定排序规则)和 writeConcern(写入确认级别)等。
示例:
const { MongoClient } = require('mongodb');
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
const client = new MongoClient(uri);
async function deleteDocument() {
try {
await client.connect();
console.log('Connected to MongoDB');
const db = client.db('db_crm');
const collection = db.collection('student');
const filter = { name: 'John' }; // 筛选条件为 name 字段等于 'John'
const result = await collection.deleteOne(filter);
console.log(result.deletedCount); // 输出删除的文档数量
} catch (e) {
console.error(e);
} finally {
await client.close();
}
}
deleteDocument();
deleteMany(filter, options)
删除满足指定条件的多个文档,使用方法与 deleteOne() 类似。
示例:
const { MongoClient } = require('mongodb');
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
const client = new MongoClient(uri);
async function deleteDocument() {
try {
await client.connect();
console.log('Connected to MongoDB');
const db = client.db('db_crm');
const collection = db.collection('student');
const filter = { category: 'electronics' }; // 筛选条件为 category 字段等于 'electronics'
const result = await collection.deleteMany(filter);
console.log(result.deletedCount); // 输出删除的文档数量
} catch (e) {
console.error(e);
} finally {
await client.close();
}
}
deleteDocuments();
通过使用这些删除方法,您可以根据指定的筛选条件删除满足条件的单个或多个文档。这些方法返回的结果对象包含有关删除操作的信息,如删除的文档数量等。
请注意,在执行删除操作之前,请确保连接到正确的 MongoDB 数据库,并且具有适当的权限来执行删除操作。
25.2.8 事物操作
在事务中执行数据库操作。可以使用 session.withTransaction() 方法来执行事务操作。以下是一个例子:
const { MongoClient } = require('mongodb');
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
const client = new MongoClient(uri);
async function performTransaction() {
await client.connect();
console.log('Connected to MongoDB');
const db = client.db('db_crm');
const collection = db.collection('student');
const session = client.startSession();
try {
await session.withTransaction(async () => {
// 在事务中执行数据库操作
await collection.insertOne({ name: 'John Doe' });
await collection.updateOne({ name: 'Jane Smith' }, { $set: { age: 30 } });
});
console.log('Transaction committed successfully.');
} catch (err) {
console.error('Transaction aborted:', err);
} finally {
session.endSession();
await client.close();
}
}
performTransaction();
在上面的例子中,使用 session.withTransaction() 方法包装需要在事务中执行的数据库操作。如果所有操作都成功完成,事务将被提交。如果任何操作失败或抛出异常,事务将被中止并回滚。
总结
Node.js 提供了丰富的数据库访问工具和库,使我们能够与各种类型的数据库进行交互和操作。无论使用哪种方法进行数据库访问,都需要注意安全性和性能方面的考虑,比如防止 SQL 注入攻击、合理利用数据库索引、优化查询语句等。同时,建议在进行数据库访问时,进行良好的错误处理和日志记录,以便及时发现和解决潜在的问题。
26-ORM操作数据库
ORM(对象关系映射)框架是一种用于简化数据库操作和管理的工具。ORM 将数据库表格转换为面向对象的模型,使得开发者可以使用类或对象的方式操作数据库,而不必直接编写 SQL 语句。
ORM 的主要目的是简化数据库访问代码的编写,并提高代码的可读性和可维护性。它可以使开发者更加专注于业务逻辑的实现,而不是过多地关注数据库的实现细节。
下面我们详细介绍一下 Sequelize 和 Mongoose 这两个 ORM 框架的相关知识:
26.1 Sequelize
Sequelize 是一个基于 Node.js 的 ORM(对象关系映射)框架,它支持多种数据库系统,包括 PostgreSQL、MySQL、SQLite 和 MSSQL。Sequelize 提供了强大的功能,包括模型定义、数据验证、查询构建、事务处理等,使得开发者能够以面向对象的方式来操作数据库。
以下是 Sequelize 的一些主要特点和用法:
-
模型定义:使用 Sequelize,你可以定义数据库表格对应的模型,以及它们之间的关联关系。这样就能够以面向对象的方式来操作数据库,而无需直接编写 SQL 语句。
-
查询构建:Sequelize 提供了丰富的 API 来构建数据库查询,包括条件查询、排序、分页、聚合函数等,使得操作数据库变得更加灵活和方便。
-
数据验证:Sequelize 支持定义模型属性的数据验证规则,以确保数据的完整性和一致性。
-
事务处理:Sequelize 支持事务处理,使得在数据库操作中可以保持数据的一致性。
-
多数据库支持:Sequelize 不仅支持多种数据库系统,还提供了丰富的插件和扩展功能,以满足不同项目的需求。
26.1.1 安装
安装 Sequelize:首先,你需要在你的项目中安装 Sequelize 包。可以使用 npm 命令进行安装:
shell
npm install sequelize
安装数据库驱动程序:Sequelize 支持多种数据库,你需要根据所使用的数据库类型安装相应的驱动程序。例如,如果你使用的是 MySQL 数据库,可以安装 mysql2 驱动:
npm install mysql2
26.1.2 配置数据库连接
在使用 Sequelize 之前,你需要配置数据库连接。创建一个 sequelize 对象并传入数据库连接信息:
const { Sequelize } = require('sequelize');
const sequelize = new Sequelize('db_test', 'root', '123456', {
host: '127.0.0.1',
dialect: 'mysql' // 或者 'postgres'、'sqlite'、'mssql' 等
});
// 连接是否成功
async function testConnection() {
try {
await sequelize.authenticate();
console.log('Database connection successfully.');
} catch (error) {
console.error('Unable to connect to the database:', error);
}
}
// 调用测试连接函数
testConnection();
26.1.3 连接池
在 Sequelize 中,可以通过配置连接池来管理数据库连接。连接池是一组已经建立的、可重用的数据库连接,用于提高数据库操作的性能和效率。
要配置 Sequelize 的连接池,可以在实例化 Sequelize 对象时传入一个名为 pool 的选项。下面是一个示例:
const { Sequelize } = require('sequelize');
const sequelize = new Sequelize('db_test', 'root', '123456', {
host: '127.0.0.1',
dialect: 'mysql',
pool: {
max: 10, // 最大连接数
min: 0, // 最小空闲连接数
acquire: 30000, // 获取连接的超时时间(毫秒)
idle: 10000 // 连接闲置的超时时间(毫秒)
}
});
在上面的示例中,我们在 Sequelize 的配置对象中添加了 pool 选项。其中包含了以下几个参数:
- max:连接池中允许的最大连接数。
- min:连接池中保持的最小空闲连接数。
- acquire:获取连接的超时时间,如果超过该时间仍未获取到连接,将抛出错误。
- idle:连接闲置的超时时间,超过该时间,连接将被释放。
通过配置连接池,Sequelize 将自动管理连接的获取和释放,使得应用程序能够高效地使用数据库连接。在每次执行查询时,Sequelize 将从连接池中获取一个空闲连接,并在查询完成后将连接返回给连接池以供重用。
需要注意的是,连接池的配置参数应根据实际情况进行调整,以满足应用程序的需求。合理设置最大连接数和空闲连接数可以避免连接过多或过少的问题,从而提高数据库操作的性能和可靠性。
26.1.4 Sequelize的方法
Sequelize 提供了丰富的方法和功能,用于在 Node.js 中进行数据库的增删改查操作。下面是详细介绍 Sequelize 的一些常用方法:
-
模型定义方法:
- sequelize.define(modelName, attributes, options):用于定义一个新的数据模型。
- Model.hasOne、Model.belongsTo、Model.hasMany、Model.belongsToMany:用于定义模型间的关联关系。
-
数据库同步方法:
- sequelize.sync(options):根据模型定义自动创建或更新数据库中的表结构。
-
查询方法:
- Model.findAll(options):查询满足条件的多个记录。
- Model.findOne(options):查询满足条件的单个记录。
- Model.findByPk(id, options):根据主键查询单个记录。
- Model.findOrCreate(options):查询满足条件的记录,如果不存在则创建新记录。
- Model.count(options):计算满足条件的记录数量。
-
创建记录方法:
- Model.create(values, options):创建一条新的记录。
- Model.bulkCreate(records, options):批量创建多条记录。
-
更新记录方法:
- instance.save(options):保存已存在的记录到数据库。
- Model.update(values, options):根据条件更新符合条件的记录。
-
删除记录方法:
- instance.destroy(options):从数据库中删除已存在的记录。
- Model.destroy(options):根据条件删除符合条件的记录。
-
事务处理方法:
- sequelize.transaction(options, autoCallback):用于执行具有事务性质的操作。
-
原生 SQL 查询方法:
- sequelize.query(rawQuery, options):允许你执行原生的 SQL 查询语句。
以上是一些常用的 Sequelize 方法,当然 Sequelize 还提供了更多的方法和功能,如聚合函数、数据验证、范围查询等。可以根据具体的需求来选择合适的方法来执行数据库操作。
26.1.5 定义数据模型
在 Sequelize 中,你需要定义模型来映射数据库表格。每个模型都对应一个数据库表格,并定义了表格的字段和关联关系。例如,定义一个 User 模型:
const { DataTypes } = require('sequelize');
const sequelize = new Sequelize('db_test', 'root', '123456', {
host: '127.0.0.1',
dialect: 'mysql' // 或者 'postgres'、'sqlite'、'mssql' 等
});
const User = sequelize.define('User', {
id: {
type: DataTypes.INTEGER,
primaryKey: true,
autoIncrement: true
},
name: {
type: DataTypes.STRING,
allowNull: false
},
age: {
type: DataTypes.INTEGER,
allowNull: false,
},
balance: {
type: DataTypes.DECIMAL(10, 2),
allowNull: false,
}
});
如果数据模型是一个 JavaScript 类,可以通过继承 Sequelize 提供的 Model 类来定义。在模型中,你需要指定表名、字段以及它们的类型和约束等。
const { Model, DataTypes } = require('sequelize');
class User extends Model {}
User.init({
// 字段定义
name: {
type: DataTypes.STRING,
allowNull: false
},
age: {
type: DataTypes.INTEGER,
allowNull: false
},
balance: {
type: DataTypes.DECIMAL(10, 2),
allowNull: false,
}
}, {
sequelize,
modelName: 'user'
});
// 可以在模型中定义关联关系、实例方法和类方法等
module.exports = User;
面的代码中,我们使用 sequelize.define() 方法创建了一个名为 User 的模型,并使用对象参数来定义模型的字段和字段类型。其中,每个字段都是该对象的一个属性,属性名为字段名,属性值为字段的类型和约束条件。例如,id 字段的属性如下:
id: {
type: DataTypes.INTEGER,
allowNull: false,
primaryKey: true,
autoIncrement: true
}
- type:字段类型,可以是字符串、数字、日期等;
- allowNull:是否允许为空,默认为 true;
- primaryKey:是否为主键,默认为 false;
- autoIncrement:是否自增,默认为 false。
除了定义字段之外,我们还可以在第二个参数中定义其他模型配置,例如表名、时间戳、字段命名规则等。例如,tableName 属性用于指定模型对应的数据库表名:
{
tableName: 't_user',
timestamps: true
}
在上面的示例代码中,我们将模型名设置为 User,所有字段都具有通用约束条件并在 Sequelize 中有对应的数据类型,表名设置为 t_user,启用了时间戳功能。
字段的定义方式
Sequelize 支持多种数据类型,以下是一些常用的数据类型及其定义方式:
- 字符串类型:DataTypes.STRING(length),其中 length 指定字符串长度;
- 文本字符串:DataTypes.TEXT // TEXT,DataTypes.TEXT(“tiny”) // TINYTEXT;
- 整数类型:DataTypes.INTEGER,DataTypes.BIGINT,DataTypes.BIGINT(11);
- 浮点数类型:DataTypes.FLOAT;
- 双精度浮点数类型:DataTypes.DOUBLE;
- 精确数值类型:DataTypes.DECIMAL,DataTypes.DECIMAL(10, 2);
- 布尔类型:DataTypes.BOOLEAN;
- 日期类型:DataTypes.DATE;
- 时间戳类型:DataTypes.TIMESTAMP;
- JSON 类型:DataTypes.JSON;
- uuid:DataTypes.UUID
- 数组类型:DataTypes.ARRAY(DataType),其中 DataType 指定数组元素的类型。
在定义字段时,我们还可以给字段增加一些约束条件,以确保数据的完整性和唯一性。以下是一些常用的约束条件及其定义方式:
- 允许为空:allowNull: true/false;指定字段是否允许为空。
- 是否为主键:primaryKey: true/false;指定字段是否为主键。
- 是否自增:autoIncrement: true/false;指定字段是否为自增字段。
- 是否唯一:unique: true/false;指定字段的值是否唯一。
- 默认值:defaultValue: value,其中 value 为默认值。
- 外键:foreignKey: 字符串、对象或函数;用于定义关系模型之间的外键关系。
- 注释:comment: 用于为模型字段添加注释的属性选项。
- 模型关联:references: 在定义模型字段时使用,用于指定当前字段与另一个模型的关联关系。它接受两个参数:目标模型和目标字段。
通过以上介绍,我们可以灵活地使用 Sequelize 定义数据模型,并对模型的字段进行约束和限制,以确保数据的完整性和正确性。
数据模型对应着关系型数据库中的一张数据表。下面是 Sequelize 定义模型以及操作的步骤:
-
导入模块
const { Sequelize, DataTypes } = require('sequelize'); -
创建 Sequelize 实例
创建一个 Sequelize 实例,这个实例用于连接数据库。在创建实例时,需要传入数据库的名称、用户名和密码等连接信息,以及数据库类型和主机地址等配置信息。
const sequelize = new Sequelize('database', 'username', 'password', { host: 'localhost', dialect: 'mysql' }); -
定义模型
假如使用
sequelize.define()方法定义一个模型,该方法接收两个参数:模型名称和字段定义对象。在字段定义对象中,需要指定每个字段的名称、类型和属性等信息。const User = sequelize.define('User', { // 字段定义 id: { type: DataTypes.INTEGER, primaryKey: true, autoIncrement: true }, name: { type: DataTypes.STRING, allowNull: false }, }); -
定义关联
如果有多个模型之间存在关联关系,需要在模型定义之后,再定义关联关系。Sequelize 支持一对一、一对多和多对多三种关联关系,分别可以通过
hasOne()、hasMany()和belongsToMany()方法实现。User.hasMany(Article); Article.belongsTo(User); -
同步模型与数据库
定义完模型之后,需要将模型同步到数据库中。可以使用
sequelize.sync()方法同步所有模型与数据库的结构。该方法返回一个Promise,调用方可以通过await等待同步完成后再执行下一步操作。await sequelize.sync(); -
进行 CRUD 操作
最后,可以使用 Sequelize 提供的各种方法进行数据读写操作。例如,可以使用
User.create()方法在数据库中创建一个新用户,并返回该用户的实例对象。也可以使用User.findAll()查询数据库中所有用户的信息。const user = await User.create({ name: 'Tom', age: 18 });
上述就是使用 Sequelize 定义模型的一般流程。在实际开发中,还需要根据业务需求定义不同的模型和关联关系,并使用 Sequelize 提供的各种方法进行数据读写操作。
一旦定义了模型,你就可以使用它来执行数据库操作,如插入、查询、更新和删除数据。以下是一些常见的操作示例:
26.1.6 插入数据
Sequelize 提供了多种方法来插入数据到数据库中。以下是 Sequelize 中常用的几种插入数据的方法及其详细介绍:
Model.create(options)
向数据库中插入一条新记录。它会创建一个新的实例对象并将其保存到数据库中。
示例:
const user = await User.create({ name: 'Alice', email: 'alice@example.com' });
console.log(user.toJSON());
Model.bulkCreate(list)
批量向数据库中插入多条记录。它可以一次性插入多个记录,适合批量导入数据的场景。
示例:
const users = [
{ name: 'Alice', age: 25, balance: 5000 },
{ name: 'Bob', age: 30, balance: 500 },
{ name: 'Carol', age: 28, balance: 1000 }
];
await User.bulkCreate(users);
Model.create() 也可以接受一个数组插入多条数据;由于 Model.bulkCreate() 是一次性插入多条记录,而Model.create() 是逐条插入多条记录,因此在插入大量数据时,相对于多次调用 Model.create() 更高效。
26.1.7 查询数据
当使用 Sequelize 进行数据库查询时,提供了多种方法来满足不同的需求。以下是一些常用的 Sequelize 查询方法及其介绍:
Model.findAll(options)
查询满足条件的多个记录。
-
options:一个包含查询选项的对象,可以包括
where、order、limit、offset等。 -
返回值:一个
Promise,解析为满足条件的记录数组。
示例:
//const users = await User.findAll();
const users = await User.findAll({
where: {
age: { [Op.gte]: 18 } // 年龄大于等于 18
},
order: [
['name', 'ASC'] // 按名称升序排序
],
limit: 10, // 限制最多返回 10 条记录
offset: 0 // 偏移量,从第一条记录开始
});
users.forEach(user => console.log(user.toJSON()));
请注意,findAll 方法将返回所有的 User 记录,如果数据库中的记录非常多,这可能会导致性能问题。因此,在实际应用中,你可能需要使用分页或其他限制条件来查询用户记录。
Model.findOne(options)
查询满足条件的单个记录。
- options:一个包含查询选项的对象,可以包括
where、order等。 - 返回值:一个
Promise,解析为满足条件的第一条记录。
示例:
const user = await User.findOne({
where: {
id: 1 // 根据 ID 查询用户
}
});
console.log(user.toJSON());
在上面的示例中,我们定义了一个 User 模型,并使用 findOne 方法查询 id 为 1 的用户。where 参数指定查询条件,这里我们使用了简单的相等条件。如果查询成功,将返回符合条件的第一条记录;否则,返回 null。
Model.findByPk(id, options)
根据主键查询单个记录。
- id:要查询的主键值。
- options:一个包含查询选项的对象,可以包括
attributes、include等。 - 返回值:一个
Promise,解析为满足条件的记录。
示例:
const user = await User.findByPk(1, {
attributes: ['name', 'email'] // 只返回指定的属性
});
console.log(user.toJSON());
在上面的示例中,我们使用 findByPk 方法查询 id 为 1 的用户。findByPk 方法接受一个主键参数,返回与该主键对应的记录。如果查询成功,将返回符合条件的记录;否则,返回 null。
Model.findOrCreate(options)
查询满足条件的记录,如果不存在则创建新记录。
- options:一个包含查询选项的对象,可以包括
where、defaults等。 - 返回值:一个
Promise,解析为一个数组[record, created],其中record是满足条件的记录,created是一个布尔值,表示记录是否是新创建的。
示例:
const [user, created] = await User.findOrCreate({
where: {
email: 'test@example.com' // 根据邮箱查询用户
},
defaults: {
name: 'Test User' // 如果用户不存在,则创建一个新用户
}
});
console.log(user.toJSON());
console.log(created); // true 表示记录是新创建的,false 表示记录已存在
Model.count(options)
计算满足条件的记录数量。
- options:一个包含查询选项的对象,可以包括
where等。 - 返回值:一个
Promise,解析为满足条件的记录数量。
示例:
const count = await User.count({
where: {
city: 'Beijing' // 城市为北京
}
});
console.log(count);
min, max, sum
在 Sequelize 中,除了 max 方法,还有 min 和 sum 方法可以用于查询某个列的最小值和总和。这些方法通常用于统计和分析数据。
下面是这三个方法的示例用法:
-
min 方法
const minAge = await User.min('age');上述示例中,我们通过调用
min方法查询用户表中年龄列的最小值。 -
max 方法
const maxSalary = await User.max('salary');上述示例中,我们通过调用
max方法查询用户表中薪水列的最大值。 -
sum 方法
const totalSalary = await User.sum('salary');上述示例中,我们通过调用 sum 方法计算用户表中薪水列的总和。
需要注意的是,如果查询结果为空,则这些方法返回 null。
查询方法的options参数:
-
where:用于指定查询条件的对象或字符串。对象格式为
{ field: value },表示查询字段名为field且取值等于value的模型实例;字符串格式为 SQL 查询语句,例如'age > 18'。以下是 Op 对象中常用的运算符:
- Op.eq:等于运算符。
- Op.ne:不等于运算符。
- Op.gt:大于运算符。
- Op.gte:大于等于运算符。
- Op.lt:小于运算符。
- Op.lte:小于等于运算符。
- Op.like:模糊查询运算符,支持通配符 % 和 _。
- Op.notLike:不匹配运算符。
- Op.in:包含运算符,用于查询字段值在指定数组中的模型实例。
- Op.notIn:不包含运算符,用于查询字段值不在指定数组中的模型实例。
- Op.between:区间运算符,用于查询字段值在指定区间范围内的模型实例。
- Op.notBetween:不在区间运算符,用于查询字段值不在指定区间范围内的模型实例。
- Op.and:逻辑与运算符,用于连接多个查询条件。
- Op.or:逻辑或运算符,用于连接多个查询条件。
- Op.not:逻辑非运算符,用于否定一个查询条件。
你可以传递一个对象来指定查询条件,其中对象的属性名表示字段名,属性值表示查询条件。
-
简单条件:你可以使用等于、不等于、大于、小于、大于等于和小于等于等运算符来构建查询条件。例如:
```javascript const { Op } = require('sequelize'); // 查询年龄等于 18 的用户 const users = await User.findAll({ where: { age: 18 } }); // 查询年龄大于等于 18 的用户 const users = await User.findAll({ where: { age: { [Op.gte]: 18 } } }); ``` -
复杂条件:你可以使用逻辑运算符(与、或、非)来构建复杂的查询条件。例如:
const { Op } = require('sequelize'); // 查询年龄大于 18 并且用户名以 'j' 开头的用户 const users = await User.findAll({ where: { age: { [Op.gt]: 18 }, username: { [Op.startsWith]: 'j' } } }); // 查询年龄小于 18 或者用户名以 'a' 结尾的用户 const users = await User.findAll({ where: { [Op.or]: [ { age: { [Op.lt]: 18 } }, { username: { [Op.endsWith]: 'a' } } ] } }); // 查询年龄在 18 到 30 之间的用户 const users = await User.findAll({ where: { age: { [Op.between]: [18, 30] } } }); // 模糊匹配 const users = await User.findAll({ where: { [Op.or]: [ { username: { [Op.like]: 'a' } } ] } }); -
字符串形式的 where 参数:
// 使用字符串形式的 where 参数进行查询 const users = await User.findAll({ where: 'age > 18 AND username LIKE "j%"' });
注意事项:
1.在使用对象形式的where参数时,可以通过引入Op对象来使用各种运算符。例如{ [Op.gt]: 18 }表示大于运算符。
2.在使用字符串形式的where参数时,需要注意 SQL 注入的安全问题。应该避免直接将用户输入的数据拼接到查询条件中,而是使用参数绑定或 Sequelize 提供的安全方法来处理查询条件。
-
attributes:用于指定返回结果包含的字段名数组。默认情况下,返回所有字段。
attributes 选项可以有多种不同的用法:-
字符串数组:你可以传递一个字符串数组,指定要返回的字段名。
const users = await User.findAll({ attributes: ['id', 'name'] });上述示例将只返回
id和name两个字段的值。 -
对象字面量:你可以传递一个对象字面量来进一步控制字段的返回。
const users = await User.findAll({ attributes: { include: ['name'], exclude: ['createdAt', 'updatedAt'] } });上述示例中,
include数组指定要返回的字段,exclude数组指定要排除的字段。这样,查询结果中将只包含name字段,且不包含createdAt和updatedAt字段。 -
使用聚合函数:你可以使用 Sequelize 提供的聚合函数,如
sequelize.fn、sequelize.col等,并将它们作为属性值传递给attributes选项const users = await User.findAll({ attributes: [ 'id', 'name', [sequelize.fn('COUNT', sequelize.col('orders')), 'orderCount'] ], include: [Order] });上述示例中,我们使用
sequelize.fn和sequelize.col创建了一个计数聚合函数,并将其命名为orderCount。查询结果中将包含id、name和orderCount字段,同时还使用include选项包含了关联模型Order。
-
-
include:用于指定关联模型的查询条件和返回结果。可以是单个关联对象或关联对象数组。关联对象中常用的属性包括:
- model:用于指定关联模型的名称或模型对象。
- where:用于指定关联模型的查询条件。
- as:用于指定关联模型在当前模型中的别名。
- attributes:用于指定返回结果包含的关联模型字段名数组。
以下是 include 的详细介绍:
-
基本用法
在查询某个模型时,可以使用
include选项来一并查询与该模型相关联的其他模型。例如,如果你有两个模型User和Order,并且它们之间建立了一对多的关联关系,那么你可以这样查询一个用户及其所有订单:const user = await User.findOne({ where: { id: userId }, include: Order });在这个例子中,我们通过
include选项指定了要查询的关联模型Order,Sequelize将自动根据模型之间的关联关系生成JOIN查询语句,从而实现一次性查询出用户及其所有订单的数据。 -
指定关联模型的字段
在进行关联查询时,默认情况下会查询关联模型的所有字段。但是,在实际应用中,我们可能只需要查询部分字段的值。此时,可以通过
attributes选项来指定要查询的字段,例如:const user = await User.findOne({ where: { id: userId }, include: { model: Order, attributes: ['id', 'totalAmount'] } });在这个例子中,我们通过
attributes选项指定了要查询的字段id和totalAmount,Sequelize 将只返回这两个字段的值。 -
指定关联模型的排序规则
在进行关联查询时,有时候需要按照一定的规则对关联模型的数据进行排序。此时,可以通过 order 选项来指定排序规则,例如:
const user = await User.findOne({ where: { id: userId }, include: { model: Order, order: [['createdAt', 'DESC']] } });在这个例子中,我们通过 order 选项指定了要按照创建时间降序排列订单数据,Sequelize 将返回按照该规则排序后的订单数据。
-
多级关联查询
在实际应用中,有时候需要进行多级关联查询,即查询一个模型及其关联模型的关联模型等。此时,可以在
include选项中嵌套指定关联模型,例如:const user = await User.findOne({ where: { id: userId }, include: { model: Order, include: { model: Product, through: { attributes: [] } } } });在这个例子中,我们通过在
include中嵌套指定关联模型Product,从而实现了多级关联查询。关联模型之间的关系可以通过through选项来指定。-
多个关联模型
你可以使用数组形式在
include选项中包含多个关联模型。这样可以同时查询多个关联模型的数据。const user = await User.findOne({ where: { id: userId }, include: [ { model: Order }, { model: Product }, { model: Address } ] }); console.log(user.order); console.log(user.address);在这个示例中,我们通过数组形式在
include中指定了三个关联模型:Order、Product和Address。Sequelize 将根据模型之间的关联关系生成相应的JOIN查询语句,从而一次性查询出用户及其所有订单、产品和地址的数据。 -
嵌套方式包含多个关联模型
你可以使用嵌套方式在
include选项中包含多个关联模型,这样可以实现更复杂的数据查询和操作。const user = await User.findOne({ where: { id: userId }, include: [ { model: Order, include: [ { model: Product }, { model: Address } ] } ] });在这个示例中,我们使用嵌套方式在
include中指定了一个关联模型Order,并在该关联模型的对象中继续使用include选项指定了两个关联模型:Product和Address。Sequelize 将根据模型之间的关联关系生成相应的 JOIN 查询语句,从而一次性查询出用户及其所有订单、订单中的所有产品和地址的数据。需要注意的是,每个关联模型都需要使用一个对象来进行描述,对象中至少需要包含
model属性来指定要查询的关联模型。你还可以在每个关联模型的对象中使用其他选项,如attributes、where、order等,以更精确地控制查询条件和结果。
-
-
limit:用于指定返回结果的最大数量。
-
offset:用于指定返回结果的起始位置。
-
order:用于指定返回结果的排序方式,可以是单个排序对象或排序对象数组。排序对象中常用的属性包括:
- field:用于指定排序的字段名。
- order:用于指定排序的方式,可以是 ‘ASC’ 或 ‘DESC’。
order 参数可以有多种不同的用法:
-
字符串:你可以传递一个字符串,指定要排序的字段名。
const users = await User.findAll({ order: 'name ASC' });上述示例将按照
name字段进行升序排序。 -
数组:你可以传递一个数组,指定多个排序规则。每个排序规则都是一个由字段名和排序方式组成的子数组。
const users = await User.findAll({ order: [['name', 'ASC'], ['createdAt', 'DESC']] });上述示例中,我们根据
name字段进行升序排序,如果name字段相同,则按照createdAt字段进行降序排序。 -
对象字面量:你可以传递一个对象字面量,更精确地控制排序规则。对象的键是字段名,值是排序方式(ASC 或 DESC)。
const users = await User.findAll({ order: { name: 'ASC', createdAt: 'DESC' } });上述示例中,我们使用对象字面量来指定排序规则,按照
name字段进行升序排序,按照createdAt字段进行降序排序。 -
排序关联模型的字段:
const users = await User.findAll({ include: [Post], order: [[Post, 'createdAt', 'DESC']] });上述示例中,我们使用
include选项将关联模型Post包含在查询中,并使用order选项对关联模型的createdAt字段进行降序排序。 -
排序多个关联模型的字段:
const users = await User.findAll({ include: [ { model: Post, as: 'posts' }, { model: Post, as: 'likedPosts' } ], order: [ [{ model: Post, as: 'posts' }, 'createdAt', 'DESC'], [{ model: Post, as: 'likedPosts' }, 'createdAt', 'DESC'] ] });上述示例中,我们使用
include选项分别包含了两个关联模型Post,并使用order选项对每个关联模型的createdAt字段进行降序排序。
-
group:用于指定查询结果按照字段进行分组。可以是单个分组字段名或分组字段名数组。
-
having:用于指定分组后的筛选条件,可以是字符串或对象格式。
-
distinct:用于指定查询结果是否去重。
-
transaction:用于在事务中进行查询操作。
-
lock:用于指定查询时使用的锁类型,例如
'SHARE'或'UPDATE'。
聚合函数
在 Sequelize 中,你可以使用聚合函数对查询结果进行统计和计算。Sequelize 提供了一组内置的聚合函数,可以在查询中使用。
下面是一些常用的 Sequelize 聚合函数及其示例用法:
-
sequelize.fn(functionName, args):调用内置的 SQL 聚合函数或自定义函数。可以传递函数名和参数数组。
const result = await User.findOne({ attributes: [ [sequelize.fn('COUNT', sequelize.col('id')), 'totalUsers'], [sequelize.fn('SUM', sequelize.col('age')), 'totalAge'], [sequelize.fn('AVG', sequelize.col('salary')), 'averageSalary'], ] });上述示例中,我们使用
COUNT函数统计用户表中的记录数,使用SUM函数计算年龄总和,使用AVG函数计算薪水平均值。 -
sequelize.literal(expression):直接传递 SQL 表达式作为聚合函数。
const result = await User.findOne({ attributes: [ [sequelize.literal('MAX(age)'), 'maxAge'], [sequelize.literal('MIN(salary)'), 'minSalary'], ] });上述示例中,我们使用
MAX函数获取最大年龄,使用MIN函数获取最低薪水。 -
sequelize.col(columnName):引用查询中的列名。
const result = await User.findOne({ attributes: [ [sequelize.col('name'), 'userName'], [sequelize.fn('COUNT', sequelize.col('id')), 'totalUsers'], ] });上述示例中,我们使用
col方法引用name列并将其命名为userName。
通过使用 Sequelize 的聚合函数,你可以在查询中进行各种统计和计算操作。这些函数提供了灵活的方式来处理查询结果,并生成所需的聚合结果。具体的函数列表和用法可以参考 Sequelize 的官方文档。
26.1.8 更新数据
在 Sequelize 中,更新数据的方法主要有两种:使用 save 方法和使用 update 方法。
Model.save()
更新已存在的记录到数据库中。在更新前,你需要先查询到要更新的记录,并且对其进行修改后再调用 save 方法保存。
示例:
const user = await User.findByPk(1); // 查询 ID 为 1 的用户记录
user.name = 'Bob'; // 修改用户的名字
await user.save(); // 保存修改后的记录
Model.update(options)
根据条件更新符合条件的记录。它是一种批量更新的方法,可以同时更新多条记录。
示例:
await User.update({ age: 30 }, {
where: {
name: '老王'
}
});
26.1.9 删除数据
Sequelize 提供了多种方法来删除数据库中的数据。以下是 Sequelize 中常用的几种删除数据的方法及其详细介绍:
Model.destroy()
从数据库中删除一条或多条记录。
示例:
const user = await User.findByPk(1);
await user.destroy();
Model.truncate()
从数据库中清空一张表中所有记录。
示例:
await User.truncate();
Model.drop()
从数据库中删除一张表以及其所有相关的约束。
await User.drop();
26.1.10 sequelize.query
sequelize.query() 是 Sequelize 提供的一个方法,用于执行自定义的 SQL 查询语句。它可以执行各种类型的查询,包括 SELECT、INSERT、UPDATE 和 DELETE 等。
使用 sequelize.query() 方法需要传入两个参数:查询语句和一些额外的选项。下面是方法的基本语法:
sequelize.query(query, options)
.then((result) => {
// 处理查询结果
})
.catch((error) => {
// 处理错误
});
参数说明:
- query:要执行的 SQL 查询语句,可以是纯粹的 SQL 字符串或包含占位符的预处理语句。
- options:可选参数,用于指定查询的类型、替换参数、返回结果等。
以下是一些常用的选项:
- type:指定查询类型,例如
QueryTypes.SELECT(默认)、QueryTypes.INSERT、QueryTypes.UPDATE和QueryTypes.DELETE。 - replacements:用于预处理语句中的参数替换,可以是对象或数组形式的键值对。
- model:指定查询结果要映射到的模型。如果提供了该选项,查询结果将根据模型定义进行实例化。
- mapToModel:设置为
true时,查询结果将始终映射到给定的模型,即使返回的结果是纯粹的 JavaScript 对象。
下面是一个使用 sequelize.query() 方法的示例:
const { QueryTypes } = require('sequelize');
// 1.查询所有用户
sequelize.query('SELECT * FROM users WHERE name = :name', {
type: QueryTypes.SELECT,
replacements: { name: 'John' }
})
.then((users) => {
console.log(users);
})
.catch((error) => {
console.error(error);
});
// 2.查询用户名为 "John" 的用户
sequelize.query('SELECT * FROM t_user WHERE name = :name', {
type: QueryTypes.SELECT,
replacements: { name: 'John' }
})
.then((users) => {
console.log(users);
})
.catch((error) => {
console.error(error);
});
// 3.查询用户数量
sequelize.query('SELECT COUNT(*) AS count FROM t_user', { type: QueryTypes.SELECT })
.then((result) => {
const count = result[0].count;
console.log(count);
})
.catch((error) => {
console.error(error);
});
在上面的示例中,我们使用 :name 占位符来动态传递参数,通过 replacements 选项传入参数值。查询结果将以数组形式返回。
请注意,使用 sequelize.query() 方法进行查询时,需要手动编写 SQL 查询语句,并且需要对输入参数做必要的验证和转义,以避免 SQL 注入等安全问题。同时,不建议在生产环境中频繁使用 sequelize.query() 方法,因为它可能会影响应用程序的性能和可维护性。
26.1.11 事务处理
Sequelize 中的事务处理功能允许开发者在进行一系列数据库操作时保持数据的一致性和完整性。Sequelize 提供了 transaction 方法来创建一个新的事务,还提供了 commit 和 rollback 方法来提交或回滚一个事务。
示例:
try {
const transaction = await sequelize.transaction(); // 创建一个事务
// 转账方
const transferor = await User.findByPk(1); // 查询 ID 为 1 的用户记录
transferor.balance -= 100;
transferor.save();
// 收款方
const payee = await User.findByPk(1); // 查询 ID 为 1 的用户记录
payee.balance -= 100;
payee.save();
await transaction.commit(); // 提交事物
} catch (error) {
console.log(error);
await transaction.rollback(); // 回滚事物
}
以上代码使用两个用户模拟了转账和收款,如果转账成功就提交事物,如果发生错误就回滚事物。
26.1.11 sequelize实现多表关联
在 Sequelize 中,你可以使用模型关联来建立表之间的关系,例如一对一、一对多和多对多关系。这些关系可以通过定义外键和关联关系来实现。下面是一些示例用法:
一对一
使用 belongsTo 和 hasOne 关联类型可以在两个模型之间建立一对一的关系。例如,如果你有两个模型 User 和 Profile,可以通过以下代码建立关联:
// User 模型定义
const User = sequelize.define('User', {
// 字段定义
id: {
type: DataTypes.INTEGER,
primaryKey: true,
autoIncrement: true
},
name: {
type: DataTypes.STRING,
allowNull: false
},
age: {
type: DataTypes.INTEGER,
allowNull: false,
},
});
// Profile 模型定义
const Profile = sequelize.define('Profile', {
// 字段定义
id: {
type: DataTypes.INTEGER,
primaryKey: true,
autoIncrement: true
},
birthday: {
type: DataTypes.DATE,
allowNull: false
},
userId: {
type: DataTypes.INTEGER,
allowNull: false,
references: {
model: User,
key: 'id'
}
}
});
// 建立关联
User.hasOne(Profile, { foreignKey: 'userId', as: "profile"});
Profile.belongsTo(User, { foreignKey: 'userId'});
await sequelize.sync();
上述代码使用 User.hasOne() 和 Profile.belongsTo() 建立了 User 和 Profile 之间的一对一关系。hasOne() 表示 User 模型拥有一个 Profile 模型的关联,belongsTo() 表示 Profile 模型属于一个 User 模型的关联。通过 foreignKey 参数指定了外键字段名为 userId,并使用 as 参数分别指定了关联的别名为 "profile"。
接下来,可以通过 User 和 Profile 模型进行查询和创建操作,例如:
// 建立关联
User.hasOne(Profile, { foreignKey: 'userId', as: "profile"});
Profile.belongsTo(User, { foreignKey: 'userId'});
await sequelize.sync();
// 创建用户和个人资料
const user = await User.create({ name: 'Tom', age: 18 });
const profile = await Profile.create({ birthday: new Date('1990-01-12'), userId: user.id });
await user.setProfile(profile); // 关联用户和个人资料
// 查询
const userProfile = await User.findOne({ include: [{ model: Profile, as: 'profile' }], where: { name: "Tom" } });
console.log(userProfile);
await sequelize.close();
上述代码分别创建了一个 User 和一个 Profile 对象,最后,通过 User.findOne() 方法查询名为 "Tom" 的用户,并通过 include 选项指定关联的模型为 Profile,使用 as 参数指定关联的别名为 "profile"。这样会在查询结果中包含用户的个人资料信息。
一对多
使用 hasMany 和 belongsTo 关联类型可以在两个模型之间建立一对多的关系。例如,如果你有两个模型 User 和 Article,一个用户可以拥有多篇文章,可以通过以下代码建立关联:
// User 模型定义
const User = sequelize.define('User', {
// 字段定义
id: {
type: DataTypes.INTEGER,
primaryKey: true,
autoIncrement: true
},
name: {
type: DataTypes.STRING,
allowNull: false
},
age: {
type: DataTypes.INTEGER,
allowNull: false,
},
});
// Article 模型定义
const Article = sequelize.define('Artile', {
// 字段定义
id: {
type: DataTypes.INTEGER,
primaryKey: true,
autoIncrement: true
},
title: {
type: DataTypes.STRING,
allowNull: false
},
content: {
type: DataTypes.STRING,
allowNull: false,
},
userId: {
type: DataTypes.INTEGER,
allowNull: false,
references: {
model: User,
key: 'id'
}
}
});
// 建立关联
User.hasMany(Article, { foreignKey: 'userId', as: 'articles'});
Article.belongsTo(User, { foreignKey: 'userId' });
await sequelize.sync();
上述代码在两个模型定义后,通过 User.hasMany() 和 Article.belongsTo() 方法定义了 User 和 Article 之间的一对多关系。其中,foreignKey 参数指定了外键的名称,as 参数指定了关系的别名。
接下来,通过 User 和 Article 模型进行查询和创建操作,例如:
const user = await User.create({ name: 'Tom', age: 18 });
const article1 = await Article.create({
title: 'Git安装', content: 'Git 是一个开源的分布式版本控制系统,可以用来管理和跟踪软件开发过程中的代码变化。Git不仅仅是一个版本控制系统,它还提供了许多工具和命令行选项,可以帮助开发人员在团队合作中更好地管理代码库。例如,开发人员可以使用Git的"合并请求"功能,在代码库中提出更改并请求其他开发人员进行审核和合并。本文将介绍如何在Windows操作系统上怎样安装Git。', userId: user.id
});
const article2 = await await Article.create({
title: '轻松掌握ES6中...运算符的使用方法', content: '日常开发中,我们经常会用到...运算符,它是在ES6中引入的,其作用是将一个可迭代对象(例如数组、对象等)展开成一个单独的元素。下面是...运算符的具体含义及使用方法记录。', userId: user.id
});
await user.addArticles([article1, article2]);
const userArticles = await User.findOne({ include: [{ model: Article, as: 'articles' }], where: { name: "Tom" } });
console.log(userArticles);
这段代码是在创建用户和文章,并建立它们之间的关联,最后查询用户的所有文章信息。
多对多
使用 belongsToMany 关联类型可以在两个模型之间建立多对多的关系。例如,如果你有两个模型 User 和 Group,一个用户可以加入多个群组,一个群组也可以有多个用户,可以通过以下代码建立关联:
const User = sequelize.define('User', {
id: {
type: DataTypes.INTEGER,
autoIncrement: true,
primaryKey: true
},
name: {
type: DataTypes.STRING,
allowNull: false
},
age: {
type: DataTypes.INTEGER,
allowNull: false
},
});
const Group = sequelize.define('Group', {
id: {
type: DataTypes.INTEGER,
autoIncrement: true,
primaryKey: true
},
name: {
type: DataTypes.STRING,
allowNull: false
}
});
const UserGroup = sequelize.define('UserGroup', {
id: {
type: DataTypes.INTEGER,
autoIncrement: true,
primaryKey: true
},
userId: {
type: DataTypes.INTEGER,
allowNull: false,
references: {
model: User,
key: 'id'
}
},
groupId: {
type: DataTypes.INTEGER,
allowNull: false,
references: {
model: Group,
key: 'id'
}
}
});
// 建立关联
User.belongsToMany(Group, { through: UserGroup, foreignKey: 'userId', as: 'groups' });
Group.belongsToMany(User, { through: UserGroup, foreignKey: 'groupId', as: 'users' });
await sequelize.sync();
上述代码实现了多对多的关联关系,并且通过中间表 UserGroup 来连接 User 表和 Group 表。其中,通过 belongsToMany 方法定义了多对多的关联关系,并使用 through 参数指定了中间表 UserGroup,使用 foreignKey 参数来指定该关联关系在中间表中的外键名,使用 as 参数来指定关联的模型别名。
接下来,通过 User 和 Group 模型进行查询和创建操作,例如:
// 创建关联数据
const [user1, created1] = await User.findOrCreate({ where: { name: 'Tom', age: 18 } });
const [user2, created2] = await User.findOrCreate({ where: { name: 'John', age: 20 } });
const [group1, created3] = await Group.findOrCreate({ where: { name: 'Group 1' } });
const [group2, created4] = await Group.findOrCreate({ where: { name: 'Group 2' } });
if (created1 || created2 || created3 || created4) {
await UserGroup.create({ userId: user1.id, groupId: group1.id });
await UserGroup.create({ userId: user1.id, groupId: group2.id });
await UserGroup.create({ userId: user2.id, groupId: group1.id });
await UserGroup.create({ userId: user2.id, groupId: group2.id });
} else {
console.log('关联数据已存在');
}
// 查询关联数据
const user = await User.findOne({ where: { name: 'John' }, include: [{ model: Group, as: 'groups' }] });
console.log(user.groups); // 输出与该用户关联的项目列表
// 查询关联数据
const group = await Group.findOne({ where: { name: 'Group 1' }, include: [{ model: User, as: 'users' }] });
console.log(group.users); // 输出与该用户关联的项目列表
// 关闭连接
await sequelize.close();
在示例代码中,首先创建了两个用户和两个用户组,并将它们通过中间表 UserGroup 进行关联。然后,通过查询用户和用户组时,使用 include 参数来指定需要关联的模型。这样,在查询结果中,可以获取到与该用户或用户组关联的数据列表。
注意:多对多创建、查询等必须要先建立关联才能做进一步操作。
Sequelize 是一个功能强大、易于使用的 ORM 库,适用于不同类型的项目和团队,有助于提高开发效率和代码质量。它提供了丰富的方法和功能,使得在 Node.js 中操作关系型数据库变得更加便捷和灵活。通过使用这些方法,你可以轻松地实现各种数据库操作,并且更好地管理和维护数据库中的数据。有关更多的使用方法还可以查看 官方文档。
26.2 Mongoose
Mongoose 是一个 Node.js 的对象模型工具,它提供了一种与 MongoDB 数据库进行交互的简单而直观的方式。它可以帮助开发者在应用程序中定义数据模型、验证数据以及执行 CRUD 操作等。
以下是 Mongoose 的一些主要特点和功能:
-
数据建模:Mongoose 允许开发者使用Schema(模式)来定义数据模型。Schema是数据的结构和约束的描述,它可以指定字段的类型、默认值、验证规则等。通过Schema的定义,可以更好地组织和管理数据。
-
数据验证:Mongoose 提供了丰富的验证功能,可以在保存数据之前对数据进行验证。开发者可以自定义验证逻辑或使用内置的验证器,如必需字段、唯一性约束、最小/最大值限制等。这有助于确保数据的完整性和一致性。
-
CRUD操作:Mongoose 封装了一套易于使用的API,用于执行CRUD操作(创建、读取、更新和删除)。通过模型(Model)对象,可以使用诸如
create、find、findOne、updateOne、deleteOne等方法来执行相应的操作。这使得对数据库的操作变得简单而直观。 -
中间件支持:Mongoose 支持中间件(Middleware),开发者可以在执行特定操作前后插入自定义的逻辑。例如,在保存数据前进行某些处理,或在删除数据后执行其他操作。中间件可以有效地扩展和定制 Mongoose 的行为。
-
引用和嵌入:Mongoose 支持引用和嵌入两种关系类型。通过引用,可以在多个文档之间建立关联,并使用 populate 方法获取相关数据。通过嵌入,可以将一个文档嵌入到另一个文档中,形成更复杂的数据结构。
-
查询构建器:Mongoose 提供了强大的查询构建器,允许开发者使用链式调用的方式来构建复杂的查询条件。可以进行条件过滤、排序、限制返回字段等操作,以满足不同场景下的查询需求。
-
事件驱动:Mongoose 基于事件驱动的模型,可以监听各种事件(如保存前后、验证前后等),并执行相应的逻辑。这样可以更好地控制数据的操作流程和处理过程。
26.2.1 安装
安装 Mongoose 使用以下命令:
npm install mongoose
26.2.2 连接到 MongoDB 数据库
使用 mongoose.connect() 方法来连接到 MongoDB 数据库。该方法接受 MongoDB URI(Uniform Resource Identifier)作为参数。
const mongoose = require('mongoose');
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
try {
const connct = mongoose.createConnection(uri);
if (!connct) {
console.error('Failed connecting to MongoDB');
return
}
console.log('Connected to MongoDB');
// 在这里可以开始执行数据库操作
} catch (error) {
console.error('Error connecting to MongoDB', error);
}
在这个示例中,我们将 MongoDB URI mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm 传递给 mongoose.createConnection() 方法。
26.2.3 Connection
Mongoose 的 Connection 对象提供了一些方法和属性来管理 MongoDB 数据库的连接和操作。下面我们详细介绍一些常用的 Connection 方法和属性
属性
-
connection.readyState:表示连接状态的属性。
它有以下几个可能的取值:
- 0:未初始化。
- 1:已连接。
- 2:正在连接。
- 3:正在断开连接。
- 4:已断开连接。
你可以使用该属性来检查连接状态,例如在事件处理程序中监视连接状态的变化。
-
connection.host:表示数据库主机名的属性。这通常是在连接字符串中指定的主机名。
-
connection.port:表示数据库端口号的属性。这通常是在连接字符串中指定的端口号。
方法
-
mongoose.createConnection():创建一个新的数据库连接。这个方法可以传入一个 MongoDB 连接字符串以及一些可选的配置选项,返回一个
Connection对象。 -
connection.close():关闭数据库连接。这个方法将断开与数据库的连接并清理相关资源。你可以在不再需要连接时使用该方法。
-
connection.model():创建一个模型。这个方法用于定义和获取与数据库集合关联的模型。它接受两个参数,第一个参数是模型名称,第二个参数是模型的
Schema。 -
connection.collection():获取一个数据库集合。这个方法可以用来直接操作数据库集合,执行原生的 MongoDB 操作。
-
connection.dropDatabase():删除当前数据库。这个方法将删除当前连接的数据库,并且无法恢复。请注意使用时要谨慎。
-
connection.on():监听数据库连接事件。可以通过该方法注册事件处理程序来监听连接状态的变化,如
connected、disconnected、error等。conn.on('connected', () => { console.log('Connected to database'); }); conn.on('disconnected', () => { console.log('Disconnected from database'); }); conn.on('error', error => { console.error('Database error:', error); });
26.2.4 定义数据模型
在 Mongoose 中,数据模型是通过定义模式来实现的。模式定义了文档的属性、类型和验证规则,同时还可以定义中间件、虚拟属性和其他选项。
当使用 Mongoose 定义数据模型时,可以通过定义模式(Schema)来描述文档的结构和属性。Mongoose 提供了丰富的选项和功能,使得操作 MongoDB 数据库更加简单和灵活。
创建数据模型的模式(Schema):模式定义了文档的结构和属性。
const { Schema } = mongoose;
const userSchema = new Schema({
name: {
type: String,
required: true,
trim: true,
},
age: {
type: Number,
min: 18,
max: 120,
},
email: {
type: String,
required: true,
unique: true,
lowercase: true,
trim: true,
match: /^\S+@\S+\.\S+$/,
},
createdAt: {
type: Date,
default: Date.now,
},
});
在这个示例中,我们定义了一个名为 userSchema 的模式对象,并包含了一些属性:
- name 属性的类型是字符串,必须存在且不能为空格。这个属性没有默认值。
- email 属性的类型是字符串,必须存在且唯一。这个属性必须符合电子邮件地址格式,并且在保存到数据库之前会被转换为小写。这个属性没有默认值。
- password 属性的类型是字符串,必须存在且长度至少为 8。
- age 属性的类型是数字,最小值为 18,最大值为 120。这个属性没有默认值。
- createdAt 属性的类型是日期,如果没有提供值,则默认为当前时间。
除了上述属性,还可以在模式中使用其他选项,如设置默认值、添加验证器、定义虚拟属性和中间件等。下面是一些常用选项:
- type:属性的数据类型。支持的数据类型包括字符串、数字、布尔值、日期、数组、对象等。你也可以使用 Mongoose 提供的自定义类型或者第三方插件来扩展支持的数据类型。
- required:属性是否必须存在。默认值为
false。 - default:属性的默认值。如果未提供该属性,则会使用默认值。
- min 和 max:属性的最小值和最大值。适用于数字和日期类型。
- enum:属性可取的枚举值。适用于字符串类型。
- validate:自定义验证函数。你可以编写一个自定义函数来验证属性的值,并返回布尔值。
- unique:属性值是否唯一。如果设置为
true,则会向数据库添加唯一索引。 - trim:移除属性值两端的空格。
- match:验证属性值是否与指定的正则表达式匹配。
- get 和 set:定义属性的
getter和setter函数。 - select:指定查询时是否返回该属性的值。默认情况下,查询时会返回该属性的值。
创建模型对象:使用 connection.model() 方法将模式转换为模型。
const User = connection.model('User', userSchema);
在上述示例中,我们创建了一个名为 User 的模型对象,该模型将操作名为 'User' 的集合(collection)。你可以通过 User 模型执行各种数据库操作,如创建、查询、更新和删除文档等。
26.5.5 创建文档
在 Mongoose 中,可以通过模型的 create() 和 save() 方法来创建新的文档。
- 使用
create()方法创建文档 方法创建文档:
const mongoose = require('mongoose');
const { Schema } = mongoose;
const userSchema = new Schema({
name: {
type: String,
required: true,
trim: true,
},
age: {
type: Number,
min: 18,
max: 120,
},
email: {
type: String,
required: true,
unique: true,
lowercase: true,
trim: true,
match: /^\S+@\S+\.\S+$/,
},
createdAt: {
type: Date,
default: Date.now,
},
});
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
try {
const conn = mongoose.createConnection(uri);
if (!conn) {
console.error('Failed connecting to MongoDB');
return
}
console.log('Connected to MongoDB');
// 在这里可以开始执行数据库操作
// 创建文档
User.create({ name: 'John', email: 'john@example.com', password: 'password123' })
.then(user => {
console.log(user);
})
.catch(error => {
console.error(error);
})
.finally(() => {
// 关闭连接
conn.close();
});
} catch (error) {
console.error('Error connecting to MongoDB', error);
}
在这个示例中,我们使用 User 模型的 create() 方法创建了一个新的文档,并指定了文档的属性。create() 方法返回一个 Promise,如果创建成功,则会返回新创建的文档对象,否则会抛出错误。
- 使用
save()方法创建文档:
const mongoose = require('mongoose');
const { Schema } = mongoose;
const userSchema = new Schema({
name: {
type: String,
required: true,
trim: true,
},
age: {
type: Number,
min: 18,
max: 120,
},
email: {
type: String,
required: true,
unique: true,
lowercase: true,
trim: true,
match: /^\S+@\S+\.\S+$/,
},
createdAt: {
type: Date,
default: Date.now,
},
});
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
try {
const conn = mongoose.createConnection(uri);
if (!cconn) {
console.error('Failed connecting to MongoDB');
return
}
console.log('Connected to MongoDB');
// 在这里可以开始执行数据库操作
const User = conn.model('User', userSchema);
const user = new User({ name: 'John', email: 'john@example.com', password: 'password123' });
// 保存文档
user.save()
.then(user => {
console.log(user);
})
.catch(error => {
console.error(error);
})
.finally(() => {
// 关闭连接
conn.close();
});
} catch (error) {
console.error('Error connecting to MongoDB', error);
}
在这个示例中,我们首先创建了一个 User 对象,并设置了它的属性值。然后,我们使用对象的 save() 方法将该对象保存到数据库中。如果保存成功,则会返回新创建的文档对象,否则会抛出错误。需要注意的是,save() 方法是异步的,需要等待回调或者 Promise 返回后才能确保文档已经被保存到数据库中。
无论是使用 create() 还是 save() 方法,都可以创建新的文档。需要注意的是,对于使用 save() 方法创建的文档,还可以在保存前对文档进行其他修改或操作,如添加虚拟属性、执行验证、设置默认值等。
const User = conn.model('User', userSchema);
const user = new User({ name: 'John', email: 'john@example.com', password: 'password123' });
user.age = 30; // 添加虚拟属性
user.validate(); // 执行验证
user.save()
.then(user => {
console.log(user);
})
.catch(error => {
console.error(error);
})
.finally(() => {
// 关闭连接
connection.close();
});
这个示例中,我们在 User 对象上添加了一个虚拟属性 age,并调用了 validate() 方法执行验证。然后,我们将该对象保存到数据库中。如果保存成功,则返回新创建的文档对象,否则抛出错误。
在 mongoose 中,可以使用模型的 create() 和 save() 方法来创建新的文档,并指定文档的属性。需要注意的是,这两个方法都是异步的,需要等待回调或 Promise 返回后才能确保文档已经被保存到数据库中。
26.5.6 查询文档
在 Mongoose 中,可以使用模型的 find()、findOne() 和 findById() 方法来查询文档。
-
使用 find() 方法查询多个文档:
const User = conn.model('User', userSchema); User.find({ age: { $gte: 18 } }) .then(users => { console.log(users); }) .catch(error => { console.error(error); }) .finally(() => { // 关闭连接 conn.close(); });在这个示例中,我们使用
User模型的find()方法来查询年龄大于等于 18 岁的所有用户文档。find()方法接受一个查询条件对象作为参数,并返回一个Promise,该Promise在查询完成后解析为一个包含匹配文档的数组。 -
使用
findOne()方法查询单个文档:const User = conn.model('User', userSchema); User.findOne({ name: 'John' }) .then(user => { console.log(user); }) .catch(error => { console.error(error); }) .finally(() => { // 关闭连接 conn.close(); });在这个示例中,我们使用
User模型的findOne()方法来查询名为 “John” 的单个用户文档。findOne()方法接受一个查询条件对象作为参数,并返回一个Promise,该Promise在查询完成后解析为匹配的文档。 -
使用
findById()方法根据 ID 查询文档:const User = conn.model('User', userSchema); User.findById('user_id') .then(user => { console.log(user); }) .catch(error => { console.error(error); }) .finally(() => { // 关闭连接 conn.close(); });在这个示例中,我们使用
User模型的findById()方法来查询指定 ID 的用户文档。findById()方法接受一个 ID 字符串作为参数,并返回一个Promise,该Promise在查询完成后解析为匹配的文档。
除了基本的查询方法外,Mongoose 还提供了丰富的查询选项和方法,如排序、限制返回结果的数量、使用聚合管道等。你可以根据具体需求查阅 Mongoose 的官方文档以获得更详细的信息。
const User = conn.model('User', userSchema);
const pageNumber = 1; // 当前页码
const pageSize = 10; // 每页显示的文档数量
User.find()
.sort({ name: 1 }) // 根据 name 字段升序排序
.skip((pageNumber - 1) * pageSize) // 跳过前面的文档数量
.limit(pageSize) // 返回指定数量的文档
.then(users => {
console.log(users);
})
.catch(error => {
console.error(error);
})
.finally(() => {
// 关闭连接
conn.close();
});
在这个示例中,我们使用 User 模型的 find() 方法查询所有用户文档。然后,使用 sort() 方法根据 name 字段进行升序排序。接下来,使用 skip() 方法跳过前面的文档数量,以实现分页的效果。最后,使用 limit() 方法限制返回的文档数量为每页的大小。
你可以根据实际需求修改 pageNumber 和 pageSize 的值,以及 sort() 方法中指定的排序字段和顺序。注意,skip() 方法的参数是跳过的文档数量,而不是页码。
需要注意的是,当数据量很大时,使用 skip() 方法可能会导致性能问题。在这种情况下,可以考虑使用基于游标的分页方法,如使用 find() 方法的 limit() 和 skip() 结合使用,或者使用第三方库来处理分页逻辑,比如 mongoose-paginate。
- 查询条件
Mongoose 提供了丰富的查询条件,用于在 MongoDB 中进行数据查询。以下是一些常用的查询条件:
-
相等条件(Equal):
{ key: value }:匹配指定字段的值等于给定值的文档。例如
{ name: 'John' }将返回所有名为 “John” 的文档。 -
不等条件(Not Equal):
{ key: { $ne: value } }:匹配指定字段的值不等于给定值的文档。例如
{ age: { $ne: 25 } }将返回年龄不等于 25 的文档。 -
大于条件(Greater Than):
{ key: { $gt: value } }:匹配指定字段的值大于给定值的文档。例如
{ age: { $gt: 18 } }将返回年龄大于 18 的文档。 -
大于等于条件(Greater Than or Equal):
{ key: { $gte: value } }:匹配指定字段的值大于等于给定值的文档。例如
{ age: { $gte: 21 } }将返回年龄大于等于 21 的文档。 -
小于条件(Less Than):
{ key: { $lt: value } }:匹配指定字段的值小于给定值的文档。例如
{ age: { $lt: 30 } }将返回年龄小于 30 的文档。 -
小于等于条件(Less Than or Equal):
{ key: { $lte: value } }:匹配指定字段的值小于等于给定值的文档。例如
{ age: { $lte: 40 } }将返回年龄小于等于 40 的文档。 -
存在条件(Exists):
{ key: { $exists: true/false } }:匹配指定字段是否存在或不存在的文档。例如
{ email: { $exists: true } }将返回具有 email 字段的文档。 -
包含(Contain):
{ key: { $in: values } }:匹配数组字段中包含给定值的文档。例如
{ age: { $in: [18, 20] } }将返回年龄为18和20岁的所有用户。 -
不包含(Not Contain)
{ key: { $nin: values } }:匹配数组字段中不包含给定值的文档。例如
{ tags: { $nin: ["movie", "music"] } }将返回一个包含所有tags字段不包含"movie"和"music"的文档的结果集。 -
正则表达式条件(Regular Expression):
{ key: /pattern/ } 或 { key: { $regex: ‘pattern’ } }:匹配指定字段符合正则表达式模式的文档。例如
{ name: /^J/ }将返回以"J"开头的名字的文档。 -
数组条件(Array):
{ key: value }:匹配数组字段中包含给定值的文档。例如
{ tags: 'mongodb' }将返回包含"mongodb"标签的文档。{ key: { $all: [value1, value2] } }:匹配数组字段中同时包含多个给定值的文档。例如
{ tags: { $all: ['mongodb', 'mongoose'] } }将返回同时包含"mongodb"和"mongoose"标签的文档。
除了上述条件,Mongoose 还提供了其他查询条件和操作符,如 $in、$nin、$and、$or、$not 等,以满足更复杂的查询需求。
-
$where
使用
$where可以实现非常灵活和复杂的查询条件,因为它允许你使用 JavaScript 中的逻辑运算符(如 &&、||)和表达式(如 Math.abs())来编写查询条件。但是,由于$where的查询过程相对较慢,且存在安全风险,因此 Mongoose 官方建议在必要的情况下才使用该查询条件。以下是$where的使用示例:-
传入字符串类型的查询条件:
const query = { $where: "this.age > 18 && this.age < 30" }; const result = await User.find(query);上述查询条件将返回年龄在 18 到 30 岁之间的所有用户。
-
传入函数类型的查询条件:
const query = { $where: function() { return Math.abs(this.balance) > 1000; } }; const result = await User.find(query);上述查询条件将返回账户余额绝对值大于 1000 的所有用户。
-
需要注意的是,由于 $where 查询条件中涉及到 JavaScript 代码的执行,因此在编写查询条件时需要特别谨慎,避免出现任何安全漏洞。
26.5.7 修改文档
在 Mongoose 中,可以使用模型的 updateOne()、updateMany() 或 findByIdAndUpdate() 方法来更新文档。
-
使用
updateOne()方法更新单个文档:const User = conn.model('User', userSchema); User.updateOne({ _id: 'user_id' }, { name: 'New Name' }) .then(result => { console.log(result); }) .catch(error => { console.error(error); }) .finally(() => { // 关闭连接 conn.close(); });在这个示例中,我们使用
User模型的updateOne()方法来更新_id值为'user_id'的用户文档。第一个参数是查询条件,指定要更新哪些文档,第二个参数是更新的字段和值。updateOne()方法返回一个Promise,在更新完成后解析为更新结果。 -
使用
updateMany()方法批量更新文档:const User = conn.model('User', userSchema); User.updateMany({ age: { $gte: 18 } }, { isAdult: true }) .then(result => { console.log(result); }) .catch(error => { console.error(error); }) .finally(() => { // 关闭连接 conn.close(); });在这个示例中,我们使用
User模型的updateMany()方法来更新年龄大于等于 18 岁的所有用户文档的isAdult字段为true。updateMany()方法也接受一个查询条件作为第一个参数,并返回一个Promise,在更新完成后解析为更新结果。 -
使用
findByIdAndUpdate()方法根据 ID 更新文档:const User = conn.model('User', userSchema); User.findByIdAndUpdate('user_id', { name: 'New Name' }) .then(result => { console.log(result); }) .catch(error => { console.error(error); }) .finally(() => { // 关闭连接 conn.close(); });在这个示例中,我们使用
User模型的findByIdAndUpdate()方法来更新指定ID的用户文档的name字段。findByIdAndUpdate()方法接受一个 ID 字符串作为第一个参数,并返回一个Promise,在更新完成后解析为更新结果。
除了基本的更新方法外,Mongoose 还提供了丰富的更新选项和方法,如 $set、$inc 等操作符,以及使用原子操作来更新嵌套字段等。
26.5.8 删除文档
在 Mongoose 中,可以使用模型的 deleteOne()、deleteMany() 或 findByIdAndDelete() 方法来删除文档。
-
使用
deleteOne()方法删除单个文档:const User = conn.model('User', userSchema); User.deleteOne({ _id: 'user_id' }) .then(result => { console.log(result); }) .catch(error => { console.error(error); }) .finally(() => { // 关闭连接 conn.close(); });在这个示例中,我们使用
User模型的deleteOne()方法来删除_id值为'user_id'的用户文档。deleteOne()方法返回一个Promise,在删除完成后解析为删除结果。 -
使用
deleteMany()方法批量删除文档:const User = conn.model('User', userSchema); User.deleteMany({ age: { $lt: 18 } }) .then(result => { console.log(result); }) .catch(error => { console.error(error); }) .finally(() => { // 关闭连接 conn.close(); });在这个示例中,我们使用
User模型的deleteMany()方法来删除年龄小于 18 岁的所有用户文档。deleteMany()方法也接受一个查询条件作为第一个参数,并返回一个Promise,在删除完成后解析为删除结果。 -
使用
findByIdAndDelete()方法根据ID删除文档:const User = conn.model('User', userSchema); User.findByIdAndDelete('user_id') .then(result => { console.log(result); }) .catch(error => { console.error(error); }) .finally(() => { // 关闭连接 conn.close(); });在这个示例中,我们使用
User模型的findByIdAndDelete()方法来删除指定ID的用户文档。findByIdAndDelete()方法接受一个 ID 字符串作为第一个参数,并返回一个Promise,在删除完成后解析为删除结果。
需要注意的是,删除文档是一项危险的操作,应该谨慎使用。在删除前,建议先备份数据或者考虑使用软删除等方式保留数据。
26.5.9 聚合管道
在 Mongoose 中,你可以使用 aggregate() 方法来执行聚合管道操作。聚合管道可以在查询过程中对文档进行多个阶段的处理,以便进行数据转换、计算和分析等操作。
下面是一个示例,展示了如何使用聚合管道进行数据处理:
const User = conn.model('User', userSchema);
// 使用聚合管道查询年龄大于等于 18 并且小于等于 30 的用户数量
User.aggregate([
{ $match: { age: { $gte: 18, $lte: 30 } } },
{ $count: 'count' }
])
.exec()
.then(result => {
console.log(result);
})
.catch(error => {
console.error(error);
})
.finally(() => {
// 关闭连接
conn.close();
});
26.5.10 事物操作
在 Mongoose 中,可以使用 session 对象来开启事务操作。在一个事务中,所有的操作要么全部成功提交,要么全部失败回滚,以保证数据的一致性。
下面是示例代码:
const mongoose = require('mongoose');
const { Schema } = mongoose;
const userSchema = new Schema({
name: {
type: String,
required: true,
trim: true,
},
age: {
type: Number,
min: 18,
max: 120,
},
email: {
type: String,
required: true,
unique: true,
lowercase: true,
trim: true,
match: /^\S+@\S+\.\S+$/,
},
createdAt: {
type: Date,
default: Date.now,
},
});
// const User = mongoose.model('User', userSchema);
const uri = 'mongodb://crm:123456@127.0.0.1:27017/db_crm?authSource=db_crm';
try {
const conn = mongoose.createConnection(uri);
if (!conn) {
console.error('Failed connecting to MongoDB');
return
}
console.log('Connected to MongoDB');
const sesstion = await conn.startSession();
// 开启事物
sesstion.startTransaction();
// 在这里可以开始执行数据库操作
const User = conn.model('User', userSchema);
// 创建文档
User.create({ name: 'John', email: 'john@example.com', password: 'password123' })
.then(user => {
console.log(user);
// 提交事务
session.commitTransaction();
})
.catch(error => {
console.error(error);
// 回滚事务
session.abortTransaction();
})
.finally(() => {
// 结束会话
sesstion.endSession();
// 关闭连接
conn.close();
});
} catch (error) {
console.error('Error connecting to MongoDB', error);
}
在这个示例中,我们先使用 mongoose.startSession() 方法创建一个 session 会话对象,并通过 session.startTransaction() 方法开启一个事务。在事务中,我们使用 User.create() 方法创建两个用户文档,并使用 User.updateOne() 方法更新一个用户文档。最后,通过 session.commitTransaction() 方法提交事务或者 session.abortTransaction() 方法回滚事务。无论事务提交或回滚,都需要通过 session.endSession() 方法结束会话。
26.5.11 populate
Mongoose 中的 populate() 方法是一个非常有用的功能,用于填充关联字段。它允许你在查询结果中将关联字段与其关联的文档数据一起返回,而不仅仅是关联字段的引用。
populate() 方法中常用参数的详细介绍:
-
path:指定要填充的字段路径。可以是单个字段的字符串,也可以是嵌套字段的对象路径。
-
select:指定要返回的字段。可以使用字符串或对象形式来指定要返回的字段,类似于 MongoDB 查询中的投影操作符。例如,
select: 'name email'或select: { name: 1, email: 1 }。 -
match:指定填充条件。可以使用对象形式来指定填充条件,类似于 MongoDB 查询中的
$match操作符。例如,match: { age: { $gte: 18 } }。 -
model:指定要关联的模型名称。可以使用字符串形式来指定要关联的模型,如果模型名称与定义的模型名称不一致,可以通过该参数进行指定。
-
options:指定额外的选项。可以使用对象形式来指定额外的选项,包括 sort(排序)、limit(限制填充数量)和 skip(跳过一定数量的填充结果)等。例如,
options: { sort: { createdAt: -1 }, limit: 10 }。 -
populate:嵌套填充。可以使用对象形式来指定嵌套填充的字段,并使用相同的
path、select、match、model和options参数。
下面我们将详细介绍如何使用 populate() 方法来填充关联字段。
假设我们有两个模型:User 和 Article,它们之间存在一对多的关系,一个用户可以发布多篇文章。
首先,我们需要定义模型:
const mongoose = require('mongoose');
const UserSchema = new mongoose.Schema({
name: String,
email: String,
});
const ArticleSchema = new mongoose.Schema({
title: String,
content: String,
author: {
type: mongoose.Schema.Types.ObjectId,
ref: 'User',
},
});
const User = mongoose.model('User', UserSchema);
const Article = mongoose.model('Article', ArticleSchema);
在 Mongoose 中,populate() 方法使用 ref 属性来指定关联字段所引用的模型。ref 属性告诉 Mongoose 要将关联字段与哪个模型进行关联。
接下来,我们可以使用 populate() 方法来填充关联字段。以下是一些常见的用法示例:
-
填充单个字段
const article = await Article.findById(articleId).populate('author');上述代码中,我们通过
findById()方法查找到一篇文章,并使用populate('author')来填充author字段。这将返回包含填充后的author对象的文章对象。 -
填充多个字段
const article = await Article.findById(articleId) .populate('author') .populate('comments');上述代码中,我们通过链式调用
populate()方法来填充多个关联字段。这将返回一个包含填充后的author和comments字段的文章对象。 -
选择要返回的字段
const article = await Article.findById(articleId).populate('author', 'name email');上述代码中,我们使用第二个参数来指定要返回的字段。这将返回一个只包含
name和email字段的填充后的author对象。 -
条件填充
const article = await Article.find().populate({ path: 'author', match: { name: { $regex: /^John/ } }, });上述代码中,我们使用
populate()方法的对象参数形式,并在match中指定了填充条件。这将只填充满足条件的author对象。 -
嵌套填充
const article = await Article.findById(articleId).populate({ path: 'author', populate: { path: 'address', model: 'Address', }, });上述代码中,我们可以通过嵌套调用
populate()方法来填充更深层次的关联字段。这将返回一个包含填充后的author对象和填充后的author对象中嵌套填充的address字段的文章对象。
多表关联
在 Mongoose 中,我们可以使用 populate() 方法来实现多表关联。当我们需要查询一个模型中的文档,并且需要填充该模型中其它模型的文档时,就可以使用 populate() 方法。这个方法可以将一个或多个字段引用的文档替换为其完整的文档内容。
populate() 可以用于一对一、一对多和多对多关联关系。下面我们以一个具体的多表关联的例子来进行讲解。假设我们有3个模型:User、Post和Comment,它们之间的关系如下:
User 模型中有一个属性 articles,表示该用户发布的文章。
Article 模型中有一个属性 author,表示该文章的作者。
Article 模型中有一个属性 comments,表示该文章的评论列表。
Comment 模型中有一个属性 author,表示该评论的作者。
首先,我们需要定义这些模型:
const mongoose = require('mongoose');
const UserSchema = new mongoose.Schema({
name: String,
email: String,
articles: [
{
type: mongoose.Schema.Types.ObjectId,
ref: 'Article',
},
],
});
const ArticleSchema = new mongoose.Schema({
title: String,
content: String,
author: {
type: mongoose.Schema.Types.ObjectId,
ref: 'User',
},
comments: [
{
type: mongoose.Schema.Types.ObjectId,
ref: 'Comment',
},
],
});
const CommentSchema = new mongoose.Schema({
content: String,
author: {
type: mongoose.Schema.Types.ObjectId,
ref: 'User',
},
});
const User = mongoose.model('User', UserSchema);
const Article = mongoose.model('Article', ArticleSchema);
const Comment = mongoose.model('Comment', CommentSchema);
下面是一个示例,展示了如何使用 populate() 方法进行多表关联查询:
-
查询文章列表,并填充其作者和评论列表
const artiles = await Article.find() .populate('author') .populate({ path: 'comments', populate: { path: 'author', }, }); console.log(artiles);上述代码中,我们通过链式调用
populate()方法来填充多个关联字段。其中,populate('author')用于填充author字段对应的用户对象,populate({ path: 'comments',populate: { path: 'author' } })用于填充comments字段对应的评论列表的作者对象。 -
查询用户信息,并填充其发布的文章列表和文章列表中的评论列表
const user = await User.findById(userId) .populate({ path: 'articles', populate: { path: 'comments', populate: { path: 'author', }, }, }); console.log(user);上述代码中,我们首先通过
findById()方法查找到指定的用户,然后使用populate()方法来填充该用户发布的文章列表,以及文章列表中的评论列表和评论列表的作者对象。
你可以根据具体需求在多表关联查询中使用不同的关联字段和查询条件。Mongoose 支持多种类型的关联字段,例如 ObjectId、String、数组等。此外,Mongoose 还支持丰富的查询条件,包括查询选项、字段投影、排序、限制等。你可以参考 Mongoose 官方文档中的 populate() 方法部分以获取更多详细信息和示例。
Mongoose 是非常好用的 ORM 框架,除了上述介绍的内容,Mongoose 还提供了更多强大的功能。如果你想了解更多有关 mongoose 的相关知识,可以查看 mongoose文档。
总结
ORM 技术能够极大地简化 Node.js 中的数据库操作。通过选择合适的 ORM 库,并按照其提供的 API 进行操作,可以更加轻松、高效地完成数据库操作。它们都提供了文档和示例,以帮助你学习和使用。你可以参考官方文档和社区资源,了解更多关于这些框架的详细信息,以便在项目中更高效地操作数据库。
27-RESTful API设计与实现
RESTful API(Representational State Transfer)是一种基于 HTTP 协议的 Web API 设计风格。它的目标是通过使用标准的 HTTP 方法和状态码来实现资源的管理和操作。下面是 RESTful API 的详细介绍:
-
资源(Resource)
在 RESTful API 中,资源是指网络上的某个实体,可以是具体的对象(如用户、文章等),也可以是虚拟的概念(如订单、评论等)。每个资源都有一个唯一的标识符(URI),用于在 API 中进行访问和操作。
对于 RESTful API 资源的命名,名称应当符合
URI的格式规范,并且需要符合以下几个要求:-
清晰和直观:资源的名称应当能够清晰地表达所指代的内容,让使用者能够直观理解。
-
简洁:资源名称应当尽量简洁,避免过长或复杂的命名,提高可读性和易记性。
-
使用名词:资源名称应当使用名词来表示,而不是动词,以便准确描述所表示的实体或概念。
-
使用复数形式:通常情况下,使用资源的复数形式作为 URI 的一部分,以表示该 URI 表示的是一组资源。
例如:
- /users:表示所有用户资源
- /orders:表示所有订单资源
-
避免大小写敏感:为了避免混淆和不一致性,建议在URI中使用小写字母,并且避免使用大小写敏感的资源名称。
-
使用连字符分隔单词:为了提高URI的可读性,可以使用连字符
-或下划线_来分隔多个单词。例如:/user-profiles 或 /user_profiles:表示用户配置文件资源
-
不包含动词:URI 应该描述资源的位置和属性,而不应该包含动词。HTTP 方法已经表示了对资源的操作类型,不需要在 URI 中重复描述。
例如:
- /users/:id:表示特定用户资源
- /users/:id/orders:表示特定用户的订单资源
-
版本控制:如果需要对API进行版本控制,可以将版本号作为URI的一部分。
例如:/v1/users:表示第一个版本的用户资源
-
可以进一步细分,例如:分页、限制个数、过滤等。
例如:/users/page/1/limit/20:表示查询第一页并且限制20个用户资源。
-
-
HTTP 方法(HTTP Methods)
RESTful API 通过使用 HTTP 方法来对资源进行操作。常用的 HTTP 方法包括:
GET:获取资源的信息。
POST:创建新资源。
PUT:更新已存在的资源。
DELETE:删除资源。
PATCH:更新资源的部分属性。 -
URI(Uniform Resource Identifier)
每个资源在 RESTful API 中都需要有一个唯一的
URI作为标识符。URI 应该简洁、清晰,并且能够反映资源的层次结构。例如,/users可以表示所有用户资源,/users/:id可以表示特定用户资源。 -
表示形式(Representation)
资源的表示形式通常使用常见的数据格式,如
JSON或XML。JSON是最常用的表示形式,它是一种轻量级的数据交换格式,易于阅读和解析。 -
状态码(Status Codes)
RESTful API 使用
HTTP状态码来指示请求的结果。常见的状态码包括:- 200:表示成功的 GET 请求。
- 201:表示成功的 POST 请求或创建新资源。
- 204:表示成功的 DELETE 请求或无内容返回。
- 400:表示请求错误,如参数错误或验证失败。
- 404:表示资源未找到。
- 500:表示服务器内部错误。
通过使用适当的状态码,客户端可以根据请求结果进行相应的处理。
RESTful API 是一种基于 HTTP 协议的 Web API 设计风格。它通过使用标准的 HTTP 方法、URI、表示形式和状态码来实现资源的管理和操作。RESTful API 的设计应该遵循资源导向的原则,使得 API 简洁、灵活和易于理解。
27.1 RESTful API 的设计与实现步骤
设计和实现 RESTful API 需要遵循一些基本的原则和步骤。
-
确定资源:首先需要确定要提供的资源。一个资源可以是任何事物,例如用户、文章或者订单。每个资源都需要一个唯一的
URI来标识,例如/users表示所有用户资源。 -
定义 HTTP 动词:HTTP 定义了多种动词,例如
GET、POST、PUT和DELETE等。这些动词可以用来操作资源。例如,使用GET请求可以获取资源,使用POST请求可以创建资源,使用PUT请求可以更新资源,使用DELETE请求可以删除资源。 -
确定响应格式:RESTful API 可以支持多种响应格式,例如
JSON、XML或者HTML等。通常情况下,JSON格式是最常用的响应格式。 -
定义路由:路由是指将请求映射到对应的处理程序的过程。在
RESTful API中,每个资源都需要一个唯一的URI。在处理请求时,服务器会将请求的URI映射到对应的处理程序或者控制器。 -
编写控制器或处理程序:控制器或处理程序是处理请求的核心代码。它们接受请求并返回响应。在 Node.js 中,你可以使用 Express 框架编写控制器或处理程序。
-
添加身份验证和安全性:在设计 RESTful API 时,安全性和身份验证是非常重要的。你可以使用
OAuth、JWT或者其他技术来增加 RESTful API 的安全性和身份验证功能。 -
测试 API:在实现 RESTful API 后,需要对其进行测试。你可以使用 Postman 等工具来测试 API,确保它们能够正确地响应请求,并且返回正确的数据。
下面是一个简单的例子来说明 RESTful API 的设计和实现过程:
假设我们要设计一个用户管理系统,可以对用户进行增删改查操作,那么我们就可以按照以下步骤来设计和实现 RESTful API:
-
确定 API 的目标和功能:我们需要实现一个用户管理系统,支持增删改查操作。
-
确定资源 URI:对于用户资源,我们可以使用
/users作为其唯一URI,而对于单个用户,我们可以使用/users/{id}来表示,其中{id}表示用户的ID号。 -
定义资源模型和属性:用户资源包括
名称、ID、状态等属性,我们需要定义其模型和属性,例如:{ "id": 1, "name": "张三", "age": 20, "gender": "男", "status": "active" } -
定义请求和响应的数据格式:对于查询用户列表操作,我们可以使用
GET方法,并返回一个包含所有用户信息的 JSON 格式数据;对于新增用户操作,我们可以使用POST方法,并传递一个包含需要新增的用户信息的 JSON 数据;对于更新用户信息操作,我们可以使用PUT方法,并传递一个包含更新后的用户信息的 JSON 数据;对于删除用户操作,我们可以使用DELETE方法,并传递一个包含需要删除的用户ID的参数。 -
实现 API 接口:根据上述设计,我们可以实现相应的 API 接口,例如:
GET /users:查询所有用户 POST /users:新增用户 GET /users/{id}:查询单个用户 PUT /users/{id}:更新单个用户 DELETE /users/{id}:删除单个用户
同时,我们还需要对 API 进行测试、文档编写等工作,确保 API 的正确性和易用性。
27.2 RESTful API 处理请求和响应
处理 RESTful API 的请求和响应是非常重要的,下面我将介绍一般情况下处理 RESTful API 请求和响应的流程。
27.2.1 处理请求
-
解析请求:当服务器接收到 HTTP 请求时,首先需要解析请求,包括解析请求头、请求参数、请求体等内容。
-
验证请求:对请求进行验证,包括对请求头中的认证信息进行验证,对请求参数进行合法性验证等。
-
路由分发:根据请求中的 URI 和 HTTP 方法(
GET、POST、PUT、DELETE等)来确定需要调用的具体处理函数或方法。 -
处理请求:根据路由分发的结果,调用相应的处理函数或方法来处理请求,包括对资源进行增删改查等操作。
-
生成响应:处理完请求后,生成相应的响应数据,以便返回给客户端。
27.2.2 处理响应
-
构建响应数据:根据请求处理的结果,构建相应的数据,通常以
JSON或XML格式表示。 -
设置响应头:设置响应的 HTTP 状态码、响应头信息等,确保客户端能够正确处理响应。
-
返回响应:将构建好的响应数据发送给客户端,通常使用 HTTP 协议中的响应流来发送数据。
-
异常处理:如果在处理请求过程中出现了异常情况,需要捕获异常并返回相应的错误信息。
以上是一般情况下处理 RESTful API 请求和响应的流程。在实际开发中,可以根据具体的需求和技术栈来进行相应的实现,例如使用 Express 框架、Flask 框架等来简化请求和响应的处理过程。
27.3 RESTful API 错误处理和验证
在设计 RESTful API 时,错误处理和验证是非常重要的部分,下面我将介绍一些常见的方法来处理错误和验证。
27.3.1 错误处理
-
返回合适的 HTTP 状态码:根据错误的类型,返回相应的 HTTP 状态码,例如
200表示成功,400表示客户端请求错误,500表示服务器内部错误等。 -
返回错误信息:在响应中返回错误信息,通常使用
JSON或者XML格式表示,包含错误码、错误描述等信息,方便客户端进行错误处理。 -
统一错误格式:为了方便客户端处理错误,可以定义一个统一的错误格式,包括错误码、错误描述、详细错误信息等,确保错误信息的一致性。
-
记录错误日志:对于服务器内部的错误,需要及时记录日志,以便进行故障排查和修复。
27.3.2 验证
-
请求参数验证:对客户端传递的请求参数进行验证,包括参数的类型、长度、合法性等,确保请求参数的有效性。
-
身份验证:对需要进行身份验证的 API,进行用户认证,确保只有授权的用户可以访问受限资源。
-
权限验证:对需要进行权限控制的 API,进行权限验证,确保用户具备相应的权限才能执行相应的操作。
-
输入验证:对于用户输入的内容进行验证,包括格式、长度、合法性等,防止恶意输入和安全漏洞。
-
数据完整性验证:在对资源进行更新操作时,需要验证传递的数据是否完整,并进行相应的处理。
-
异常处理:对于验证失败的情况,需要返回相应的错误码和错误信息,指导客户端进行正确的操作。
总之,设计和实现 RESTful API 需要遵循一定的原则和步骤,通过合理使用 URI、HTTP 方法、数据格式等,可以使得 API 更加易用、可靠、安全和高效。
总结
RESTful API 的设计与实现应该遵循一些约定和原则,以提供简单、可扩展和易于理解的接口。通过使用合适的 HTTP 方法、语义化的 URL、合适的状态码和数据格式,以及其他相关的实践,可以构建出高质量的 RESTful API。
28-Express框架入门
Express 是一个流行的 Node.js 后端框架(MCV框架),它提供了一组简洁、灵活和可扩展的工具和中间件,用于构建 Web 应用程序和 RESTful API。下面我将介绍一些 Express 的特点和主要功能。
特点:
-
轻量灵活:Express 是一个轻量级的框架,它提供了基本的功能,并且非常灵活,可以根据需求进行定制和扩展。
-
易于学习和使用:Express 的 API 设计简洁直观,学习曲线较低,开发者可以快速上手并构建应用程序。
-
中间件支持:Express 支持中间件机制,可以方便地进行请求处理、路由、错误处理、身份验证等功能的扩展和定制。
-
兼容 Connect 中间件:Express 兼容 Connect 中间件,可以使用大量的第三方中间件来扩展功能,如日志记录、会话管理等。
-
模板引擎支持:Express 提供了对多种模板引擎的支持,如
EJS、Pug(之前的Jade)、Handlebars等,方便生成动态页面。
主要功能:
-
路由和请求处理:Express 提供了简单而强大的路由功能,可以定义多个路由路径和 HTTP 方法的处理函数,以便处理客户端请求。
-
中间件支持:Express 的中间件机制允许开发者定义和使用各种中间件函数,用于处理请求、验证身份、错误处理、日志记录等任务。
-
静态文件服务:通过 Express 可以方便地提供静态文件服务,如图片、CSS文件、JavaScript文件等,使其可以直接访问。
-
模板引擎集成:Express 可以与多种模板引擎无缝集成,通过模板引擎可以生成动态的 HTML 页面,方便构建视图。
-
错误处理:Express 提供了中间件来处理应用程序中的错误,可以自定义错误处理逻辑,并返回适当的错误响应给客户端。
-
会话管理:通过使用中间件,Express 可以方便地实现会话管理,例如存储会话数据、设置会话过期时间等。
-
数据库集成:Express 可以与多种数据库集成,如 MongoDB、MySQL 等,方便进行数据存储和查询。
以上是 Express 的一些特点和主要功能。它的简洁性、灵活性和丰富的生态系统使其成为构建 Web 应用程序和 RESTful API 的首选框架之一。
安装和配置 Express 框架
-
安装 Express:进入项目目录,在命令行中输入
npm install express --save命令,安装 Express 并将其添加到项目依赖中。 -
创建应用程序:在项目目录下创建一个名为
app.js的文件,用于编写应用程序代码。 -
编写应用程序:在
app.js文件中编写 Express 应用程序,包括路由、中间件、模板引擎等。 -
运行应用程序:在命令行中输入
node app.js命令,运行应用程序。
28.1 快速入门
下面是一个简单的 Express 应用程序示例,包含路由、中间件和模板引擎:
// 引入 Express 模块
const express = require('express')
// 创建 Express 应用程序对象
const app = express()
// 中间件示例:输出请求方法和路径
app.use((req, res, next) => {
console.log(`${req.method} ${req.path}`)
next()
})
// 路由示例:处理 GET 请求
app.get('/', (req, res) => {
res.send('Hello World!')
})
// 启动应用程序
app.listen(3000, () => {
console.log('Express app is listening on port 3000.')
})
在以上示例中,我们使用 express() 创建了一个 Express 应用程序对象,并使用 app.get() 定义了一个处理 GET 请求的路由。同时,我们使用 app.use() 定义了一个输出请求方法和路径的中间件。
以上是安装和配置 Express 框架的基本步骤和一个简单的 Express 应用程序示例。在实际开发中,可以根据需求添加和定制路由、中间件和模板引擎等功能。
28.2 Express脚手架
Express 脚手架是一个快速创建 Express 应用程序的工具,它提供了一些常用的工程结构、模板引擎、路由、中间件等,帮助开发者快速创建一个可用的 Express 应用程序,减少重复性工作,提高开发效率。
使用 Express 脚手架可以快速创建一个 Express 应用程序,步骤如下:
-
安装 Express 脚手架:使用 npm 全局安装 Express 脚手架。
npm install -g express-generator -
创建 Express 应用程序:使用 express 命令创建一个 Express 应用程序。
express myapp其中,
myapp是应用程序的名称,执行以上命令后,脚手架会在当前目录下创建一个名为myapp的应用程序。 -
安装依赖:进入应用程序目录,使用
npm install命令安装应用程序所需的依赖包。cd myapp npm install -
启动应用程序:使用
npm start命令启动应用程序。npm start执行以上命令后,应用程序会监听在默认端口
3000上,可以在浏览器中访问http://localhost:3000来查看应用程序是否正常运行。
除了上述基本使用方法外,Express 脚手架还支持更多的选项和功能,例如:
-
指定模板引擎:使用
--view选项来指定模板引擎,默认为Jade。express --view=ejs myapp -
设置端口号:使用 --port 选项来设置应用程序监听的端口号。
express --port=8080 myapp -
使用 Sass:使用
--css sass选项来使用Sass作为CSS预处理器。express --css sass myapp
Express 脚手架是一个非常方便的工具,可以帮助开发者快速创建一个可用的 Express 应用程序,同时也提供了许多选项和功能,可以根据实际需求进行定制和配置。
28.3 常用方法
下面详细介绍一下 Express 中常用的一些方法:
-
express(): 这是一个用于创建 Express 应用程序的顶级函数。它返回一个 Express 应用程序对象。
const express = require('express'); const app = express(); -
app.use([path], middleware): 这个方法用于将中间件函数绑定到应用程序上。中间件函数在请求处理之前执行,可以用来处理请求、响应、错误等。path 参数可选,用于限制中间件只在特定的路径下执行。
app.use((req, res, next) => { console.log('This middleware will be executed for every request'); next(); }); -
app.get(path, callback): 这个方法用于处理 HTTP GET 请求。当客户端发送 GET 请求到指定的路径时,会触发回调函数执行。
app.get('/hello', (req, res) => { res.send('Hello World!'); }); -
app.post(path, callback): 这个方法用于处理 HTTP POST 请求。与
app.get()类似,但仅对 POST 请求起作用。app.post('/login', (req, res) => { // 处理登录逻辑 }); -
app.put(path, callback), app.delete(path, callback): 这些方法用于处理 HTTP PUT 和 DELETE 请求。与
app.get()类似,但仅对相应的请求方法起作用。 -
app.listen(port, [host], [callback]): 这个方法用于启动 Express 应用程序并监听指定的端口。可选的
host参数用于指定监听的主机名,默认为localhost。可选的callback参数在服务器成功启动后执行。app.listen(3000, () => { console.log('Server is listening on port 3000'); }); -
除了上述方法外,Express 还提供了许多其他方法,例如:
- app.all(path, callback): 这个方法用于处理所有 HTTP 请求方法的请求。
- app.route(path): 这个方法返回一个用于处理特定路径的路由对象。
- app.param(name, callback): 这个方法为路由参数添加回调函数。
- app.set(name, value): 这个方法设置应用程序的配置变量。
- app.enable(name), app.disable(name): 这些方法用于启用或禁用应用程序的配置变量。
- app.engine(ext, callback): 这个方法注册模板引擎。
- app.render(view, [locals], callback): 这个方法渲染模板并将其发送到客户端。
- app.use(express.static(path)): 这个方法提供静态文件服务。
28.4 路由
在 Express 中,路由是用于处理客户端请求的机制。路由可以根据请求的路径和 HTTP 方法来匹配相应的处理函数,并返回对应的响应结果。在 Express 中,路由可以通过 get()、post()、put()、delete() 等方法进行定义。
Express 路由的基本语法如下:
app.METHOD(PATH, HANDLER)
其中,app 是一个 Express 实例对象,METHOD 是 HTTP 请求方法,PATH 是请求路径,HANDLER 是处理函数。
路由的匹配过程是按照注册顺序依次进行的,即先注册的路由优先匹配。如果有多个路由匹配到同一个路径和 HTTP 方法,则只会使用第一个匹配到的路由。
下面是一个简单的 Express 路由示例:
// 引入 Express 模块
const express = require('express');
// 创建 Express 应用程序对象
const app = express();
// 处理 GET 请求
app.get('/', (req, res) => {
res.send('Hello, Express!');
});
// 处理 POST 请求
app.get('/users', (req, res) => {
res.send('Create a new user. res.data=', res.data);
});
// 启动应用程序
app.listen(3000, () => {
console.log('Express app is listening on port 3000.')
})
在以上示例中,我们使用了 get()、post()、put()、delete() 方法分别定义了处理 GET、POST、PUT、DELETE 请求的路由。其中,/users/:id 是一个动态路由,可以匹配 /users/123、/users/456 等路径。
在 Express 中还有另一种常用的路由方式,即使用 app.route() 方法进行链式路由。这种方式可以将多个路由方法绑定到同一个路径上,并使用相同的中间件和处理函数。
下面是一个使用 app.route() 进行链式路由的示例:
// 使用 app.route() 进行链式路由
app.route('/users')
.get((req, res) => {
res.send('Get all users.')
}).post((req, res) => {
res.send('Create a new user.')
})
.put((req, res) => {
res.send('Update all users.')
})
.delete((req, res) => {
res.send('Delete all users.')
})
在以上示例中,我们使用 app.route('/users') 定义了一个处理 /users 路径的路由,并使用 get()、post()、put()、delete() 方法分别定义了处理 GET、POST、PUT、DELETE 请求的处理函数。
以上是 Express 路由的基本语法和示例。在实际开发中,可以根据需求添加和定制路由,如定义动态路由、使用中间件、发送文件等。
28.4.1 express的模块化路由
在 Express 中,你可以通过模块化路由将应用程序的路由划分为多个文件或模块。这样做不仅使代码更加易于维护和组织,而且还允许多个开发人员在同一应用程序上工作而不会相互干扰。
以下是实现 Express 模块化路由的基本步骤:
-
创建 Express 应用程序:
const express = require('express'); const app = express(); -
创建一个路由模块:
在单独的文件中创建一个路由模块,然后导出路由处理函数。
// userRoutes.js const express = require('express'); const router = express.Router(); router.get('/', (req, res) => { res.send('Get all users'); }); module.exports = router; -
导入路由模块:
在主应用程序中导入路由模块,然后将其挂载到特定的路径上。
const express = require('express'); // 创建服务器实例对象 const app = express(); onst userRoutes = require('./userRoutes'); app.use(userRoutes); // 将 userRoutes 模块注册到主应用程序中 // 启动应用程序 app.listen(3000, () => { console.log('Express app is listening on port 3000.') })
注意:在路由模块中,你不需要使用 app 对象来定义路由,而是使用 express.Router() 方法来创建路由器。然后,你可以像在主应用程序中一样使用 router 对象定义路由。
在模块化路由中,每个路由模块都是一个独立的文件,负责处理特定的 HTTP 请求和路径。你可以创建多个路由模块,并将它们挂载到不同的路径上以实现更好的组织和维护。
28.4.2 请求参数
在 Express 中,可以通过不同的方式来处理请求参数。以下是几种常见的处理请求参数的方法:
-
Query 参数:
Query参数是通过 URL 查询字符串传递的参数,通常用于 GET 请求。在 Express 中,可以使用req.query对象来访问Query参数Query参数是通过 URL 查询字符串传递的参数,通常用于 GET 请求。- 在 Express 中,可以使用
req.query对象来访问Query参数。 - 例如,对于 URL
/search?keyword=apple,可以通过req.query.keyword来获取keyword参数的值。
// GET /search?keyword=apple app.get('/search', (req, res) => { const keyword = req.query.keyword; // 根据关键字进行搜索 }); -
路径参数:
路径参数是通过 URL 路径中的占位符来传递的参数,通常用于动态路由。在 Express 中,可以使用
:来定义路径参数,并使用req.params对象来访问路径参数。- 路径参数是通过 URL 路径中的占位符来传递的参数,通常用于动态路由。
- 在 Express 中,可以使用
:来定义路径参数,并使用req.params对象来访问路径参数。 - 例如,对于路由规则
/users/:id,可以通过req.params.id来获取id参数的值。
// GET /users/123 app.get('/users/:id', (req, res) => { const userId = req.params.id; // 根据用户 ID 进行相应的处理 }); -
请求体参数:
请求体参数是通过请求体传递的参数,通常用于 POST、PUT 等请求。在 Express 中,默认情况下无法直接访问请求体参数,需要使用中间件来解析请求体。常用的中间件有
body-parser、multer等。- 请求体参数是通过请求体传递的参数,通常用于 POST、PUT 等请求。
- 在 Express 中,默认情况下无法直接访问请求体参数,需要使用中间件来解析请求体。
- 常用的中间件有
body-parser、multer等。 - 使用
body-parser中间件可以将请求体参数解析为JSON格式,然后可以通过req.body访问请求体参数。
const express = require('express'); const bodyParser = require('body-parser'); const app = express(); app.use(bodyParser.urlencoded({ extended: false })); app.use(bodyParser.json()); app.post('/login', (req, res) => { const username = req.body.username; const password = req.body.password; // 处理登录逻辑 });上述例子中使用了
body-parser中间件来解析请求体,然后可以通过req.body访问请求体参数。 -
请求头参数:
请求头参数是通过请求头中的字段来传递的参数,通常用于需要额外信息的请求。在 Express 中,可以使用
req.headers对象来访问请求头参数。- 请求头参数是通过请求头中的字段来传递的参数,通常用于需要额外信息的请求。
- 在 Express 中,可以使用
req.headers对象来访问请求头参数。 - 例如,可以通过
req.headers['user-agent']来获取User-Agent请求头参数。
app.get('/user-agent', (req, res) => { const userAgent = req.headers['user-agent']; // 根据 User-Agent 处理逻辑 // 或者 const headers = res.json(req.headers); });
上述方法中,Query 参数和路径参数是在路由规则中直接定义的,而请求体参数和请求头参数需要使用相应的中间件进行解析。根据具体的需求,选择合适的方式来获取和处理请求参数。
28.4.3 路由路径
EXpress 是如何处理路由路径的?
在 Express 中,可以使用路由来定义特定的 URL 路径,并指定相应的处理逻辑。以下是一些常见的处理路由路径的方法:
-
精确匹配路径:
- 通过使用字符串作为路径,可以实现精确匹配。
- 例如,
app.get('/home', callback)将匹配路径为/home的 GET 请求。
-
使用占位符:
- 使用 : 占位符可以创建动态路由,将 URL 的一部分作为参数传递给处理程序。
- 例如,
app.get('/users/:id', callback)将匹配路径为/users/123的GET请求,并将123作为id参数传递给回调函数。
-
使用正则表达式:
- 可以使用正则表达式来匹配更复杂的路径模式。
- 例如,
app.get(/\/users\/[0-9]+/, callback)将匹配路径为/users/123、/users/456等的GET请求。
-
使用通配符:
- 使用
\*通配符可以匹配任意路径。 - 例如,
app.get('*', callback)将匹配所有路径的 GET 请求。
- 使用
-
使用路由参数:
- 可以将路由参数定义为一个独立的对象,并在多个路由中复用。
- 例如,
const userRouter = express.Router()创建一个路由参数对象,然后可以在多个路由中使用userRouter.get('/profile', callback)、userRouter.get('/settings', callback)等。
28.5 处理HTTP请求
Express 提供了一系列的功能和工具,方便开发者处理 HTTP 请求。下面我将详细介绍 Express 如何处理 HTTP 请求:
28.5.1 请求方法
在 Express 中,常用的请求方法(HTTP Methods)包括:
- GET:用于获取资源。例如,从服务器获取网页、图像、数据等。
- POST:用于向服务器提交数据,并创建新的资源。例如,提交表单数据、上传文件等。
- PUT:用于更新服务器上的资源。例如,更新用户信息、修改文章内容等。
- DELETE:用于删除服务器上的资源。例如,删除用户、删除评论等。
- PATCH:用于对服务器资源进行部分更新。例如,修改用户的部分信息、更新文章的某个字段等。
- HEAD:与 GET 类似,但只返回响应头部信息,不返回实际内容。
- OPTIONS:用于获取服务器支持的请求方法列表。
- TRACE:用于回显服务器收到的请求,用于测试或诊断。
- CONNECT:用于代理服务器与目标服务器之间的隧道通信。
在 Express 应用程序中,可以通过路由处理程序来定义相应的请求方法。例如:
// GET 请求处理程序
app.get('/users', (req, res) => {
// 处理 GET 请求逻辑
});
// POST 请求处理程序
app.post('/users', (req, res) => {
// 处理 POST 请求逻辑
});
// PUT 请求处理程序
app.put('/users/:id', (req, res) => {
// 处理 PUT 请求逻辑
});
// DELETE 请求处理程序
app.delete('/users/:id', (req, res) => {
// 处理 DELETE 请求逻辑
});
// PATCH 请求处理程序
app.patch('/users/:id', (req, res) => {
// 处理 PATCH 请求逻辑
});
// HEAD 请求处理程序
app.head('/users', (req, res) => {
// 处理 HEAD 请求逻辑
});
// OPTIONS 请求处理程序
app.options('/users', (req, res) => {
// 处理 OPTIONS 请求逻辑
});
// TRACE 请求处理程序
app.trace('/users', (req, res) => {
// 处理 TRACE 请求逻辑
});
// CONNECT 请求处理程序
app.connect('/users', (req, res) => {
// 处理 CONNECT 请求逻辑
});
在上述示例中,我们使用了 Express 的应用程序实例 app 来定义不同请求方法对应的路由。通过调用相应的方法(如 get、post、put 等),指定路由路径和对应的处理程序函数。当客户端发送请求时,Express 会匹配对应的路由,并执行相应的处理程序。
除了上述常用的请求方法外,Express 还提供了 app.all() 方法来匹配所有的请求方法,以及 app.use() 方法来处理所有的请求方法。这些方法可以用于定义通用的路由处理逻辑,如身份验证、日志记录等。
上述是 Express 中常用的请求方法及其用法。你可以根据具体的需求,选择合适的请求方法来处理不同类型的请求。
28.5.2 请求对象(Request Object)
在 Express 中,req 对象代表 HTTP 请求,开发者可以通过 req 对象获取请求的参数、头部信息、请求体等内容。
以下是一些常用的 Express 请求对象的属性和方法:
-
req.params:
- 表示从 URL 路径中提取的路由参数。例如,对于路由规则
/users/:id,可以使用req.params.id访问id参数的值。
- 表示从 URL 路径中提取的路由参数。例如,对于路由规则
-
req.query:
- 表示从 URL 查询字符串中提取的查询参数。例如,对于 URL
/search?keyword=apple,可以使用req.query.keyword访问keyword参数的值。
- 表示从 URL 查询字符串中提取的查询参数。例如,对于 URL
-
req.body:
-
表示请求体中的参数。在默认情况下,Express 无法直接访问请求体参数,需要使用相应的中间件(如
body-parser)来解析请求体。 -
例如,使用
body-parser中间件可以将请求体参数解析为JSON格式,然后可以通过req.body访问请求体参数。
-
-
req.headers:
- 表示请求头的对象。可以通过
req.headers['header-name']的方式访问特定的请求头参数,如req.headers['user-agent']访问User-Agent请求头参数。
- 表示请求头的对象。可以通过
-
req.cookies:
- 表示客户端发送的
Cookie。可以通过req.cookies['cookie-name']的方式访问特定的 Cookie 值。
- 表示客户端发送的
-
req.method:
- 表示请求的 HTTP 方法,如 GET、POST、PUT 等。
-
req.path:
- 表示请求的路径,不包括查询字符串。
-
req.protocol:
- 表示请求的协议,如 HTTP 或 HTTPS。
-
req.ip:
- 表示客户端的 IP 地址。
-
req.get(headerName):
- 获取指定请求头的值。例如,
req.get('Content-Type')可以获取请求头中的Content-Type值。
- 获取指定请求头的值。例如,
通过使用这些请求对象的属性和方法,可以方便地获取和操作请求的各个部分。
28.5.3 响应对象(Response Object)
res 对象代表 HTTP 响应,开发者可以通过 res 对象设置响应的状态码、头部信息、以及发送响应数据等。
在 Express 中,响应对象(Response Object)是通过回调函数的第二个参数传递给路由处理程序或中间件函数的。它提供了向客户端发送 HTTP 响应的各种属性和方法。
以下是一些常用的 Express 响应对象的属性和方法:
-
res.send(body):
-
向客户端发送响应体。
body可以是字符串、对象、数组等类型的数据。 -
例如,使用
res.send('Hello World!')可以向客户端发送一个简单的文本响应。
-
-
res.json(data):
-
向客户端发送
JSON格式的响应体。 -
例如,使用
res.json({ message: 'Hello World!' })可以向客户端发送一个JSON对象响应。
-
-
res.status(code):
-
设置响应的 HTTP 状态码。
-
例如,使用
res.status(404)可以设置响应的状态码为404。
-
-
res.setHeader(name, value):
-
设置响应头参数。
-
例如,使用
res.setHeader('Content-Type', 'text/html')可以设置响应头的Content-Type参数为text/html。
-
-
res.cookie(name, value, options):
- 向客户端发送一个 Cookie。该方法接受以下参数:
- name:
Cookie的名称。 - value:
Cookie的值。 - options(可选):一个对象,用于指定
Cookie的选项,如过期时间、域、路径、安全性等。
- name:
const express = require('express'); const app = express(); app.get('/set-cookie', (req, res) => { res.cookie('my_cookie', 'cookie_value', { maxAge: 3600000, // 过期时间为 1 小时 httpOnly: true, // 只能通过 HTTP 访问 Cookie secure: true, // 仅在 HTTPS 连接中发送 Cookie }); res.send('Cookie 已设置'); }); app.listen(3000, () => { console.log('服务器正在监听端口 3000'); });在上述示例中,当客户端请求
/set-cookie路径时,服务器会设置一个名为my_cookie的 Cookie,其值为cookie_value。此外,通过options对象设置了 Cookie 的过期时间为1小时,只能通过 HTTP 访问,并且仅在 HTTPS 连接中发送。res.cookie()方法将根据提供的参数设置响应头中的Set-Cookie字段,告诉浏览器设置相应的 Cookie。浏览器将在后续的请求中将该 Cookie 发送到服务器。请注意,
res.cookie()方法可以多次调用以设置多个 Cookie。有关更多详细信息,请参阅 Express 文档中res.cookie()的说明。 - 向客户端发送一个 Cookie。该方法接受以下参数:
-
res.redirect(url):
-
重定向客户端到指定的 URL。
-
例如,使用
res.redirect('/home')可以将客户端重定向到 /home 路径。
-
-
res.render(view, [locals], [callback]):
-
使用指定的模板引擎渲染指定的视图,并将结果发送给客户端。
-
例如,使用
res.render('index', { title: 'Home' })可以使用默认的模板引擎渲染名为 index 的视图,并将 { title: ‘Home’ } 对象作为局部变量传递给视图。
-
-
res.download(path, [filename], [options], [callback]):
用于将文件作为附件下载到客户端。方法接受以下参数:
- path:要下载的文件路径。
- filename(可选):指定下载时的文件名。如果未提供,则使用
path的基本名称作为默认文件名。 - options(可选):一个对象,用于指定其他选项,如设置响应头、自定义文件名编码等。
- callback(可选):一个回调函数,当下载完成或发生错误时被调用。
const express = require('express'); const app = express(); app.get('/download', (req, res) => { const filePath = '/path/to/file.pdf'; // 要下载的文件路径 res.download(filePath, 'my_file.pdf', (err) => { if (err) { // 发生错误时的处理 console.error(err); res.status(500).send('下载文件时发生错误'); } }); }); app.listen(3000, () => { console.log('服务器正在监听端口 3000'); });在上述示例中,当客户端请求
/download路径时,服务器会将/path/to/file.pdf文件作为附件下载。如果成功下载,将使用文件名my_file.pdf,否则将返回一个500错误响应。请注意,
res.download()方法会自动设置响应头,使浏览器以下载文件的方式处理响应。浏览器通常会根据文件扩展名推断MIME类型并使用适当的应用程序打开下载文件。如果需要自定义响应头或其他选项,请参阅 Express 文档中res.download()的详细说明。
通过使用这些响应对象的属性和方法,可以方便地设置和发送响应的各个部分。
28.5.4 错误处理
Express 提供了专门的机制来处理错误,开发者可以使用 app.use 或特定的错误处理中间件来捕获并处理应用程序中出现的错误。
28.5.5 静态文件服务
Express 提供了内置的中间件 express.static 用于提供静态文件服务,这样开发者可以轻松地提供图片、CSS文件、JavaScript文件等静态资源。
28.6 使用Express和ws实现Websocket
下面是一个使用 Express 和 ws 实现 WebSocket 的示例代码:
28.6.1 服务端
server.js
const express = require('express');
const app = express();
const server = require('http').createServer(app);
const WebSocket = require('ws');
// 创建 WebSocket 服务器
const wss = new WebSocket.Server({ server });
// 监听 WebSocket 连接
wss.on('connection', (ws) => {
// 处理 WebSocket 连接消息
ws.on('message', (message) => {
console.log(`Received message: ${message}`);
// 发送消息给客户端
ws.send(`Server received: ${message}`);
});
});
// 启动服务器
server.listen(3000, () => {
console.log('Server started on port 3000');
});
6.2 客户端
client.js
const socket = new WebSocket('ws://localhost:3000');
// 连接建立后发送消息
socket.addEventListener('open', (event) => {
socket.send('Hello Server!');
});
// 接收来自服务器的消息
socket.addEventListener('message', (event) => {
console.log('Received from server: ', event.data);
});
// 关闭连接
socket.addEventListener('close', (event) => {
console.log('Connection closed');
});
通过以上步骤,你可以在 Express 中使用 WebSocket(ws) 模块实现 WebSocket 功能。在服务器端,你需要创建一个 WebSocket 服务器并监听连接事件和消息事件。在客户端,你可以使用 JavaScript 创建 WebSocket 客户端,并与服务器建立连接、发送消息、接收来自服务器的消息等。
总结
Express 是一个简单、灵活且易于使用的Web应用程序框架。它提供了一组强大的工具和功能,使开发人员能够快速构建高性能的Web应用程序。无论是构建小型项目还是大型应用程序,Express 都是一个强大且值得推荐的选择。
29-中间件
在 Express 中,中间件是一个函数,用于处理 HTTP 请求和响应。它在请求到达路由处理之前或者在响应发送回客户端之前进行处理。中间件函数可以执行一系列的操作,例如身份验证、日志记录、错误处理等。
29.1 自定义中间件
以下是在 Express 中使用中间件的基本步骤:
- 创建 Express 应用程序:
const express = require('express');
const app = express();
- 编写中间件函数:
中间件函数采用三个参数:request(请求对象)、response(响应对象)和 next(下一个中间件函数或路由处理函数)。
const myMiddleware = (req, res, next) => {
// 在这里执行中间件逻辑
console.log('This is my middleware');
if (isAuthenticated(req)) {
next(); // 调用 next() 将控制权传递给下一个中间件函数或路由处理函数
}
res.status(401).send('未经授权的访问');
};
- 使用中间件:
使用 app.use 或 app.METHOD(其中 METHOD 是 HTTP 请求方法,例如 app.get、app.post)将中间件绑定到应用程序。
app.get('/users', (req, res) => {
// 路由处理逻辑
res.send('Get all users');
});
中间件函数可以按照添加的顺序依次执行。在中间件函数中,你可以执行一些操作,如处理请求的数据、验证用户身份、记录日志、错误处理等。如果需要将控制权传递给下一个中间件函数或路由处理函数,可以调用 next() 方法。
注意:next() 方法只能在中间件函数中调用,否则会导致请求挂起。
Express 中间件分类
Express 中间件还有其他高级功能,例如应用级别的中间件、路由级别的中间件、错误处理中间件、内置中间件和第三方中间件等。你可以根据自己的需求选择合适的中间件来增强你的 Express 应用程序。
29.2 Express内置中间件
Express 内置了一些常用的中间件,它们可以在应用程序中使用来处理请求和响应。下面是 Express 内置中间件的一些详细介绍:
29.2.1 static
用于提供静态文件的访问。通过使用 express.static 中间件,你可以指定一个目录,使得其中的静态文件可以通过 HTTP 请求直接访问,而不需要经过额外的路由处理。
const express = require('express');
const path = require('path');
const app = express();
// 使用 express.static 中间件来指定静态文件目录
app.use(express.static(path.join(__dirname, 'public')));
// 启动服务器
app.listen(3000, () => {
console.log('服务器已启动,监听端口 3000');
});
在上面的示例中,我们首先引入了必要的模块,包括 express 和 path。然后创建了一个 Express 应用实例,并使用 express.static 中间件来指定静态文件目录为 public 目录。
假设在项目根目录下有一个名为 public 的目录,里面包含一些静态文件,比如 index.html、style.css、script.js 等。通过使用 express.static 中间件,这些静态文件就可以直接通过相对路径访问,比如 http://localhost:3000/index.html、http://localhost:3000/style.css 等。
29.2.2 json
这个中间件用于解析 JSON 格式的请求体,并将解析后的数据作为 req.body 对象的一部分。你可以使用它来处理通过 POST 请求发送的 JSON 数据。
使用 express.json 中间件非常简单,只需要调用该方法即可。在调用该方法后,Express 就会自动将请求体中的 JSON 数据解析成 JavaScript 对象。
const express = require('express');
const app = express();
// 使用 express.json 中间件
app.use(express.json());
// 定义路由处理函数
app.post('/', function(req, res) {
// 从请求中获取 JSON 数据
const data = req.body;
console.log(data);
res.send(`Hello, ${data.name}!`);
});
// 启动服务器
app.listen(3000, () => {
console.log('服务器已启动,监听端口 3000');
});
在上面的代码中,我们首先引入了 express 模块。然后创建了一个 Express 应用实例,并使用 express.json 中间件来解析传入的请求体中的 JSON 数据。接着,定义了一个 POST 请求的路由 /,其中从请求中获取 JSON 数据,并在响应中返回一个问候语。
29.2.3 urlencoded
这个中间件用于解析 URL 编码的请求体,并将解析后的数据作为 req.body 对象的一部分。你可以使用它来处理通过 POST 请求发送的 URL 编码数据。
const express = require('express');
const app = express();
// 使用 express.urlencoded 中间件
app.use(express.urlencoded({ extended: false }));
// 定义路由处理函数
app.post('/', function(req, res) {
// 从请求中获取 URL 编码数据
const data = req.body;
console.log(data);
res.send(`Hello, ${data.name}!`);
});
// 启动服务器
app.listen(3000, () => {
console.log('服务器已启动,监听端口 3000');
});
在上面的代码中,我们首先引入了 express 模块。然后创建了一个 Express 应用实例,并使用 express.urlencoded 中间件来解析传入请求体中的 URL 编码数据。接着,定义了一个 POST 请求的路由 /,其中从请求中获取 URL 编码数据,并在响应中返回一个问候语。
29.2.4 Router
用于创建模块化的路由处理器。通过使用 express.Router,你可以将路由处理器模块化,以便更好地组织和管理你的路由。
routes.js
// routes.js
const express = require('express');
const router = express.Router();
router.get('/', function(req, res) {
res.send('首页');
});
router.get('/about', function(req, res) {
res.send('关于页面');
});
module.exports = router;
app.js
// app.js
const express = require('express');
const routes = require('./routes');
const app = express();
// 使用路由处理器
app.use('/', routes);
// 启动服务器
app.listen(3000, () => {
console.log('服务器已启动,监听端口 3000');
});
在上面的示例中,我们首先创建了一个名为 routes.js 的新文件,其中定义了一个基于 express.Router 的路由处理器。在该路由处理器中,我们定义了两个路由,分别处理根路径 / 和关于页面路径 /about 的请求。
然后,在 app.js 中,我们引入了 routes.js 中定义的路由处理器,并使用 app.use 来将其应用到根路径上。这样,当用户访问根路径或者 /about 路径时,Express 就会使用我们定义的路由处理器来处理请求。
29.2.5 cookieParser
用于解析 HTTP 请求中的 Cookie。它可以将 HTTP 请求头中包含的 Cookie 字符串解析成 JavaScript 对象,方便我们在后续的处理中使用。
使用 express.cookieParser 只需要调用该方法并传入一个密钥即可。这个密钥用于对 Cookie 进行加密,以增强安全性。
const express = require('express');
const cookieParser = require('cookie-parser');
const app = express();
// 使用 cookieParser 中间件,并传入一个密钥
app.use(cookieParser('my secret'));
// 定义路由处理函数
app.get('/', function(req, res) {
// 从请求中获取名为 'mycookie' 的 Cookie
const mycookie = req.cookies.mycookie;
if (mycookie) {
res.send(`Hello, you have mycookie: ${mycookie}`);
} else {
// 在响应中设置名为 'mycookie' 的 Cookie
res.cookie('mycookie', 'hello', { maxAge: 900000, httpOnly: true });
res.send('Hello, cookie has been set.');
}
});
// 启动服务器
app.listen(3000, () => {
console.log('服务器已启动,监听端口 3000');
});
在上面的代码中,我们首先引入了 express 和 cookie-parser 模块。然后创建了一个 Express 应用实例,使用 cookieParser 中间件并传入一个密钥。接着,定义了一个 GET 请求的路由 /,其中首先从请求中获取名为 mycookie 的 Cookie,如果存在则返回响应;否则,在响应中设置名为 mycookie 的 Cookie。
29.2.6 basicAuth
Express 框架中的一个基本身份验证中间件。它可以用于保护需要身份验证的路由,要求用户在访问路由时提供用户名和密码。
使用 express.basicAuth 只需传递一个用户名和密码的验证函数即可。下面是一些示例代码,展示如何在 Express 中使用 express.basicAuth 中间件:
const express = require('express');
const app = express();
// 用户名和密码的验证函数
function checkUser(username, password) {
return username === 'admin' && password === 'password';
}
// 使用 basicAuth 中间件来保护路由
app.get('/protected', express.basicAuth(checkUser), function(req, res) {
res.send('欢迎访问受保护的页面');
});
// 错误处理中间件,用于捕获前面中间件中的错误
app.use(function(err, req, res, next) {
console.error(err.stack);
res.status(401).send('未经授权的访问');
});
app.listen(3000, () => {
console.log('服务器已启动,监听端口 3000');
});
在上面的示例中,我们定义了一个名为 checkUser 的函数,用于验证用户提供的用户名和密码。如果用户名和密码正确,则返回 true;否则返回 false。
然后,我们使用 express.basicAuth 中间件来保护 /protected 路由。这样,当用户尝试访问该路由时,Express 会调用 checkUser 函数来验证用户名和密码。如果用户名和密码正确,Express 会继续执行后续的处理函数;否则,Express 会调用错误处理中间件并向客户端发送一个状态码为 401 的响应,以及消息"未经授权的访问"。
通过使用 express.basicAuth 中间件,我们可以很容易地保护需要身份验证的路由,并控制哪些用户有权访问受保护的资源。请注意,express.basicAuth 中间件并不是最安全的身份验证方式,因为它使用的是基本认证协议,其中的用户名和密码是以明文形式传输的。因此,在生产环境中,建议使用更安全的身份验证方式,如 OAuth2 等。
29.2.7 bodyParser
Express.js 4.x 中已经将 express.bodyParser 移除,并将其拆分成了几个单独的中间件,例如 express.json、express.urlencoded 等。
29.2.8 compress
用于对响应数据进行压缩,以减小传输大小并提高网络性能。它基于 Node.js 内置的 zlib 模块实现了对响应数据的压缩。
在 Express.js 4.x 版本之后,express.compress 中间件已经被弃用,推荐使用更为灵活的 compression 中间件来实现对响应数据的压缩。
安装 compression
npm install compression
下面是一个示例代码,展示如何在 Express 中使用 compression 中间件来压缩响应数据:
const express = require('express');
const compression = require('compression');
const app = express();
// 使用 compression 中间件来压缩响应数据
app.use(compression());
// 处理请求的路由
app.get('/', function(req, res) {
res.send('Hello, world!');
});
app.listen(3000, () => {
console.log('服务器已启动,监听端口 3000');
});
在上面的示例中,我们首先通过 require('compression') 引入了 compression 中间件。然后,使用 app.use(compression()) 将它作为全局中间件添加到 Express 应用中。
这样,当客户端发送请求时,compression 中间件会自动检查响应数据的大小,并根据需要对其进行压缩。压缩后的数据会通过 Content-Encoding 头部字段告知客户端。客户端在接收到压缩的响应数据后会自动解压缩,并正确显示内容。
通过使用 compression 中间件,我们可以轻松地实现对响应数据的压缩,提高网络传输效率,减小带宽占用。
29.2.9 directory
用于将指定目录下的文件列出并展示在浏览器中,类似于 Apache 服务器的目录列表功能。
在 Express.js 4.x 版本之后,express.directory 中间件已经被弃用,不再建议使用。如果需要实现类似的功能,可以使用第三方模块 serve-index 来实现。
安装 serve-index
npm install serve-index
下面是一个示例代码,展示如何在 Express 中使用 serve-index 模块来实现目录列表功能:
const express = require('express');
const serveIndex = require('serve-index');
const app = express();
// 将 public 目录下的文件列出并展示在浏览器中
app.use(express.static('public'));
app.use(serveIndex('public', { 'icons': true }));
app.listen(3000, () => {
console.log('服务器已启动,监听端口 3000');
});
在上面的示例中,我们首先通过 require('serve-index') 引入了 serve-index 模块。然后,使用 app.use(serveIndex('public', { 'icons': true })) 将它作为中间件添加到 Express 应用中。
这样,当客户端发送请求时,serve-index 中间件会自动检查请求路径是否是一个目录,并将该目录下的文件列出并展示在浏览器中。icons: true 参数表示展示文件图标,可以根据实际需求进行调整。
通过使用 serve-index 模块,我们可以轻松地实现 Apache 服务器的目录列表功能,并提供给用户方便的文件浏览和下载功能。
29.2.10 favicon
用于设置网站的 favicon(收藏夹图标)。
在 Express.js 4.x 版本之后,express.favicon 中间件已经被弃用,推荐使用更为灵活的 serve-favicon 中间件来实现设置 favicon 的功能。
安装 server-favicon
npm install server-favicon
下面是一个示例代码,展示如何在 Express 中使用 serve-favicon 中间件来设置网站的 favicon:
const express = require('express');
const favicon = require('serve-favicon');
const path = require('path');
const app = express();
// 设置 favicon
app.use(favicon(path.join(__dirname, 'public', 'favicon.ico')));
// 处理请求的路由
app.get('/', function(req, res) {
res.send('Hello, world!');
});
app.listen(3000, () => {
console.log('服务器已启动,监听端口 3000');
});
在上面的示例中,我们首先通过 require('serve-favicon') 引入了 serve-favicon 中间件。然后,使用 app.use(favicon(path.join(__dirname, 'public', 'favicon.ico')))
将它作为中间件添加到 Express 应用中。
通过 path.join(__dirname, 'public', 'favicon.ico') 的方式指定了 favicon 文件的路径。你需要将 favicon.ico 文件放置在 public 目录下,然后使用正确的文件名和路径来设置 favicon。
这样,当客户端访问网站时,serve-favicon 中间件会自动将 favicon.ico 图标发送给客户端,并在浏览器中显示为网站的 favicon。
通过使用 serve-favicon 中间件,我们可以轻松地设置网站的 favicon,提升用户体验和品牌识别度。
29.2.11 session
用于在应用中启用会话管理功能。会话(Session)是一种在服务器端存储和跟踪用户状态的机制,用于在多个请求之间保持用户的状态信息。
自 Express.js 4.x 版本起,express.session 中间件已经被弃用,并且官方推荐使用更为强大和灵活的第三方模块 express-session 来实现会话管理功能。因此,建议使用 express-session 模块来处理会话。
安装 express-session
npm install express-session
下面是一个示例代码,展示如何在 Express 中使用 express-session 模块来启用会话管理功能:
const express = require('express');
const session = require('express-session');
const app = express();
// 使用 express-session 中间件来处理会话
app.use(session({
secret: 'mysecret',
resave: false,
saveUninitialized: true
}));
// 处理请求的路由
app.get('/', function(req, res) {
// 设置会话数据
req.session.username = 'JohnDoe';
// 获取会话数据
const username = req.session.username;
res.send(`Hello, ${username}!`);
});
app.listen(3000, () => {
console.log('服务器已启动,监听端口 3000');
});
在上面的示例中,我们首先通过 require('express-session') 引入了 express-session 模块。然后,使用 app.use(session({...})) 将它作为中间件添加到 Express 应用中。
在 session({...}) 的配置中,我们可以设置一些选项来满足实际需求。示例中的选项包括:
- secret:用于对会话数据进行加密的密钥。
- resave:是否在每次请求时重新保存会话数据,默认为
false。 - saveUninitialized:是否自动初始化未经授权的会话,默认为
true。
通过使用 express-session 模块,我们可以轻松地启用会话管理功能,并在会话中存储和跟踪用户状态信息。这样,我们就能够在多个请求之间保持用户的登录状态、购物车内容等。
29.2.12 methodOverride
用于支持 HTTP 方法的重写和模拟。它允许客户端通过发送特定的请求头或查询参数来模拟其他 HTTP 方法,以便在不支持该方法的环境中执行相应的操作。
在 Express.js 4.x 版本之后,express.methodOverride 中间件已经被弃用,并且不再是 Express.js 的官方中间件。取而代之的是使用 method-override 模块来实现类似的功能。
HTTP 协议中定义了多种请求方法,如 GET、POST、PUT、DELETE 等。然而,某些客户端(如一些旧版浏览器或 HTML 表单)只支持 GET 和 POST 请求方法。为了解决这个问题,method-override 中间件可以帮助我们在这些客户端上模拟使用 PUT、DELETE 等其他请求方法。
安装 method-override
npm install method-override
下面是一个示例代码,展示如何在 Express 中使用 method-override 模块来支持 HTTP 方法的重写和模拟:
const express = require('express');
const methodOverride = require('method-override');
const app = express();
// 使用 method-override 中间件来处理 HTTP 方法重写
app.use(methodOverride('_method'));
// 处理 POST 请求并将其重写为指定的 HTTP 方法
app.post('/resource', function(req, res) {
// 根据 _method 查询参数的值来判断要执行的操作
if (req.query._method === 'delete') {
// 执行删除操作
} else if (req.query._method === 'put') {
// 执行更新操作
}
res.send('操作成功!');
});
app.listen(3000, () => {
console.log('服务器已启动,监听端口 3000');
});
在上面的示例中,我们首先通过 require('method-override') 引入了 method-override 模块。然后,使用 app.use(methodOverride('_method')) 将它作为中间件添加到 Express 应用中。
在 methodOverride('_method') 中,我们传递了一个参数 _method,指定了用于模拟其他 HTTP 方法的查询参数的名称。默认情况下,method-override 模块会检查请求头中的 X-HTTP-Method-Override 字段来获取要模拟的方法。
通过在请求的查询字符串或表单中添加 _method 字段并指定相应的请求方法(如 _method=PUT 或 _method=DELETE),method-override 中间件会将这些方法解析为对应的请求方法。
在处理 POST 请求时,我们可以通过在请求的查询参数中添加 _method 参数来模拟其他 HTTP 方法。根据 _method 的值,我们可以执行相应的操作,例如删除或更新资源。
通过使用 method-override 模块,我们可以轻松地支持 HTTP 方法的重写和模拟,从而使我们能够在不支持某些 HTTP 方法的环境中执行相应的操作。
29.2.13 responseTime
用于计算请求响应时间。它会在响应头中添加一个 X-Response-Time 字段,该字段表示服务器处理请求并生成响应的时间。
下面是一个示例代码,展示如何在 Express 中使用 express.responseTime 中间件来计算请求的响应时间:
const express = require('express');
const responseTime = require('response-time');
const app = express();
// 使用 response-time 中间件来计算响应时间
app.use(responseTime());
// 处理请求的路由
app.get('/', function(req, res) {
res.send('Hello World!');
});
app.listen(3000, () => {
console.log('服务器已启动,监听端口 3000');
});
在上面的示例中,我们首先通过 require('response-time') 引入了 response-time 模块。然后,使用 app.use(responseTime()) 将它作为中间件添加到 Express 应用中。
通过添加 responseTime() 中间件,Express 将自动计算每个请求的响应时间,并在响应头中添加一个 X-Response-Time 字段。该字段的值表示服务器处理请求并生成响应的时间,单位为毫秒。
使用 express.responseTime 中间件可以很方便地记录请求的响应时间,以便进行性能监控和优化。
29.2.14 logger
用于记录请求和响应的详细信息,例如 请求方法、请求 URL、响应状态码、响应时间等。它可以帮助开发者更好地了解应用程序的运行情况,以便进行性能监控和错误排查。
安装 Morgan
npm install morgan
日志格式
Morgan 提供了不同的日志格式选项,包括预定义的标准格式(如 'combined'、'common'、'short'、'tiny'、'dev' 等),也可以自定义日志格式。例如:
-
combined:标准 Apache combined 日志格式,包括客户端 IP 地址、日期、请求方法、请求 URL、HTTP 协议、响应状态码、响应体大小、来源 URL、用户代理等信息。示例:
127.0.0.1 - john [10/Oct/2022:13:55:36 +0000] "GET /api/users HTTP/1.1" 200 1234 "http://localhost:3000/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36" -
common:标准 Apache common 日志格式,与
combined格式相比不包括来源 URL 和用户代理信息。示例:127.0.0.1 - john [10/Oct/2022:13:55:36 +0000] "GET /api/users HTTP/1.1" 200 1234 -
dev:简洁易读的开发环境日志格式,包括请求方法、请求 URL、响应状态码、响应时间、响应体大小和来源 URL 等信息。示例:
GET /api/users 200 1234 - 5ms -
short:简洁的日志格式,只包括请求方法、请求 URL、响应状态码、响应时间和响应体大小。示例:
GET /api/users 200 1234 - 5ms -
tiny:超级精简的日志格式,只包括请求方法、请求 URL 和响应状态码。示例:
GET /api/users 200
app.use(logger('combined'));
自定义日志格式
开发者还可以通过自定义日志格式字符串来记录所需的信息,常用的占位符有:
-
:date[format]:输出当前日期和时间,可选的
format参数表示日期格式,默认为 ISO 格式。 -
:remote-addr:输出客户端 IP 地址。
-
:method:输出 HTTP 请求方法,例如 GET、POST 等。
-
:url:输出请求 URL。
-
:http-version:输出 HTTP 协议版本,例如 HTTP/1.1。
-
:status:输出响应状态码,例如
200、404等。 -
:response-time:输出响应时间,单位为毫秒。
-
:res[header-name]:输出响应头中指定的字段值,例如:
res[content-length]、:res[x-custom-header]。 -
:referrer:输出来源 URL。
-
:user-agent:输出用户代理信息。
例如:
app.use(logger(':date[web] :method :url :status :response-time ms - :res[content-length]'));
支持的日志格式变量
Morgan 支持一系列的日志格式变量,如 :date、:method、:url、:status、:response-time 等,你可以根据需要组合这些变量来满足特定的日志记录需求。
使用 express.logger 中间件可以方便地记录每个请求和响应的详细信息,以及它们的处理时间和状态。下面是一个示例代码,展示如何在 Express 中使用 express.logger 中间件来记录请求和响应的详细信息:
const express = require('express');
const logger = require('morgan');
const app = express();
// 使用 morgan 中间件来记录请求和响应的详细信息
app.use(logger('dev'));
// 处理请求的路由
app.get('/', function(req, res) {
res.send('Hello World!');
});
app.listen(3000, () => {
console.log('服务器已启动,监听端口 3000');
});
在上面的示例中,我们首先通过 require('morgan') 引入了 morgan 模块。然后,使用 app.use(logger('dev')) 将它作为中间件添加到 Express 应用中。
通过添加 logger('dev') 中间件,Express 将自动记录每个请求和响应的详细信息,并将其输出到控制台。'dev' 参数表示使用开发环境的日志格式,它会记录请求方法、请求 URL、响应状态码、响应时间等信息。
使用 express.logger 中间件可以方便地记录每个请求和响应的详细信息,以及它们的处理时间和状态。这对于应用程序的性能监控和错误排查非常有帮助。
29.2.15 limit
用于限制请求的有效载荷大小(payload size)。
从 Express.js 4.x 版本开始,express.limit 中间件被移除,取而代之的是使用更加灵活的 body-parser 中间件来处理请求的有效载荷大小限制。现在,可以使用 body-parser 中间件的 limit 选项来设置请求的有效载荷大小限制。
安装 body-parser
npm install body-parser`
以下是一个示例,演示如何使用 body-parser 中间件来设置请求有效载荷大小的限制:
const express = require('express');
const bodyParser = require('body-parser');
const app = express();
// 使用 body-parser 中间件,并设置有效载荷大小的限制为 10MB
app.use(bodyParser.json({ limit: '10MB' }));
// 处理请求的路由
app.post('/api/data', function(req, res) {
// 处理请求数据
});
app.listen(3000, () => {
console.log('服务器已启动,监听端口 3000');
});
在上面的示例中,我们通过 require('body-parser') 引入了 body-parser 模块,并使用 app.use(bodyParser.json({ limit: '10MB' })) 将它作为中间件添加到 Express 应用中。在这里,我们设置了请求的有效载荷大小限制为 10MB。
使用 body-parser 中间件的 limit 选项可以灵活地设置请求的有效载荷大小限制,以满足实际需求。可以将大小限制设置为一个字节数(如 '1024')、一个带单位的字符串(如 '1kb'、'10MB')或者一个函数来动态计算限制。
29.2.16 errorHandler
捕获和处理应用中的错误,以便向客户端发送错误响应或执行其他自定义的错误处理逻辑。该中间件函数会拦截应用中的错误,并将错误信息作为响应发送给客户端。
然而,从 Express.js 4.x 版本开始,express.errorHandler 中间件已被移除,并且不再建议使用。取而代之的是使用更加灵活的错误处理机制,其中包括使用中间件函数来处理错误。
以下是一个示例,演示如何使用自定义的错误处理中间件来替代 express.errorHandler:
const express = require('express');
const app = express();
// 定义错误处理中间件
function errorHandler(err, req, res, next) {
// 处理错误逻辑
console.error(err);
res.status(500).send('Internal Server Error');
}
// 在其他路由之后添加错误处理中间件
app.get('/api/users', function(req, res, next) {
// 业务逻辑
// 如果发生错误,调用 next() 并传递错误对象
next(new Error('Something went wrong'));
});
// 添加错误处理中间件
app.use(errorHandler);
app.listen(3000, () => {
console.log('服务器已启动,监听端口 3000');
});
在上面的示例中,我们首先定义了一个自定义的错误处理中间件函数 errorHandler。该函数接收四个参数:错误对象(err)、请求对象(req)、响应对象(res)和下一个中间件函数(next)。在这里,我们简单地将错误信息打印到控制台,并向客户端发送 500 错误响应。
然后,我们在其他路由处理程序之后使用 app.use(errorHandler) 向 Express 应用添加错误处理中间件。这样,当发生错误时,Express 将自动调用该中间件并传递错误对象。
通过使用自定义的错误处理中间件,我们可以更加灵活地处理应用中的错误,包括记录日志、发送错误响应、执行特定的错误处理逻辑等。
需要注意的是,在使用自定义的错误处理中间件时,要确保在其他路由处理程序之后添加它,以便能够捕获到所有的错误。
总结来说,express.errorHandler 是一个已弃用的中间件函数,用于处理 Express 应用中的错误。在新版本的 Express 中,建议使用自定义的错误处理中间件来替代它,以实现更加灵活和可定制的错误处理机制。
29.2.17 csrf
express.csrf 是一个中间件函数,用于提供 CSRF(跨站请求伪造)保护。
CSRF 是一种攻击方式,攻击者利用用户已经认证的身份执行非意愿的操作。为了防止 CSRF 攻击,应用程序需要在每个请求中验证请求源和身份验证标记(CSRF 令牌)。express.csrf 中间件帮助我们实现这种 CSRF 保护。
以下是一个示例,演示如何使用 express.csrf 中间件来设置 CSRF 令牌和验证 CSRF 令牌:
const express = require('express');
const csrf = require('csurf');
const cookieParser = require('cookie-parser');
const app = express();
// 使用 cookieParser 中间件解析请求中的 cookie
app.use(cookieParser());
// 使用 csrf 中间件设置和验证 CSRF 令牌
app.use(csrf({ cookie: true }));
// 添加自定义的中间件来处理 CSRF 错误
app.use(function(err, req, res, next) {
if (err && err.code === 'EBADCSRFTOKEN') {
// 处理 CSRF 错误逻辑
res.status(403).send('Invalid CSRF Token');
} else {
next(err);
}
});
// 在路由处理程序中添加 CSRF 令牌
app.get('/api/users', function(req, res) {
// 获取 CSRF 令牌
const csrfToken = req.csrfToken();
// 其他业务逻辑
res.json({ csrfToken });
});
app.listen(3000, () => {
console.log('服务器已启动,监听端口 3000');
});
在上面的示例中,我们首先通过 require('csurf') 引入了 csurf 模块,并使用 app.use(csrf({ cookie: true })) 将其作为中间件添加到 Express 应用中。这样,express.csrf 中间件会设置和验证 CSRF 令牌,并将令牌存储在请求对象的 csrfToken() 方法中。
然后,我们定义了一个自定义的错误处理中间件,用于处理 CSRF 错误。如果发生 CSRF 错误,即请求中的 CSRF 令牌无效或缺失,该中间件会发送一个 403 错误响应。
在路由处理程序中,我们可以通过调用 req.csrfToken() 方法获取当前请求的 CSRF 令牌,并将令牌发送给客户端。
需要注意的是,在使用 express.csrf 中间件之前,请确保通过 npm install csurf cookie-parser 命令安装了相应的模块。
中间件是 Express.js 中非常重要的概念,它提供了一种灵活的方式来处理请求和响应,并允许开发人员构建功能强大的 Web 应用程序。通过正确使用中间件,可以实现代码复用、模块化和可维护性的提高。
总结
Express 中间件是在请求与响应之间执行的函数,用于处理请求、修改响应或执行其他任务。以下是对 Express 中间件的总结:
-
中间件是函数:Express 中间件是一个函数,它可以接收请求对象(
req)、响应对象(res)和下一个中间件函数(next)作为参数。开发者可以编写自己的中间件函数,也可以使用第三方中间件。 -
顺序执行:Express中间件按照定义的顺序依次执行。可以通过多次调用
app.use方法或app.METHOD方法来定义多个中间件。一旦一个中间件调用了next函数,控制权将传递给下一个中间件,如果没有调用next函数,则请求处理过程将终止。 -
内置中间件:Express 框架内置了一些常用的中间件,如静态文件服务中间件(
express.static)、解析JSON请求体中间件(express.json)和解析URL编码的请求体中间件(express.urlencoded)等。这些中间件可以通过调用app.use方法来使用。 -
自定义中间件:开发者可以编写自己的中间件来满足特定的需求。自定义中间件函数可以用于请求预处理、身份验证、日志记录等任务。通过使用
app.use方法或app.METHOD方法来定义自定义中间件。 -
第三方中间件:Express 拥有庞大的第三方中间件生态系统,开发者可以使用这些中间件来扩展 Express 的功能。常见的第三方中间件包括身份验证中间件(如
passport)、表单解析中间件(如body-parser)和日志记录中间件(如morgan)等。 -
错误处理中间件:Express 中的错误处理中间件用于捕获和处理应用程序中的错误。它们通常带有四个参数:错误对象(
err)、请求对象(req)、响应对象(res)和下一个中间件函数(next)。通过定义错误处理中间件,可以集中处理应用程序中的各种错误情况。
Express 中间件是一个强大且灵活的机制,可以用于处理请求、修改响应、实现权限控制等各种任务。合理地使用中间件可以提高代码的可复用性、可测试性和可维护性,并简化开发过程。无论是使用内置中间件、自定义中间件还是第三方中间件,都能够为 Express 应用程序增加功能和扩展性。
30-页面渲染与模板引擎
模板引擎是一种将数据和静态模板结合起来生成最终 HTML 页面的工具。使用模板引擎可以让你更加方便地管理动态内容,将业务逻辑和视图分离,提高代码的可维护性和重用性。
通常情况下,一个模板引擎会定义一些特殊的标记或语法,用于插入动态数据、控制流程等操作。在渲染过程中,模板引擎会根据传递给它的数据和模板文件生成最终的 HTML 页面。
30.1 使用模板引擎(如Pug、EJS)渲染页面
常见的模板引擎有 EJS、Pug(之前称为 Jade)、Handlebars、Mustache 等。每种模板引擎都有自己的优点和适用场景,你可以根据自己的需求选择合适的模板引擎,并按照相应的文档配置和使用它们。
在 Express 中,你可以使用模板引擎来渲染动态的 HTML 页面,从而生成响应并发送给客户端。Express 提供了许多支持各种模板引擎的插件和库,你可以使用它们来快速集成模板引擎到自己的项目中。
30.1.2 Pug
Pug(原名Jade)是一个高性能、易于使用的模板引擎。它的主要特点是简洁、灵活,并且支持嵌套式标签,可以轻松地创建复杂的 HTML 结构。在使用 Pug 时,你可以省略大部分的 HTML 标签和属性,直接使用缩进和类似 Python 的语法来描述页面结构和内容。
安装和配置 Pug
使用 npm 安装 pug 包。
npm install pug
在 Express 应用程序中设置模板引擎和视图文件夹。比如:
-
app.set(‘view engine’, ‘pug’):设置视图引擎为
Pug,这样在渲染视图时就会使用Pug引擎来解析视图文件; -
app.set(‘views’, ‘./views’):设置视图文件夹的路径为当前目录下的
views文件夹,这个文件夹中存放了所有的视图文件,比如index.pug、about.pug等。
const express = require('express');
const app = express();
app.set('view engine', 'pug');
app.set('views', './views');
使用 Pug 模板
- 创建一个
.pug文件,写入Pug语法来描述 HTML 页面。 - 在 Express 路由处理函数中,使用
res.render()方法将数据传入模板进行渲染。 - 在模板中使用
Pug语法和变量等,来展示动态的 HTML 页面。例如:
html
head
title= title
body
h1= message
ul
each fruit in fruits
li= fruit
Pug 语法
Pug 是一种简洁、灵活的模板引擎,采用缩进来组织 HTML 结构,使用类似于 Python 的语法。以下是一些常用的 Pug 语法:
-
标签和属性
- 使用标签名创建 HTML 元素。例如,
h1表示标题。 - 在标签后面使用小括号
()来添加属性,如a(href='https://example.com')。
// 使用标签名创建 HTML 元素 h1 标题 // 在标签后面使用小括号 () 来添加属性 a(href='https://example.com') 链接 - 使用标签名创建 HTML 元素。例如,
-
文本
- 直接在行内写文本内容,或者使用
|或.进行文本块缩进。 - 可以使用
#{}语法来插入变量,如p Hello, #{name}!。
// 在行内写文本内容 p Hello, Pug! // 使用 | 或 . 进行文本块缩进 p | 这是一段 | 多行文本 - 直接在行内写文本内容,或者使用
-
注释
- 使用
//进行单行注释。 - 使用
//-进行块级注释。
// 单行注释 pug 是一种简洁、灵活的模板引擎 //- 块级注释 // 这里是一个块级注释 - 使用
-
变量
-
变量赋值
使用
-符号定义并赋值一个变量, 使用=符号进行赋值:- var name = 'Alice' - let age = 20 -
对象和数组
可以直接引用对象和数组中的属性和元素:
- var user = { name: 'Alice', age: 20 } p Name: #{user.name}, Age: #{user.age} - var fruits = ['Apple', 'Banana', 'Orange'] each fruit in fruits p #{fruit} -
变量/表达式插入
使用
#{}来插入任意 JavaScript 表达式的结果:// 使用 #{变量名} 语法来插入变量 p Hello, #{name}! // 表达式插值 p The sum of 1 and 2 is #{1 + 2}
-
-
条件语句
- 使用
if、else if和else来构建条件语句块。 - 使用
unless来表示条件的反义。 - 可以使用
case和when来进行多分支判断
- if user.loggedIn p Welcome back, #{user.name}! - else p Please log in. - 使用
-
循环
- 使用
each item in items对数组进行循环。 - 可以使用
each value, key in object对对象进行循环。
ul each fruit in fruits li= fruit - 使用
-
函数
-
函数定义
使用
-符号定义一个函数,并且可以在函数内部执行任意的 JavaScript 代码:- function double(num) { - return num * 2; - } - var result = double(5); p The result is #{result}. -
函数插入
使用
#{}语法将函数的返回值插入到标签或文本中:- function capitalize(str) { - return str.charAt(0).toUpperCase() + str.slice(1); - } p Hello, #{capitalize('world')}! -
内置函数
Pug还提供了一些内置函数,可以直接在模板中使用:p The current date is #{new Date().toLocaleDateString()}. -
块级函数
也可以定义块级函数,在某个块中进行调用:
block appendScripts - function loadScript(url) { script(src=url) - } extends layout appendScripts loadScript('/js/main.js')
-
-
过滤器
- 使用
:filter来应用过滤器,如:markdown来处理Markdown文本。 - 可以使用
:stylus、:less、:scss等过滤器来处理对应的文本。
:markdown # Hello, World! This is **Markdown**. - 使用
-
块
- 使用
block和extends来定义和使用块。 - 块是一种在模板中定义的可重用的代码片段。
// 定义块 block content p This is the default content for the block. // 使用块 extends layout.pug block content p This is the overridden content for the block. - 使用
-
继承
- 使用
extends和block来实现模板的继承和重写。
// layout.pug html head title My Website body block content // page.pug extends layout.pug block content p Welcome to my website! - 使用
-
导入
使用
include来导入其他模板文件。include header.pug include footer.pug
这只是 Pug 语法的一部分,Pug 还有更多强大的功能,如 mixin(混合)等。你可以参考 Pug 的官方文档来深入了解更多关于 Pug 语法的内容。
pug生成模版引擎案例
下面是一个使用 Pug 生成的模板引擎的示例:
-
创建一个名为
index.pug的 Pug 模板文件,内容如下:html head title My Pug Page link(rel='stylesheet', href='/styles.css') body div.container h1 Welcome to my website! p#intro My name is #{name}, and this is my website. ul#menu li.active Home li About li Contact -
创建一个名为
styles.css的 CSS 文件,内容如下:.container { max-width: 800px; margin: 0 auto; padding: 20px; } h1 { font-size: 36px; color: #333; } #intro { font-size: 18px; color: #666; } ul#menu { list-style: none; margin: 20px 0; padding: 0; } ul#menu li { display: inline-block; margin-right: 20px; font-size: 16px; color: #999; } ul#menu li.active { color: #333; font-weight: bold; } -
在终端中进入项目目录,运行
npm init -y命令初始化项目,然后运行npm install express pug安装 Express 和 Pug 模块。 -
创建一个名为
index.js的Node.js文件,内容如下:const express = require('express'); const app = express(); const path = require('path'); // 设置 Pug 模板引擎 app.set('view engine', 'pug'); app.set('views', path.join(__dirname, 'views')); // 静态文件服务 app.use(express.static(path.join(__dirname, 'public'))); // 渲染 Pug 模板 app.get('/', (req, res) => { res.render('index', { name: 'John' }); }); // 启动服务器 app.listen(3000, () => { console.log('Server started on port 3000.'); });在上述示例中,我们通过 Express 框架设置了 Pug 模板引擎,并将模板文件放在项目根目录下的
views文件夹中。我们还在public文件夹中创建了一个名为styles.css的 CSS 文件,并使用express.static中间件来启用静态文件服务。 -
在终端中运行
node index.js命令启动服务器,然后在浏览器中打开http://localhost:3000,即可看到生成的 HTML 页面。
生成的 HTML 页面将包含以下内容:
<!DOCTYPE html>
<html>
<head>
<title>My Pug Page</title>
<link rel="stylesheet" href="/styles.css">
</head>
<body>
<div class="container">
<h1>Welcome to my website!</h1>
<p id="intro">My name is John, and this is my website.</p>
<ul id="menu">
<li class="active">Home</li>
<li>About</li>
<li>Contact</li>
</ul>
</div>
</body>
</html>
在上述示例中,我们定义了一个包含标题、段落和菜单的 Pug 模板文件,并在 head 标签中引用了外部的 CSS 样式表文件。我们还定义了一个名为 container 的 CSS 类样式,设置了页面的最大宽度和内边距。通过在元素名称后面添加井号(#)和类名或 ID 名称,我们可以为元素指定样式。
通过使用 Pug 的模板引擎和 CSS 样式,我们可以更加灵活和高效地生成动态的 HTML 内容,并为这些内容添加漂亮的样式。
30.1.2 EJS
EJS(Embedded JavaScript)是一种基于 JavaScript 的模版引擎,它可以在服务器端和客户端使用。EJS 提供了一种简单、灵活和可定制的方式来生成 HTML 页面,它允许开发人员使用 JavaScript 代码在 HTML 模板中插入动态内容。
以下是 EJS 的主要特点:
-
简单易学:EJS 的语法非常简单和易于学习。它类似于 HTML,但也支持嵌入 JavaScript 代码。
-
灵活性高:EJS 具有很高的灵活性,可以轻松地处理各种复杂的逻辑和动态内容生成需求。它提供了一些常用的控制结构,例如 if/else 语句、循环、函数等,同时还支持自定义标签和过滤器。
-
可定制性强:EJS 支持自定义标签和过滤器,从而可以根据开发人员的具体需求来扩展其功能。
-
支持客户端和服务器端渲染:EJS 可以在服务器端和客户端使用,这使得它非常灵活,并且可以根据需要选择适当的渲染方式。
-
高性能:EJS 的性能非常出色,它具有很快的编译和执行速度,并且可以通过缓存来进一步提高性能。
以下是使用 EJS 的基本步骤:
安装 EJS
可以通过 npm 包管理器在项目中安装 EJS。打开终端并执行以下命令:
npm install ejs
模板文件
创建模板文件:创建一个以 .ejs 扩展名结尾的模板文件。例如,创建一个名为 index.ejs 的文件。
编写模板文件:在模板文件中,可以使用标签 <% %> 来插入 JavaScript 代码,用于控制页面逻辑和生成动态内容。同时,可以使用 <%= %> 标签来输出变量的值到 HTML 页面中。
<html>
<head>
<title>My EJS Page</title>
</head>
<body>
<h1>Welcome to <%= name %>'s website!</h1>
<% if (isAdmin) { %>
<p>You have admin privileges.</p>
<% } else { %>
<p>You do not have admin privileges.</p>
<% } %>
</body>
</html>
在 Node.js 中渲染模板:通过引入 EJS 模块,读取模板文件。通过调用 res.render 方法,我们将模板文件和数据传递给 Express,并将模板与数据进行渲染,从而生成最终的 HTML 页面。
EJS语法
当使用 EJS(Embedded JavaScript)模板引擎时,你可以在 HTML 文件中嵌入 JavaScript 代码。以下是 EJS 的详细语法介绍:
-
输出变量值:
使用
<%= %>标签来输出变量的值到 HTML 页面中。<p>My name is <%= name %></p> -
执行 JavaScript 代码:
使用
<% %>标签来执行任意的 JavaScript 代码,可以用于控制页面逻辑和生成动态内容。<% if (isAdmin) { %> <p>Welcome, admin!</p> <% } else { %> <p>Welcome, guest!</p> <% } %> -
注释:
使用
<%# %>标签来添加注释,注释内容将不会被渲染到最终的 HTML 页面中。<%# This is a comment %> -
条件语句:
使用
<% if (condition) { %> 和 <% } %>标签来创建条件语句。<% if (isAdmin) { %> <p>You have admin privileges.</p> <% } else { %> <p>You do not have admin privileges.</p> <% } %> -
循环语句
使用
<% for (var i = 0; i < array.length; i++) { %> 和 <% } %>标签来创建循环结构,遍历数组并输出其中的内容。<ul> <% for (var i = 0; i < users.length; i++) { %> <li>Name: <%= users[i].name %>, Age: <%= users[i].age %></li> <% } %> </ul> -
引入外部模板
使用
<%- include('templateName') %>标签来引入外部的EJS模板文件。<div> <%- include('header') %> <h1>Welcome to my website!</h1> <%- include('footer') %> </div>
我们可以看出 EJS 的语法更加的简洁,也更符合我们的代码编写习惯。你用这些语法来灵活地控制页面逻辑、生成动态内容和引入外部模板。EJS 提供了一种简单、灵活且易于学习的方式来生成 HTML 页面。
EJS模版案例
以下是一个使用 Express 和 EJS 生成的模板引擎示例:
首先,确保你已经安装了 Node.js 和 Express 框架。然后执行以下步骤:
-
创建一个名为
app.js的文件,并输入以下内容:// 导入所需的模块 const express = require('express'); const path = require('path'); // 创建 Express 应用 const app = express(); // 设置视图引擎为 EJS app.set('view engine', 'ejs'); // 设置静态文件目录为 public app.use(express.static(path.join(__dirname, 'public'))); // 定义路由 app.get('/', (req, res) => { // 渲染 index.ejs 模板,并传递动态数据 res.render('index', { title: 'My Page', heading: 'Welcome to my website!', content: 'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Donec non justo id nisl posuere tincidunt. Fusce euismod eget ante at dignissim. Sed vel gravida nunc, vitae blandit nibh.' }); }); // 启动服务器 const port = 3000; app.listen(port, () => { console.log(`Server is running on http://localhost:${port}`); }); -
在项目根目录下创建一个名为
views的文件夹,并在其中创建一个名为index.ejs的文件:<!DOCTYPE html> <html> <head> <title><%= title %></title> <link rel="stylesheet" type="text/css" href="/styles.css"> </head> <body> <div class="container"> <h1><%= heading %></h1> <p><%= content %></p> </div> </body> </html> -
在项目根目录下创建一个名为
public的文件夹,并在其中创建一个名为styles.css的文件,添加一些样式:body { font-family: Arial, sans-serif; background-color: #f7f7f7; } .container { max-width: 800px; margin: 20px auto; padding: 20px; background-color: #fff; border-radius: 5px; box-shadow: 0 2px 4px rgba(0, 0, 0, 0.3); } h1 { color: #333; } p { color: #666; line-height: 1.6; } -
运行
node app.js启动服务器。
现在,当你访问 http://localhost:3000/ 时,Express 将会渲染 index.ejs 模板并生成 HTML 页面。
以下是生成的 HTML 页面示例:
<!DOCTYPE html>
<html>
<head>
<title>My Page</title>
<link rel="stylesheet" type="text/css" href="/styles.css">
</head>
<body>
<div class="container">
<h1>Welcome to my website!</h1>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Donec non justo id nisl posuere tincidunt. Fusce euismod eget ante at dignissim. Sed vel gravida nunc, vitae blandit nibh.</p>
</div>
</body>
</html>
在上面的示例中,我们可以看到生成的 HTML 文件包含了与模板定义相同的 CSS 样式,并且动态内容也被正确地插入到了对应的位置。
30.2 动态数据展示和表单处理
当使用 Express 和模板引擎(比如 EJS)时,可以很容易地展示动态数据,并处理表单提交。以下是一个简单的示例,演示如何展示动态数据并处理表单:
30.2.1 展示动态数据
-
创建一个新的 EJS 模板文件(比如
index.ejs),用于展示动态数据:<!DOCTYPE html> <html> <head> <title><%= title %></title> </head> <body> <h1>Welcome to <%= title %>!</h1> <p><%= content %></p> </body> </html> -
在 Express 应用中设置路由,渲染该模板并传递动态数据:
app.get('/', (req, res) => { const data = { title: 'My Page', content: 'This is some dynamic content!' }; res.render('index', data); });
2.2 处理表单提交
-
创建一个包含表单的 EJS 模板文件(比如
form.ejs):<!DOCTYPE html> <html> <head> <title>Form Example</title> </head> <body> <form action="/submit" method="post"> <label for="name">Name:</label> <input type="text" id="name" name="name"> <button type="submit">Submit</button> </form> </body> </html> -
设置 Express 应用的 GET 路由,用于渲染该表单:
app.get('/form', (req, res) => { res.render('form'); }); -
设置 Express 应用的 POST 路由,用于处理表单提交:
app.post('/submit', (req, res) => { const name = req.body.name; res.send(`Submitted name: ${name}`); });
注意:确保在 Express 应用中使用 body-parser 中间件来解析表单数据:
const bodyParser = require('body-parser');
app.use(bodyParser.urlencoded({ extended: true }));
通过以上操作,你就可以成功展示动态数据和处理表单提交了。
总结
当使用 Node.js 构建web应用程序时,页面渲染和模板引擎是常见的技术。
页面渲染是将服务器端数据动态地呈现为HTML页面的过程。这种动态生成的HTML页面可以包含从数据库中检索的数据、用户输入的数据和其他服务器端计算生成的内容。
模板引擎是一种工具,它允许你使用特定语法和标记来定义和组织HTML页面的结构和内容。模板引擎能够将模板和数据合并在一起,生成最终的HTML输出。
31-用户认证与授权
用户认证和授权是构建安全的 Web 应用程序的重要组成部分。认证是验证用户身份的过程,而授权是确定用户是否有权访问特定资源或执行特定操作的过程。
31.1 实现用户认证和授权功能
在 Web 应用中,常见的身份验证方法包括用户名和密码、OAuth、OpenID Connect 等。其中,用户名和密码是最基本的认证方式,而 OAuth 和 OpenID Connect 则是常用的第三方认证协议,可以让你的应用程序与其他应用程序进行安全地交互。
在实现用户认证和授权时,通常需要遵循以下步骤:
-
验证用户的身份:在用户请求访问受限资源时,需要验证用户的身份。常见的验证方式包括用户名和密码、单点登录(Single Sign-On)、多因素认证等。
-
存储用户信息:验证用户身份后,通常需要将用户的信息存储在会话(Session)或令牌(Token)中,以便后续对用户进行授权操作。
-
授权用户访问受限资源:根据用户的身份和权限,确定哪些资源可以被访问,哪些操作可以被执行。
-
保护用户信息:在传输和存储用户信息时,需要采取安全措施来保护用户的隐私和安全。
需要注意的是,用户认证和授权是 Web 应用中非常重要的安全问题,需要谨慎设计和实现。在实践中,应该使用已有的安全框架和库,并进行必要的安全测试和代码审查,以确保应用程序的安全性。
用户认证和授权是 Web 应用中非常重要的功能,可以通过实现以下步骤来完成:
-
用户注册
- 提供一个注册页面或接口,允许用户输入用户名、密码等信息。
- 在服务器端将用户输入的信息保存到数据库中,通常会对密码进行加密存储。
-
用户登录
- 提供一个登录页面或接口,允许用户输入用户名和密码进行验证。
- 在服务器端验证用户输入的用户名和密码是否匹配数据库中的记录。
- 如果验证成功,使用会话管理机制(如 Cookie 或 Token)记录用户的登录状态。
-
认证中间件
- 创建一个自定义的中间件函数,用于验证用户身份。这个中间件函数应该在需要进行身份验证的路由中使用。
- 在中间件函数中,判断用户的登录状态。如果用户未登录,则重定向到登录页面或返回相应的错误信息。
function isAuthenticated(req, res, next) { if (req.isAuthenticated()) { // 判断用户是否已登录 return next(); } res.redirect('/login'); // 未登录则重定向到登录页面 } -
访问控制
- 为每个受保护的资源或路由设置访问权限。可以使用用户角色、权限等级等来限制用户对某些功能或数据的访问。
- 在需要进行访问控制的路由中,使用认证中间件(步骤 3)验证用户身份,并根据用户的角色或权限判断是否允许访问。
app.get('/admin', isAuthenticated, function(req, res) { if (req.user.role === 'admin') { // 判断用户角色 res.render('admin'); } else { res.status(403).send('Forbidden'); // 返回 403 Forbidden 错误 } });
通过以上步骤,你可以实现用户认证和授权功能。当用户注册并登录后,可以根据其角色或权限来限制其对不同功能和资源的访问。
需要注意的是,上述示例主要介绍了基本的用户认证和授权实现方式,实际应用中可能还需要考虑其他因素,如密码加密、密码重置、记住我功能、多种身份验证策略等。可以根据具体需求进行相应的扩展和优化。
31.2 使用JWT进行令牌验证
JWT(JSON Web Token)是一种用于在网络应用间安全传输信息的开放标准。它由三部分组成:头部(Header)、负载(Payload)和签名(Signature)。
头部包含描述 JWT 的元数据,例如令牌的类型和所使用的加密算法。负载包含实际要传输的信息,可以自定义存储用户的身份信息或其他相关数据。签名用于验证令牌的完整性和真实性,防止篡改。
生成 JWT 的过程如下:
- 创建一个对象,包含你想要传递的信息。这个对象通常称为负载(Payload)。
- 使用一个秘钥来签名这个负载,生成签名(Signature)。
- 将头部、负载和签名组合在一起,形成一个完整的 JWT。
JWT 的格式为 头部.负载.签名,每部分都使用 Base64 编码进行序列化。最终生成的 JWT 是一个字符串,可以在请求的授权头(Authorization Header)中传递给服务器进行认证。
在服务器端,你可以使用相同的秘钥来验证 JWT 的有效性和完整性,从而确保该令牌是由可信的发送方生成的。验证过程包括以下步骤:
- 从请求的授权头中提取 JWT。
- 将 JWT 拆解成头部、负载和签名。
- 使用相同的秘钥和相同的算法对头部和负载进行签名,得到一个新的签名。
- 比较新生成的签名与原始 JWT 中的签名是否一致。如果一致,则表示令牌是有效的。
JWT 的一个重要特点是,它将认证信息存储在令牌本身中,避免了服务器在每次请求时查询数据库或进行其他验证操作的开销。这使得 JWT 成为构建无状态(Stateless)的身份验证系统的强大工具。
然而,需要注意的是,JWT 仅提供了认证和防篡改的功能,并不提供加密。因此,在使用 JWT 时,应避免在负载中存储敏感信息,或者对负载进行适当的加密处理,以确保数据的安全性。
31.3 使用Passport.js进行身份验证
Passport.js 是一个 Node.js 的身份验证中间件,可以用于在 Express 等 web 框架中实现用户身份验证和授权管理。它提供了一种简单而灵活的方式来实现本地身份验证、第三方登录等功能,支持多种策略(如本地验证、OAuth、OpenID 等)。
安装 Passport.js
首先需要在项目中安装 passport 和 passport-local 依赖:
npm install passport passport-local --save
下面是 Passport.js 的方法和使用方式:
-
配置 Passport.js
-
引入所需模块:
const passport = require('passport'); const LocalStrategy = require('passport-local').Strategy; -
配置用户验证策略:
passport.use(new LocalStrategy( function(username, password, done) { // 在这里进行用户名和密码的验证 // 如果验证成功,调用 done(null, user) 返回用户对象 // 如果验证失败,调用 done(null, false) 或 done(err) 返回错误信息 } )); -
序列化和反序列化用户对象:
passport.serializeUser(function(user, done) { done(null, user.id); }); passport.deserializeUser(function(id, done) { // 根据用户 ID 查询数据库获取用户对象 // 将用户对象传递给 done(null, user) });
-
-
用户认证
在路由中使用 Passport.js 进行用户认证:
app.post('/login', passport.authenticate('local', { failureRedirect: '/login' }), function(req, res) { // 认证成功后的处理 res.redirect('/'); } ); -
路由保护
使用 Passport.js 来保护需要认证的路由:
app.get('/protected', isAuthenticated, function(req, res) { // 只有认证过的用户才能访问该路由 }); -
辅助函数
Passport.js 还提供了一些辅助函数,用于在路由中判断用户的认证状态:
- req.isAuthenticated():检查用户是否已经通过认证。
- req.login(user, callback):手动登录用户,可以在用户注册后自动登录。
- req.logout():登出当前用户。
-
社交登录
Passport.js 还支持与第三方社交登录(如 Google、Facebook)集成,通过
OAuth或OpenID等协议进行认证。你可以使用相应的 Passport 提供的策略模块来实现。
以上是 Passport.js 的基本介绍和使用方式,它为用户认证和授权提供了一种灵活而强大的解决方案,可以根据自己的需求进行配置和扩展。
下面将详细讲解一下使用 Passport.js 进行身份验证的步骤:
-
配置 Passport.js
在应用中引入 Passport.js 并进行配置。通常我们需要设置 Passport 的身份验证策略、序列化和反序列化用户信息、处理用户登录请求等:
const passport = require('passport'); const LocalStrategy = require('passport-local').Strategy; // 设置身份验证策略 passport.use(new LocalStrategy( function(username, password, done) { User.findOne({ username: username }, function (err, user) { if (err) { return done(err); } if (!user) { return done(null, false); } if (!user.verifyPassword(password)) { return done(null, false); } return done(null, user); }); } )); // 序列化和反序列化用户信息 passport.serializeUser(function(user, done) { done(null, user.id); }); passport.deserializeUser(function(id, done) { User.findById(id, function(err, user) { done(err, user); }); });在上述代码中,我们设置了一个本地验证策略(使用用户名和密码进行验证),并定义了序列化和反序列化用户信息的回调函数。这些回调函数将在用户登录和注销时被调用,用于保存和恢复用户信息。
-
处理用户登录请求
在处理用户登录请求时,我们需要使用 Passport.js 的
passport.authenticate()方法。这个方法可以接受多个参数,其中第一个参数是身份验证策略的名称:app.post('/login', passport.authenticate('local', { failureRedirect: '/login' }), function(req, res) { res.redirect('/'); });在上述代码中,我们使用了
local策略进行身份验证,如果验证失败则重定向到登录页面,否则将用户重定向到首页。 -
验证用户是否已登录
在验证用户是否已登录时,我们可以使用
req.isAuthenticated()方法。这个方法会返回一个布尔值,表示当前用户是否已通过身份验证:router.get('/', function(req, res) { if (req.isAuthenticated()) { res.render('index', { user: req.user }); } else { res.redirect('/login'); } });
在上述代码中,我们判断当前用户是否已登录,如果已登录则渲染首页模板,否则重定向到登录页面。
以上就是使用 Passport.js 进行身份验证的主要步骤。当然,在实际应用中还会有很多细节和可选配置,例如:
- 使用不同的身份验证策略(如 OAuth、OpenID 等)。
- 在身份验证过程中使用中间件进行前置处理或后置处理。
- 自定义 Passport.js 的一些配置选项等。
31.4 jsonwebtoken
jsonwebtoken 是一个用于在 Node.js 和浏览器中生成和验证 JSON Web Tokens(JWT)的库。JWT 是一种轻量级的身份验证和授权机制,通过使用数字签名,可以确保数据的完整性和安全性。jsonwebtoken 提供了一组简单的方法,使得生成和验证 JWT 变得非常容易。
下面将详细介绍一下 jsonwebtoken 库的一些主要方法和功能:
-
jwt.sign(payload, secretOrPrivateKey, [options, callback]):用于生成 JWT。第一个参数是要签署的数据(称为 payload),第二个参数是用于签署和验证 JWT 的密钥,第三个参数是一个可选的配置对象,用于设置过期时间等。
参数说明:
- payload:要签名的数据,可以是一个对象、字符串或者 Buffer。这个数据将会被编码为 JWT 的有效负载部分。
- secretOrPrivateKey:用于签名和验证 JWT 的秘钥。可以是一个字符串或者 Buffer,也可以是一个包含公钥和私钥的对象。
- options(可选):一个对象,用于设置一些选项。
- callback(可选):一个回调函数,用于处理生成的 JWT。
-
jwt.verify(token, secretOrPublicKey, [options, callback]):用于生成 JWT。它接受一个 payload(要签名的数据)、一个秘钥以及一些可选的选项,返回一个包含签名信息的
JWT字符串。常见的选项包括算法、过期时间、JWT ID 等。 -
jwt.decode(token, [options]):用于解码 JWT 而不进行验证。它接受一个 JWT 字符串和一些可选的选项,返回 JWT 中包含的 payload 数据部分,但不会验证签名。
-
jwt.signAsync(payload, secretOrPrivateKey, [options]):jwt.sign() 方法的 Promise 版本,用于异步生成 JWT。
-
jwt.verifyAsync(token, secretOrPublicKey, [options]):jwt.verify() 方法的 Promise 版本,用于异步验证 JWT。
其他方法和功能
除了上述的主要方法外,jsonwebtoken 还提供了一些其他有用的功能,例如:
- 支持多种加密算法,如 HMAC、RSA、ECDSA 等。
- 可以为 JWT 设置过期时间、生效时间等限制。
- 支持自定义的 JWT 头部信息。
- 可以对 JWT 进行加密处理。
jwt options参数说明:
- algorithm:指定使用的加密算法,默认是 HS256。常见的算法有 HS256、HS384、HS512、RS256、RS384、RS512、ES256、ES384、ES512 等。
- expiresIn 或 expiresAt:指定 JWT 的过期时间,可以是一个字符串(例如:“2h” 表示 2 小时)或者一个数字(表示过期时间的秒数)。
- audience、issuer、subject:分别对应 JWT 的 audience(受众)、issuer(签发者)和 subject(主题)字段。
- notBefore:指定 JWT 的生效时间,在此之前 JWT 是无效的。
- jwtid:JWT 的唯一标识符。
- header:一个对象,用于指定 JWT 的头部信息。
- noTimestamp:如果设置为 true,则不会在 JWT 中添加时间戳。
- encoding:指定编码方式,默认是 “utf8”。
jsonwebtoken 提供了一组简单而强大的方法,使得在应用中处理 JWT 变得非常方便。使用这些方法,我们可以轻松地实现用户身份验证、授权管理等功能。
31.4.1 生成JWT
下面是使用 jsonwebtoken 生成 JWT 的示例代码:
const express = require('express');
const jwt = require('jsonwebtoken');
const app = express();
// 生成 JWT
app.get('/generate-token', (req, res) => {
// 假设你有一个用户对象
const user = {
username: 'exampleuser',
mobile: '12345678901',
email: 'example@example.com'
};
// 生成 JWT
const token = jwt.sign(user, 'secret-key', { expiresIn: '1h' });
// 将生成的 JWT 返回给客户端
res.json({ token });
});
// 启动服务器
const port = 3000;
app.listen(port, () => {
console.log(`Server is running on http://localhost:${port}`);
});
在上面的示例中,我们使用 jwt.sign() 方法生成 JWT。运行以上示例后,访问 /generate-token 路径将返回一个包含生成的 JWT 的 JSON 响应。
注意:实际应用中需要更多的安全性措施,如将密钥存储在安全的地方、校验 JWT 签名等。此外,还要注意在生成 JWT 时不要包含敏感信息,如密码等。
31.4.2 验证JWT
下面是一个验证 JWT 的示例:
const jwt = require('jsonwebtoken');
const token = 'your-jwt-token';
const secretKey = 'your-secret-key';
jwt.verify(token, secretKey, (err, decoded) => {
if (err) {
// 验证失败
} else {
// 验证成功,获取解码后的数据
console.log(decoded);
}
});
在上述示例中,jwt.verify() 方法用于验证 JWT 的有效性和完整性。第一个参数是要验证的 JWT,第二个参数是用于签署和验证 JWT 的密钥,第三个参数是一个回调函数,用于处理验证结果。
jsonwebtoken 还提供了其他一些方法和配置选项,例如对 JWT 进行加密、指定算法、自定义签名等。你可以查阅 jsonwebtoken 的官方文档以获取更多详细信息。
31.5 使用Passport和JWT实现用户的认证和授权
使用 Passport 和 JWT 可以很方便地实现用户的认证和授权。下面是详细的步骤:
-
首先需要安装必要的依赖:
npm install passport passport-local passport-jwt jsonwebtoken bcrypt其中:
- passport 是 Passport.js 的核心库;
- passport-local 是用于本地验证的 Passport.js 策略;
- passport-jwt 是用于 JWT 验证的 Passport.js 策略;
- jsonwebtoken 是用于生成和验证 JWT 的库;
- bcrypt 是用于密码加密的库。
-
配置 Passport.js
在 Express 应用中配置 Passport.js,包括初始化 Passport.js、配置策略和序列化/反序列化用户等操作。示例代码如下:
const passport = require('passport'); const LocalStrategy = require('passport-local').Strategy; const JwtStrategy = require('passport-jwt').Strategy; const ExtractJwt = require('passport-jwt').ExtractJwt; const bcrypt = require('bcrypt'); const SECRET_KEY = 'mysecretkey'; // 指定 JWT 密钥 const User = require('./models/User'); // 引入 User 模型 // 初始化 Passport.js passport.use(new LocalStrategy({ usernameField: 'email', // 指定用户名字段为 email }, async (email, password, done) => { try { const user = await User.findOne({ email }); if (!user) { return done(null, false, { message: 'Incorrect email.' }); } const match = await bcrypt.compare(password, user.password); if (!match) { return done(null, false, { message: 'Incorrect password.' }); } return done(null, user); } catch (err) { return done(err); } }) ); passport.use(new JwtStrategy({ jwtFromRequest: ExtractJwt.fromAuthHeaderAsBearerToken(), // 从请求头部解析 JWT secretOrKey: SECRET_KEY, }, async (jwtPayload, done) => { // 在此处验证JWT,并在成功时将用户信息传递给done回调 try { const user = await User.findById(jwtPayload.sub); if (!user) { return done(null, false); } return done(null, user); } catch (err) { return done(err); } }) ); // 序列化和反序列化用户 passport.serializeUser((user, done) => { done(null, user.id); }); passport.deserializeUser(async (id, done) => { try { const user = await User.findById(id); done(null, user); } catch (err) { done(err); } });上述代码中:
- 首先指定了
SECRET_KEY作为 JWT 的密钥;
然后定义了LocalStrategy和JwtStrategy,分别用于本地验证和 JWT 验证; - 在
LocalStrategy中,使用bcrypt比较密码的哈希值是否匹配; - 在
JwtStrategy中,使用ExtractJwt.fromAuthHeaderAsBearerToken()将 JWT 解析出来,并根据 JWT 的sub字段查询对应的用户; - 最后定义了
serializeUser和deserializeUser函数,用于将用户对象序列化为id和从id反序列化为用户对象。
- 首先指定了
-
创建登录和注册 API
在 Express 应用中创建登录和注册 API,使用 Passport.js 进行身份验证,并生成并返回 JWT。示例代码如下:
const express = require('express'); const jwt = require('jsonwebtoken'); const passport = require('passport'); const router = express.Router(); const SECRET_KEY = 'mysecretkey'; // 指定 JWT 密钥 // POST /api/login router.post('/login', (req, res, next) => { passport.authenticate('local', { session: false }, (err, user, info) => { if (err) { return next(err); } if (!user) { return res.status(400).json({ message: info.message }); } req.logIn(user, { session: false }, (err) => { if (err) { return next(err); } const token = jwt.sign({ sub: user.id }, SECRET_KEY); return res.json({ token }); }); })(req, res, next); }); // POST /api/register router.post('/register', async (req, res, next) => { try { const { email, password } = req.body; const existingUser = await User.findOne({ email }); if (existingUser) { return res.status(400).json({ message: 'Email already exists.' }); } const hash = await bcrypt.hash(password, 10); const user = new User({ email, password: hash }); await user.save(); const token = jwt.sign({ sub: user.id }, SECRET_KEY); return res.json({ token }); } catch (err) { return next(err); } });上述代码中:
- 在
/api/login路由中,首先使用passport.authenticate函数进行本地验证,如果通过,则生成 JWT 并返回; - 在
/api/register路由中,首先查询是否已存在相同的用户,如果不存在,则使用bcrypt对密码进行加密,并创建新的用户,最后生成 JWT 并返回。
- 在
-
创建受保护的 API
在 Express 应用中创建受保护的 API,使用 Passport.js 和 JWT 进行身份验证和授权。示例代码如下:
const express = require('express'); const passport = require('passport'); const router = express.Router(); // GET /api/profile router.get('/profile', passport.authenticate('jwt', { session: false }), (req, res) => { // 返回用户信息 res.json({ user: req.user }); });上述代码中使用
passport.authenticate('jwt', { session: false })进行 JWT 验证,并使用req.user获取当前用户的信息,最后将用户信息返回给客户端。
总结
通过合理地设计和实现用户认证和授权机制,可以保护应用程序中的敏感数据和功能,确保只有经过认证和授权的用户才能访问和执行相关操作。同时,用户认证和授权还提供个性化的用户体验,满足不同用户的需求。
32-错误处理与断言
错误处理和断言是编写高质量代码的重要方面,能够帮助我们及时发现问题并进行修复。以下是关于错误处理和断言的一些基本概念和最佳实践。
32.1 使用domain处理错误
错误处理是指在程序运行过程中遇到错误时,采取一定的措施来修复或通知用户。
Domain 模块是 Node.js 中的一个核心模块,用于封装应用程序相关的信息,例如当前登录用户、用户设置和应用程序状态等。它提供了一种将应用程序逻辑组织为单个单元的方法,这个单元可以被多个相关的模块共享和重复使用。
在 Node.js 中,每个模块都有自己的作用域,而且每个模块都可以访问其父级模块的变量和函数。但使用Domain模块可以让我们更方便地处理模块间的错误和异常,它提供了一种将多个异步操作组合成一个单元的机制,从而使得错误处理更加简单和一致。
使用 Domain 模块,我们可以将应用程序的不同部分分组,并为每个组分配一个 Domain 对象。当一个错误被抛出时,Domain 会捕获它并将其传递给与该错误关联的Domain对象中的错误处理程序。这样,我们就可以为整个应用程序定义一个全局的错误处理程序,以避免错误的传递和处理。
Domain 模块的主要功能如下:
-
隔离异步操作:通过创建一个 Domain 对象,我们可以将特定的异步操作封装在该对象内部,使其与其他异步操作相互隔离。这样可以防止错误在不同的异步操作之间传播,提高代码的健壮性。
-
捕获异常:Domain 对象可以捕获异步操作中抛出的异常,并将其传递给绑定的错误处理器。这样我们可以集中处理所有的异常,而不需要在每个异步操作中单独处理。
-
处理未捕获的异常:Domain 对象还可以处理未捕获的异常,即在没有显式捕获的情况下抛出的异常。这样可以避免应用程序因为未捕获的异常而崩溃,并且可以在异常发生时进行适当的清理和处理。
32.1.1 Domain对象
Domain 对象是 Node.js 中的一个特殊对象,它用于管理异步操作的错误处理和资源清理。每个 Domain 对象都可以关联多个异步操作,并在这些操作中捕获和处理错误。
下面详细介绍Domain对象的常用方法和属性:
方法:
-
domain.create():用于创建一个新的 Domain 对象。
const domain = require('domain'); const myDomain = domain.create(); -
domain.run(fn):将要执行的代码包装在一个域中,并执行该代码。如果在域内部发生了错误,域会自动捕获并传递给错误处理器。
myDomain.run(() => { // 执行异步操作 }); -
domain.add(emitter):将 EventEmitter 对象添加到域中,使其成为域的一部分。当事件触发时,如果该事件注册在域中,则错误会被捕获。
myDomain.add(myEmitter); -
domain.remove(emitter):从域中移除EventEmitter对象。
myDomain.remove(myEmitter); -
domain.bind(callback):将回调函数绑定到域中,返回一个绑定后的函数。当绑定的函数被调用时,域会自动捕获其中的错误。
const boundCallback = myDomain.bind(callback); -
domain.intercept(callback):拦截器函数,用于拦截通过返回值或异常传递出来的错误。可以使用该方法实现自定义的错误处理逻辑。
myDomain.intercept((err) => { // 自定义错误处理逻辑 }); -
domain.enter():手动进入域,将当前域设置为活动域。如果没有活动域,则将当前域设置为主域。
myDomain.enter(); -
domain.exit():手动退出域,将活动域设置为上一个域。
myDomain.exit(); -
domain.dispose():销毁域对象,停止它对异步操作的捕获和处理。
myDomain.dispose();
属性:
domain.members:返回当前域中的成员列表,即关联到该域的 EventEmitter 对象列表。
事件:
-
‘error’:当在域中发生错误时触发该事件。错误对象作为参数传递给事件处理器。
myDomain.on('error', (err) => { console.error('Caught error:', err); }); -
‘bind’:当通过domain.bind()方法将回调函数绑定到域中时触发该事件。
myDomain.on('bind', () => { console.log('Callback function is bound to the domain.'); }); -
‘intercept’:当通过domain.intercept()方法将拦截器函数绑定到域中时触发该事件。
myDomain.on('intercept', () => { console.log('Intercept function is bound to the domain.'); });
让我们来看一个简单的示例,以便更好地理解 Domain 模块的使用。
const domain = require('domain');
const fs = require('fs');
// 创建Domain对象
const myDomain = domain.create();
// 定义错误处理器
myDomain.on('error', (err) => {
console.error('Caught error:', err);
});
// 绑定异步操作到Domain对象
myDomain.run(() => {
// 异步读取文件
fs.readFile('file.txt', 'utf8', (err, data) => {
if (err) throw err;
console.log(data);
});
});
在上面的示例中,我们创建了一个 Domain 对象 myDomain,并定义了一个错误处理器。然后,使用 myDomain.run() 方法将异步读取文件的操作绑定到 myDomain 对象中。如果在读取文件的过程中出现错误,错误处理器就会被触发,打印错误信息。
注意:Domain 模块在 Node.js v10.0.0 版本之后已被废弃,不推荐使用。建议使用更现代化的异步操作错误处理方式,如 Promise、async/await等。
错误处理的注意事项:
- 尽早检测和捕获异常;
- 避免捕获过大的异常,应该只捕获需要处理的异常;
- 不要忽略异常,即使无法恢复,也应该记录和通知用户;
- 不要使用异常作为控制流,应该使用条件语句代替;
- 不要在循环体中捕获异常,应该将循环放在
try块外部; - 在异步代码中使用
try...catch无法捕获回调函数中的异常,需要使用Promise或回调函数处理异常。
32.2 断言
断言是指在代码中插入一些判断语句,用于验证程序运行时的状态。如果断言失败,则表示程序出现了错误,需要进行修复。断言可以有助于提高代码的可靠性和可维护性。
在 Node.js 中,断言是一种用于测试代码正确性的工具。它们可以帮助开发人员验证程序的假设并捕获潜在的错误。Node.js 提供了内置的断言模块(assert module),其中包含一组用于编写和运行断言的函数。
当使用 Node.js 的断言模块时,如果断言条件不成立,会抛出一个 AssertionError 错误。这个错误可以被 try-catch 语句捕获和处理。
下面是 Node.js 中断言模块的常用方法:
-
assert(value, [message]):验证一个值是否为真(truthy)。如果值为假(falsy),则抛出一个AssertionError错误,可选地附带自定义错误消息。
const assert = require('assert'); assert(true); // 通过 assert(1 === 1); // 通过 assert(false, '错误消息'); // 抛出AssertionError错误,且错误消息为'错误消息' assert(1 === 2, '1 不等于 2'); // 抛出AssertionError错误,且错误消息为'1 不等于 2' -
assert.ok(value, [message]):该方法是assert(value, [message])方法的别名,用于验证一个值是否为真(truthy)。如果值为假(falsy),则抛出一个 AssertionError 错误,可选地附带自定义错误消息。
const assert = require('assert'); assert.ok(true); // 通过 assert.ok(1 === 1); // 通过 assert.ok(false, '错误消息'); // 抛出AssertionError错误,且错误消息为'错误消息' assert.ok(1 === 2, '1 不等于 2'); // 抛出AssertionError错误,且错误消息为'1 不等于 2' -
assert.strictEqual(actual, expected, [message]):验证两个值是否严格相等。如果两个值不相等,则抛出一个AssertionError错误,可选地附带自定义错误消息。
assert.strictEqual(1, 1); // 通过 assert.strictEqual('hello', 'hello'); // 通过 assert.strictEqual(1, 2, '1 不等于 2'); // 抛出AssertionError错误,且错误消息为'1 不等于 2' assert.strictEqual('hello', 'world', '字符串不相等'); // 抛出AssertionError错误,且错误消息为'字符串不相等' -
assert.notStrictEqual(actual, expected, [message]):该方法用于验证两个值是否不严格相等。如果两个值相等,则抛出一个 AssertionError 错误,可选地附带自定义错误消息。
const assert = require('assert'); assert.notStrictEqual(1, 2); // 通过 assert.notStrictEqual('hello', 'world'); // 通过 assert.notStrictEqual(1, 1, '1 等于 1'); // 抛出AssertionError错误,且错误消息为'1 等于 1' assert.notStrictEqual('hello', 'hello', '字符串相等'); // 抛出AssertionError错误,且错误消息为'字符串相等' -
assert.deepEqual(actual, expected, [message]):验证两个值是否深度相等。如果两个值不相等,则抛出一个 AssertionError 错误,可选地附带自定义错误消息。
assert.deepEqual({ a: 1 }, { a: 1 }); // 通过 assert.deepEqual([1, 2], [1, 2]); // 通过 assert.deepEqual({ a: 1 }, { b: 1 }, '对象属性不相等'); // 抛出AssertionError错误,且错误消息为'对象属性不相等' assert.deepEqual([1, 2], [2, 1], '数组元素不相等'); // 抛出AssertionError错误,且错误消息为'数组元素不相等' -
assert.notDeepEqual(actual, expected, [message]):该方法用于验证两个值是否不深度相等。如果两个值深度相等,则抛出一个 AssertionError 错误,可选地附带自定义错误消息。
const assert = require('assert'); assert.notDeepEqual({ a: 1 }, { b: 1 }); // 通过 assert.notDeepEqual([1, 2], [2, 1]); // 通过 assert.notDeepEqual({ a: 1 }, { a: 1 }, '对象属性相等'); // 抛出AssertionError错误,且错误消息为'对象属性相等' assert.notDeepEqual([1, 2], [1, 2], '数组元素相等'); // 抛出AssertionError错误,且错误消息为'数组元素相等' -
assert.throws(block, [error], [message]):验证一个函数是否抛出了指定类型的错误。如果函数没有抛出错误,或者抛出的错误类型不符合预期,则抛出一个 AssertionError 错误,可选地附带自定义错误消息。
assert.throws( () => { throw new Error('错误'); }, Error, '抛出的错误类型不匹配' ); // 通过 assert.throws( () => { // 没有抛出错误 }, Error, '没有抛出错误' ); // 抛出AssertionError错误,且错误消息为'没有抛出错误'
下面是一个使用Node.js断言模块的例子:
const assert = require('assert');
function add(a, b) {
return a + b;
}
try {
assert.equal(add(1, 2), 4, '1 + 2 不等于 4');
} catch (err) {
console.error(err);
}
在上面的例子中,我们使用 assert.equal() 方法验证 add() 函数的返回值是否等于4。由于1+2显然不等于4,所以该断言条件不成立,会抛出一个 AssertionError 错误。我们使用try-catch语句捕获这个错误,并将错误信息打印到控制台中。
除了使用 try-catch 语句来捕获 AssertionError 错误之外,Node.js 还提供了一个 process.on('uncaughtException') 事件来捕获未被处理的异常。在这个事件中,我们可以做一些处理,例如记录日志或者退出进程。
const assert = require('assert');
function add(a, b) {
return a + b;
}
// 捕获未被处理的异常
process.on('uncaughtException', (err) => {
console.error(err);
process.exit(1); // 退出进程
});
assert.equal(add(1, 2), 4, '1 + 2 不等于 4');
在上面的例子中,我们监听了 process.on('uncaughtException') 事件,并在事件处理器中打印了错误信息。同时,我们调用了 process.exit(1) 方法来退出进程,避免程序继续执行下去。
注意:在生产环境中,不建议使用 process.on('uncaughtException') 事件处理 AssertionError 错误,因为这可能会导致未知的副作用。相反,应该在代码中显式地处理 AssertionError 错误,并采取适当的措施来解决问题。
这些断言方法可以根据具体的测试需求选择使用,确保代码的正确性和健壮性。
断言的注意事项:
- 断言应该简洁明了,不应该包含过多的逻辑;
- 断言应该尽量直接反映问题所在,避免过于抽象或技术化的术语;
- 断言应该尽早执行,可以在代码中的关键位置插入断言语句;
- 断言应该使用条件语句代替复杂的逻辑运算;
- 断言不应该在生产环境中使用,可以使用配置参数来控制是否执行断言语句。
总结
错误处理和断言是 Node.js 开发中不可或缺的重要实践,能够提高应用程序的稳定性和可靠性。合理地捕获、处理和记录错误,以及使用断言测试验证代码的正确性,将有助于构建健壮且可靠的 Node.js 应用程序。
33-测试
测试是软件开发过程中的一项关键活动,旨在验证和验证软件系统的正确性、可靠性和性能。通过测试,可以发现潜在的缺陷和问题,并确保软件在各种情况下都能按照预期工作。
33.1 单元测试
单元测试是软件开发过程中的一种测试方法,用于验证程序中的最小可测试单元(通常是函数、方法或类)是否按预期工作。它的主要目的是在开发过程中及早发现和纠正代码中的错误,以确保每个代码单元独立地执行时都能产生正确的结果。
单元测试主要包含断言、测试框架、测试股覆盖率、mock、持续集成等方面,此外还会加入异步代码和私有方法这两部分测试。
当进行 Node.js 单元测试时,通常可以遵循以下大纲:
-
选择测试框架:常见的 Node.js 单元测试框架包括 Mocha、Jest、Jasmine 等。这些框架提供了丰富的功能和断言库,能够方便地编写和执行测试用例。
-
安装测试框架和依赖:使用 npm 或 yarn 等包管理工具,安装所选测试框架及其相关依赖项。例如,可以使用以下命令安装 Mocha 和 Chai:
-
编写测试用例:对每个需要进行单元测试的函数或方法,编写相应的测试用例。测试用例应该覆盖正常情况、边界情况和异常情况,以确保代码的鲁棒性。
-
组织测试文件结构:根据项目的结构和需求,组织测试文件结构。通常建议将测试文件与被测试的源文件放在相同的目录下或者独立的test目录下。
-
运行测试:通过命令行或配置脚本,运行测试框架提供的命令来执行所有的测试用例。例如,使用Mocha可以通过以下命令运行测试:
npx mocha。 -
断言和验证:使用测试框架提供的断言库,编写断言语句来验证实际输出和预期输出是否一致。断言语句通常用于判断函数的返回值、抛出的异常、数据的相等性等。
-
异步测试处理:在 Node.js 开发中,很多操作是异步的,例如回调函数、Promise 和 async/await 等。在测试中,需要确保异步操作被正确处理和验证。测试框架通常提供了对异步操作的支持和工具。
-
Mocking和Stubbing:在单元测试中,可能需要模拟或替换外部依赖,以隔离被测试的单元。可以使用 mocking 和 stubbing 技术来模拟外部服务或依赖的行为,以便更好地控制测试环境。
-
代码覆盖率分析:使用代码覆盖率工具(如Istanbul)来分析测试覆盖率,确定哪些代码路径被测试覆盖到,并有助于发现未覆盖的代码块。
-
持续集成和自动化测试:将单元测试集成到持续集成系统中,确保每次代码提交都会运行测试,并及时通知开发人员有关测试结果。
33.1.1 断言
在单元测试中,使用断言是一种常见的方法来验证代码的行为是否符合预期。断言库通常提供了一组函数,用于比较实际输出与预期输出之间的差异,并在断言失败时提供有用的错误信息。在 JavaScript 中,一些流行的测试框架和库都提供了自己的断言模块(目前大多数的断言库都是基于assert模块进行封装和扩展的。),这些断言模块通常提供以下一些常用的方法:
-
assert.equal(actual, expected, [message]):比较 actual 和 expected 是否相等,如果相等则测试通过,否则测试失败。可选的 message 参数用于在测试失败时输出错误信息。
-
assert.strictEqual(actual, expected, [message]):与
assert.equal()类似,但使用严格相等运算符(即 ===)比较。 -
assert.deepEqual(actual, expected, [message]):比较 actual 和 expected 的值是否深度相等,即它们的属性和属性值是否相同。可选的 message 参数用于在测试失败时输出错误信息。
-
assert.notEqual(actual, expected, [message]):与
assert.equal()相反,如果 actual 不等于 expected 则测试通过。 -
assert.notStrictEqual(actual, expected, [message]):与
assert.strictEqual()相反,如果 actual 不严格等于 expected 则测试通过。 -
assert.notDeepEqual(actual, expected, [message]):与 assert.deepEqual() 相反,如果 actual 和 expected 的值不深度相等则测试通过。
-
assert.ok(value, [message]):验证 value 是否为真值,如果是则测试通过,否则测试失败。可选的 message 参数用于在测试失败时输出错误信息。
-
assert.fail(actual, expected, message, operator):强制标记当前测试为失败状态,并输出错误信息。可选的 operator 参数用于指定运算符名称。
这些是断言模块的一些常用方法,不同的断言库可能会提供其他不同的方法和语法。熟悉并掌握这些方法的使用可以让我们编写更加准确、清晰和易于维护的单元测试。
常见的断言库有 Chai、Assert、Node.js 内置的 assert 模块等。选择合适的断言库,并根据需要编写断言语句来验证代码的行为。
33.1.2 测试框架
使用断言函数进行比较。如果断言失败(即实际结果与预期结果不符),则断言库会抛出一个错误,从而造成整个应用的停止运行,这是非常不合理的。正确的做法应该是记录下抛出的异常并可以继续执行,并生成测试报告,这些就是测试框架可以做到的事情。接下来我们就对Mock框架做一些基本的介绍。
Mocha 是一个 JavaScript 的测试框架,可用于编写单元测试、集成测试和端到端测试。它支持异步代码和回调式测试,并提供了丰富的测试报告和错误信息输出。Mocha 也可以在浏览器和 Node.js 环境中运行。
Mocha 的特点包括:
-
支持多种测试风格:Mocha 支持多种测试风格,包括
BDD、TDD和QUnit风格。开发者可以根据自己的喜好和项目需求选择适合的风格。 -
强大的异步测试支持:Mocha 提供了强大的异步测试支持,包括
Promise、async/await和回调式测试等。 -
丰富的测试报告和错误信息输出:
Mocha提供了多种测试报告格式和错误信息输出方式,如Spec、Dot、nyan等报告格式和详细的错误信息输出。 -
灵活的钩子函数:Mocha 提供了多个钩子函数(如
before、after、beforeEach和afterEach),用于在测试生命周期中执行一些操作,比如初始化测试数据、清理测试环境等。 -
可扩展性强:Mocha 可以通过插件扩展其功能,例如使用
chai插件来提供更丰富的断言库。
安装 Mocha 可以执行 npm install --save-dev mocha 命令完成安装。
33.1.3 测试风格
TDD(Test-Driven Development,测试驱动开发)和 BDD(Behavior-Driven Development,行为驱动开发)是两种常用的软件开发方法论,它们都强调在编写代码之前编写测试用例。
Mocha 是一个非常灵活的测试框架,它支持多种不同的测试风格。以下是 Mocha 支持的主要测试风格:
-
TDD(测试驱动开发)
在
TDD中,测试用例的编写是在实现代码之前进行的,它强调先写测试,再编写实现代码。这种方式可以帮助你更好地理解需求和设计,并保证代码在满足需求的同时具备良好的测试覆盖率。在 Mocha 中,你可以使用suite、test和assert等函数来编写TDD风格的测试用例。const assert = require('assert'); suite('Array', function() { test('#indexOf()', function() { const arr = [1, 2, 3]; assert.equal(arr.indexOf(2), 1); assert.equal(arr.indexOf(4), -1); }); });在上述例子中,我们使用
suite创建一个测试套件,使用test创建一个测试用例,并使用assert断言库进行断言。 -
BDD(行为驱动开发)
BDD强调测试用例的编写应该更加注重描述代码的行为和功能,以便更好地与非技术人员沟通和理解。BDD的测试用例描述起来更接近自然语言,通常使用describe、it和expect等函数来组织测试套件、测试用例和断言。const expect = require('chai').expect; describe('Array', function() { it('should return the index of a value when using indexOf()', function() { const arr = [1, 2, 3]; expect(arr.indexOf(2)).to.equal(1); expect(arr.indexOf(4)).to.equal(-1); }); });在上述例子中,我们使用
describe创建一个测试套件,使用it创建一个测试用例,并使用Chai断言库的expect函数进行断言。 -
QUnit
种风格常用于测试 jQuery 和其他 JavaScript 库。在
QUnit风格中,您可以使用QUnit.test和QUnit.assert等函数来编写测试用例。QUnit.test('Array indexOf', function(assert) { const arr = [1, 2, 3]; assert.equal(arr.indexOf(2), 1); assert.equal(arr.indexOf(4), -1); });在上述例子中,我们使用
QUnit.test创建一个测试用例,并使用QUnit.assert断言库进行断言。
Chai 是一个流行的断言库,可以用于编写清晰且易于理解的断言语句。
在 Mocha 中,可以使用 describe() 函数来定义测试套件,使用 it() 函数来定义具体的测试用例。在测试用例中,使用断言库(如 Chai)来验证代码输出是否符合预期。
// 安装依赖:npm install mocha chai --save-dev
const assert = require('chai').assert;
const { add } = require('./math'); // 被测试的模块
describe('Math', () => {
describe('add', () => {
it('should return the sum of two numbers', () => {
const result = add(2, 3);
assert.equal(result, 5);
});
});
});
在上述例子中,我们使用 describe 创建一个测试套件,使用 it 创建两个测试用例,并使用 Chai 断言库的 assert 函数进行断言。
33.1.4 测试报告
Mocha 提供了多种测试报告格式,可以通过配置来指定生成的测试报告格式。下面是 Mocha 支持的主要测试报告格式:
-
Spec 格式
Spec格式是一种人类可读性高的测试报告格式,它将每个测试用例的运行结果输出到控制台上,每个测试套件和测试用例都会有自己的标题。例如:Array #indexOf() ✓ should return -1 when the value is not present ✓ should return the index of a value when the value is present在上述例子中,我们使用
Array作为测试套件的标题,使用#indexOf()作为测试用例的标题,并输出了每个测试用例的运行结果。 -
Dot 格式
Dot格式是一种简洁的测试报告格式,它只输出每个测试用例的运行结果,用一个点表示通过,一个F表示失败。例如:........... 1 failing -
XUnit 格式
XUnit格式是一种通用的测试报告格式,可以被很多 CI 工具和测试管理工具所支持。它将测试结果以 XML 格式输出,包括测试套件、测试用例、测试结果等信息。例如:<testsuites> <testsuite name="Array" tests="2" failures="1" time="0.015"> <testcase classname="Array" name="#indexOf()" time="0.007"> <failure message="expected -1 to equal 1"></failure> </testcase> <testcase classname="Array" name="#indexOf()" time="0.008"></testcase> </testsuite> </testsuites>在上述例子中,我们使用
testsuites和testsuite标签表示测试套件,使用testcase标签表示测试用例,使用failure标签表示测试失败的信息。
除了以上三种格式外,Mocha 还支持 TAP 格式、JSON 格式和 HTML 格式等报告格式。你可以通过命令行参数或配置文件来指定生成的测试报告格式。例如:
mocha test/**/*.js --reporter spec
在上述例子中,我们使用 --reporter 参数指定生成 Spec 格式的测试报告。
注意:Mocha 的安装位置,如果您的 Mocha 是安装在本地而不是全局,那么就需要使用 ./node_modules/.bin/mocha test/**/*.js 的方式去运行 Mocha。
无论你选择哪种测试报告格式,Mocha 都提供了丰富的选项和插件,可以帮助你生成具有可读性、可扩展性和兼容性的测试报告。
另外执行 mocha -help 还可以查看更多的帮助命令来了解如何使用它们。
33.1.5 测试用例
测试用例是针对被测试主题的具体行为或状态进行验证的代码片段。在 Mocha 中,测试用例是由描述(describe)块和断言(assertion)语句组成的。下面是对 Mocha 测试用例的详细介绍:
-
描述块(describe block)
描述块用于对一组相关的测试用例进行描述,通常用来描述一个模块、一个函数或一个功能的测试集合。描述块使用
describe()函数来定义,它可以嵌套使用以组织测试用例。描述块一般包括:描述块的名称:描述被测试的主题,通常是一个字符串。
示例:
describe('Array', function() { // 测试用例内容 }); -
测试用例(it block)
测试用例包含了针对被测试主题的具体测试逻辑,它使用
it()函数来定义。每个测试用例应该尽量独立,测试一个特定的行为或状态。测试用例一般包括以下内容:- 测试用例的名称:描述被测试的具体行为或状态,通常是一个字符串。
- 断言语句:用来验证被测试主题的预期行为或状态。
示例:
it('should return -1 when the value is not present', function() { // 断言语句 }); it('should return the index of a value when the value is present', function() { // 断言语句 }); -
断言语句(assertion)
断言语句用于验证测试的预期结果是否符合实际结果。Mocha 并不内置断言库,通常需要结合其他断言库(如 Chai)来编写断言语句。
示例:
it('should return -1 when the value is not present', function() { assert.equal([1,2,3].indexOf(4), -1); }); it('should return the index of a value when the value is present', function() { assert.equal([1,2,3].indexOf(3), 2); });- 异步测试
在实际开发中,很多测试场景涉及异步操作,比如异步函数、网络请求等。Mocha 提供了丰富的异步测试支持,可以通过回调函数、
Promise、async/await等方式来处理异步测试。示例:
javascript it('should return the value asynchronously', function(done) { someAsyncFunction(function(value) { assert.equal(value, expectedValue); done(); }); }); it('should return the value asynchronously', async function() { const value = await someAsyncFunction(); assert.equal(value, expectedValue); });通过以上介绍,你可以了解到在 Mocha 中,测试用例是通过描述块和断言语句来组织和编写的。合理的组织测试用例能够提高测试的可读性和可维护性,帮助我们更好地进行测试驱动的开发。
- 超时时间
在Mocha测试用例中,可以通过设置超时时间来避免测试用例无限期等待或死锁。Mocha默认的超时时间是2秒,如果测试用例执行时间超过该时间,Mocha会认为测试用例失败并报告超时错误。
全局设置超时时间:可以在mocha命令行中加入–timeout参数来设置全局的超时时间,单位为毫秒,例如:
$ mocha --timeout 5000单独设置超时时间:可以在it块中使用
this.timeout()方法单独设置测试用例的超时时间,例如:it('should return the sum of two numbers', function(done) { this.timeout(5000); // 设置超时时间为5秒 setTimeout(function() { const result = 2 + 3; assert.strictEqual(result, 5); done(); }, 6000); // 休眠6秒后再执行断言 });上面的例子中,我们使用
this.timeout()方法将测试用例的超时时间设置为5秒。如果在5秒内测试用例没有完成,Mocha 会认为测试用例失败并报告超时错误。请注意,在异步测试中必须调用 `done()` 方法来通知 Mocha 测试用例已经完成。否则,Mocha 会认为测试用例一直处于挂起状态并等待超时。
通过设置超时时间,可以避免测试用例出现死锁或长时间等待的情况,从而提高测试用例的可靠性。
下面是一个测试用例的示例代码:
const assert = require('assert');
// describe块表示一组相关的测试用例
describe('Math', function() {
// it块表示一个具体的测试用例
it('should return the sum of two numbers', function() {
const result = 2 + 3;
// 使用断言库进行断言
assert.strictEqual(result, 5);
});
it('should return the difference between two numbers', function() {
const result = 5 - 3;
assert.strictEqual(result, 2);
});
});
上面的示例展示了一个简单的 Math 类的测试用例。describe块用于定义一组相关的测试用例,it块用于定义具体的测试用例。在it块中,我们对Math类的加法和减法方法进行了测试,并使用断言库(这里使用了 Node.js 内置的assert模块)进行断言。
在编写测试用例时,还可以使用 Mocha 提供的其他功能,如before、after、beforeEach、afterEach等钩子函数,以及异步测试、测试套件嵌套等特性。
33.1.6 测试覆盖率
Mocha 本身并不提供测试覆盖率功能,但可以通过与其他工具集成来实现测试覆盖率报告生成。下面介绍一种常用的与 Mocha 配合使用的测试覆盖率工具——Istanbul。
Istanbul 是一个 JavaScript 代码覆盖率工具,它可以与 Mocha 进行集成,帮助我们分析测试用例对代码的覆盖情况。以下是使用 Istanbul 生成测试覆盖率报告的步骤:
-
安装 Istanbul:
npm install --save-dev nyc -
在项目的
package.json文件中添加一个test脚本,用于运行 Mocha 测试并生成覆盖率报告。例如:"scripts": { "test": "nyc mocha" } -
运行测试
npm test -
Istanbul 会收集测试期间执行的代码路径,并生成覆盖率数据。默认情况下,覆盖率数据会保存在
.nyc_output目录中。 -
生成覆盖率报告:
npx nyc report --reporter=lcov此命令将生成一个名为
lcov-report的目录,其中包含HTML形式的覆盖率报告。你可以在浏览器中打开lcov-report/index.html文件来查看详细的覆盖率信息。
除了lcov报告,Istanbul 还支持其他格式的覆盖率报告,如text、json等。你可以根据需要选择合适的报告格式。
要在 Mocha 中生成测试覆盖率报告,我们可以使用 Istanbul 工具。首先安装 nyc(Istanbul的命令行工具),然后在 package.json 文件中配置 test 脚本运行 Mocha 测试,并通过 nyc 命令运行测试并生成覆盖率数据。最后,使用 nyc report 命令生成覆盖率报告。通过这些步骤,我们可以获得关于测试用例对代码覆盖情况的详细报告。
33.1.7 其他
mock
在 Mocha 测试中,有时候我们可能会遗漏某些异常处理的情况,这可能导致我们无法完整地验证被测试代码的行为。例如:网络异常、权限异常等等这些难以模拟的异常,我们可以人为手动制造一个异常,使用 mock 对象来模拟其行为,以便更好地验证被测试代码的行为。
例如文件操作是非常不可忽视的异常,我们可以伪造 fs.readFileSync() 方法来手动抛出一个异常。同时还可以搭配 Muk 这个库来一起使用。
Muk 是一个用于mock Node.js 模块的库,它可以在单元测试中对模块进行替换以便于测试。使用Muk可以有效地进行测试,特别是当测试用例需要 mock 掉某个模块的时候,Muk 可以非常方便地帮助我们实现这一点。
安装 Muk 库:npm install muk --save-dev
同时为了不影响到其他的测试用例,我们可以使用 before() 和 after() 两个钩子函数来搭配使用。例如:
const fs = require('fs');
const muk = require('muk');
const assert = require('assert');
before(function() {
// 模拟权限不足错误
// 使用muk替换fs模块中的readFileSync方法
muk(fs, 'readFileSync', () => {
throw new Error('Permission denied');
});
});
// 测试代码
describe('File read', () => {
it('should read file content', () => {
const content = fs.readFileSync('test.txt', 'utf8');
assert.strictEqual(content, 'Hello, World!');
});
// 多个测试用例
//('xxx', () => {});
});
after(function () {
// 恢复被替换的方法
muk.restore();
})
使用 muk 替换 fs.readFileSync 方法,并在测试完成后使用 muk.restore() 方法来恢复原始的方法。这样可以确保在其他测试用例中仍然可以使用原始的方法。
私有方法的测试
在一个js文件中,只有被 exports 或者 module.export 导出的方法和变量才能被外部 require 引入时访问,而模块内部的私有方法和变量只有模块自己才能访问。rewire模块可以实现对私有方法和变量的访问。
在 Mocha 中测试私有方法需要使用一些工具来访问和调用模块的私有方法。其中,rewire 是其中之一,它可以让我们轻松地访问和修改模块中的私有变量和私有方法。
以下是使用 rewire 测试 Mocha 中的私有方法的详细步骤:
-
安装 rewire 库:
npm install rewire --save-dev -
导入需要测试的模块和 rewire 库:
const assert = require('assert'); const rewire = require('rewire'); const module = rewire('./module'); // 替换为要测试的模块路径 -
使用 rewire 来访问私有方法:
const privateMethod = module.__get__('privateMethod'); -
编写测试用例(describe和it块):
describe('Private Method', () => { it('should return expected result', () => { // 调用私有方法 const result = privateMethod(); // 断言结果是否符合预期 assert.strictEqual(result, 'expected result'); }); }); -
运行测试用例:
使用 Mocha 运行测试用例,可以使用命令行工具或集成到构建工具中。例如,在命令行中执行以下命令:
$ mocha test.jsMocha将执行测试用例并显示测试结果。
通过使用 rewire 库,我们可以轻松地访问和测试 Mocha 中的私有方法。通过调用 module.__get__('methodName'),我们可以获取并使用私有方法。这样我们就可以编写针对私有方法的测试用例,并验证其行为是否符合预期。
注意:测试私有方法可能会破坏封装性和模块的内部实现。在进行测试时,确保只关注对外可见的行为和公共接口,而不仅仅是内部实现的细节。同时,也要意识到使用`来测试私有方法可能会导致测试代码与实际实现之间的紧耦合。因此,在测试私有方法时要谨慎权衡测试的必要性和稳定性问题。
33.2 自动化测试和持续集成
在 Node.js 中,可以使用各种工具和框架来实现自动化测试和持续集成。下面是常用的工具和框架的简介:
- 自动化测试工具:
- Mocha:是一个功能丰富的 JavaScript 测试框架,支持异步测试,并提供了丰富的断言风格。可以配合其他库(如Chai、Sinon等)进行更全面的测试。
- Jest:是一个易于使用的 JavaScript 测试框架,内置了断言和Mock功能,并且支持快照测试和覆盖率报告等特性。
- Ava:是一个并发执行的 JavaScript 测试运行器,具有简洁语法和快速执行的特点。
- 持续集成工具:
- Travis CI:是一个基于云的持续集成服务,与GitHub集成紧密。它可以在每次代码提交后自动触发构建和测试过程,并提供了丰富的配置选项和报告结果。
- Jenkins:是一个开源的持续集成工具,可以通过插件扩展其功能。它支持多种构建工具和测试框架,并提供了灵活的配置和可视化界面。
在实践中,一般的步骤如下:
- 编写测试用例:使用选择的测试框架编写单元测试、集成测试或端到端测试的测试用例。
- 配置自动化测试工具:配置测试框架和相关工具,使其能够执行测试用例并生成测试报告。
- 集成持续集成工具:将项目与持续集成工具(如Travis CI、Jenkins)进行集成,配置触发条件、构建脚本等。
- 提交代码并触发测试:将代码提交到版本控制系统,并通过持续集成工具自动触发构建和测试过程。
- 查看测试结果:查看持续集成工具生成的测试报告、日志和覆盖率等结果,以便及时发现问题并进行修复。
通过自动化测试和持续集成,可以提高开发效率、保证代码质量,并为团队协作提供支持。
33.2.1 自动化测试
使用 Makefile 来完成测试可以使测试任务更加自动化和可靠化。下面是一个的 Makefile 文件的内容:
# 定义变量
SRC_DIR = src
TEST_DIR = test
REPORT_DIR = reports
# 定义测试相关的命令和选项
MOCHA = ./node_modules/.bin/mocha
MOCHA_OPTS = --recursive --reporter spec --timeout 5000 --exit
# 默认任务
.PHONY: test
test:
$(MOCHA) $(MOCHA_OPTS)
# 生成测试报告
.PHONY: test-report
test-report:
$(MOCHA) $(MOCHA_OPTS) --reporter mochawesome --reporter-options reportDir=$(REPORT_DIR)
# 清理测试报告
.PHONY: clean
clean:
rm -rf $(REPORT_DIR)
在这个示例中,我们假设项目代码位于 "src" 目录下,测试代码位于 "test" 目录下,测试报告将生成在 "reports" 目录下。
Makefile 中定义了三个任务:
- test:运行所有的测试用例。它使用了 Mocha 命令行工具,并指定了一些常用的选项,例如递归搜索测试文件、使用
"spec"格式的报告输出、设置超时时间和退出选项等。 - test-report:生成测试报告。除了运行测试用例外,它还使用了 Mocha 的 mochawesome 报告器,并指定了报告生成的目录为
"reports"。 - clean:清理测试报告。它会删除之前生成的测试报告。
你可以根据实际情况修改Makefile中的变量和选项,以适应你的项目需求。
使用 Makefile 运行测试非常简单,只需要在终端中执行 make test 命令即可。如果你想生成测试报告,可以执行 make test-report 命令。如果需要清理测试报告,可以执行 make clean 命令。
下面将详细介绍如何使用 Makefile 来完成测试:
-
设置变量:首先,你需要设置一些变量,以便在
Makefile中引用它们。例如,你可能需要设置源代码目录、测试代码目录、测试报告目录等。SRC_DIR = src TEST_DIR = test REPORT_DIR = reports -
定义测试相关的命令和选项:在
Makefile中,你需要定义执行测试相关的命令和选项。这通常会涉及到使用测试框架的命令行工具,并指定一些选项,如递归搜索测试文件、选择报告格式、设置超时时间等。下面是一个Mocha测试框架的示例:MOCHA = ./node_modules/.bin/mocha MOCHA_OPTS = --recursive --reporter spec --timeout 5000 --exit -
定义默认任务:默认任务是在执行
make命令时自动执行的任务。在测试的情况下,你可以定义一个名为test的默认任务,用于运行所有的测试用例。该任务会调用测试框架的命令行工具,使用之前定义的命令和选项来执行测试。.PHONY: test test: $(MOCHA) $(MOCHA_OPTS) -
定义生成测试报告的任务(可选):如果你希望生成测试报告,你可以定义一个名为
test-report的任务。该任务除了运行测试用例外,还会使用测试框架的报告器,并将报告生成到指定的目录中。.PHONY: test-report test-report: $(MOCHA) $(MOCHA_OPTS) --reporter mochawesome --reporter-options reportDir=$(REPORT_DIR) -
定义清理任务(可选):如果你希望在每次执行测试之前清理之前生成的测试报告,你可以定义一个名为
clean的任务。该任务会删除之前生成的测试报告目录。.PHONY: clean clean: rm -rf $(REPORT_DIR) -
运行测试:通过在终端中执行
make test命令,即可运行所有测试用例。$ make test -
生成测试报告(可选):如果你希望生成测试报告,可以执行
make test-report命令。这将运行所有的测试用例,并生成相应的测试报告。$ make test-report -
清理测试报告(可选):如果你想清理之前生成的测试报告,可以执行
make clean命令。这将删除之前生成的测试报告目录$ make clean
之后代码改动只需手动执行 make test 就可以完成复杂的单元测试和覆盖率等。
注意:
1.Markfile的缩进是必须是 Tab,不要使用空格。
2.需要在包的描述文件配置 blanket。
{
"name": "myproject",
"version": "1.0.0",
"description": "A example project using Node.js",
"author": "John Doe",
"license": "MIT",
"dependencies": {
"blanket": "^1.2.3"
},
"scripts": {
"test": "mocha --require blanket"
}
}
在上述示例中,我们在 dependencies 字段中添加了 "blanket": "^1.2.3",指定了 blanket 的依赖项及其版本范围。
我们定义了一个 test 脚本,它使用 mocha 测试框架,并在运行测试之前通过 --require blanket 选项加载 blanket 模块来收集测试覆盖率信息。
然后,你可以运行 npm test 命令来执行测试脚本并生成测试覆盖率报告。
33.2.2 持续集成
Travis CI 是一个持续集成(Continuous Integration,CI)平台,它可以帮助开发者自动化构建、测试和部署他们的软件项目。Travis CI 的主要目标是提供一个简单易用的平台,以减轻开发者在创建和维护持续集成流程上的负担,从而加速软件开发周期并提高代码质量。
下面是 Travis CI 的基本工作流程:
-
创建配置文件:在项目根目录下创建名为
.travis.yml的配置文件。这个文件定义了构建和测试的环境、脚本和其他相关设置。 -
将代码推送到版本控制系统:将代码推送到支持的版本控制系统(如 GitHub 或 Bitbucket),确保在仓库中启用了 Travis CI 服务。
-
触发构建任务:一旦代码被推送到版本控制系统,Travis CI 将检测到这个变化并触发构建任务。
-
创建构建环境:Travis CI 根据
.travis.yml中的配置信息,在云服务商(如 AWS、GCP 等)上创建一个虚拟机或容器,作为构建环境。 -
运行构建脚本:Travis CI 在构建环境中执行 .travis.yml 中定义的构建脚本。这些脚本可以包括安装依赖项、编译代码、运行测试等任务。
-
运行测试:在构建过程中,Travis CI 可以使用项目中定义的测试框架或工具运行测试用例。它会收集测试结果并生成相应的报告。
-
报告构建结果:一旦构建和测试完成,Travis CI 将根据配置将构建结果(如成功、失败、错误信息等)反馈给开发者。
-
自动化部署(可选):如果需要,Travis CI 还可以在构建成功后自动部署代码到指定的服务器、云平台或容器环境中。
下面是一个基本的 .travis.yml 配置文件示例:
language: node_js
node_js:
- "12"
- "14"
- "16"
cache:
directories:
- "node_modules"
install:
- npm install
script:
- npm run lint # 运行代码静态检查
- npm run build
- npm test # 运行测试套件
在这个示例中,我们指定了项目使用的编程语言和要测试的 Node.js 版本。然后,我们定义了需要缓存的 node_modules 目录,以避免重复安装依赖。接着,在 install 阶段,我们使用 npm install 命令安装项目的依赖项。最后,在 script 部分,我们定义了需要运行的构建脚本命令,包括 npm run build 用于构建项目,并在 script 部分运行 npm test 命令来执行测试。您需要确保在 package.json 文件的 scripts 字段中定义了 "test" 命令,并且该命令能够正确地运行您的测试脚本。
当你将这个 .travis.yml 文件提交到 GitHub 仓库后,Travis CI 将会读取该文件并根据其中的配置执行构建任务。它会按照你定义的顺序运行构建脚本,并根据结果报告构建状态。
上述配置文件包含以下内容:
- language: node_js:指定项目使用的编程语言为 Node.js。
- node_js: :指定项目需要测试的 Node.js 版本。在上述示例中,我们指定了三个版本分别为 12、14 和 16。
- cache::指定需要缓存的目录或文件。
- directories::指定需要缓存的目录名称。在上述示例中,我们缓存了
node_modules目录。 - install::指定安装依赖的命令,例如
npm install。 - script::指定测试脚本的命令,例如
npm run test。
此外,还可以通过 .travis.yml 文件中的其他配置项来定制化构建流程,如环境变量、通知设置等。例如,在 Node.js 项目中,可以使用以下代码段设置环境变量:
env:
- NODE_ENV=production
- DB_HOST=localhost
以上代码将设置两个环境变量 NODE_ENV 和 DB_HOST。在构建过程中,这些变量将被注入到项目中,并可以在程序中使用。
Travis CI 提供了丰富的文档和示例,以帮助开发者快速上手和配置他们的项目。它支持多种编程语言和开发环境,并与主流的版本控制系统集成,如 Git、Mercurial 等。此外,Travis CI 还提供了许多功能和插件,例如可视化构建状态、通知和日志管理,以满足不同项目的需求。
33.3 性能测试
Node.js 的性能测试是评估 Node.js 应用程序在各种负载下的性能、稳定性和响应能力的过程。性能测试可以帮助开发者识别瓶颈、优化代码以提高性能,并确保应用程序在生产环境中有良好的表现。
以下是进行 Node.js 性能测试时常用的工具和技术:
-
基准测试(Benchmarking):基准测试是对特定功能或代码片段的性能进行精确测量的过程。Node.js 提供了
perf_hooks模块,它包含了 Performance Timing API,可以用于测量函数执行时间、事件触发时间等。另外,您还可以使用第三方基准测试库如benchmark.js来进行更复杂的性能测试。下面是进行 Node.js 基准测试的一般步骤:
-
确定测试目标:首先,您需要明确要测试的目标是什么,例如某个函数、模块或代码片段的性能。确保您明确测试的目标,这样可以使测试过程更加有针对性。
-
编写测试用例:根据测试目标,编写相应的测试用例。测试用例应该包含一系列预定义的操作,例如函数的调用、计算或数据库查询等。测试用例应该具有代表性,能够模拟真实场景中的典型操作。
-
使用性能计时器:Node.js 提供了
perf_hooks模块,其中包含了 Performance Timing API,用于测量函数执行时间和事件触发时间。使用性能计时器可以精确地测量代码的执行时间,从而评估性能。const { PerformanceObserver, performance } = require('perf_hooks'); // 创建性能观察器 const obs = new PerformanceObserver((items) => { console.log(items.getEntries()[0].duration); performance.clearMarks(); }); obs.observe({ entryTypes: ['measure'] }); // 在要测试的代码片段前后添加性能标记,这些标记用于计算代码片段的执行时间 performance.mark('start'); // 执行要测试的代码片段 // ... performance.mark('end'); // 创建性能测量 performance.measure('My Benchmark', 'start', 'end');通过使用perf_hooks模块对代码片段进行性能测试,并输出代码片段的执行时间。
-
运行基准测试:运行编写好的测试用例,并收集测试结果。可以多次运行测试用例,然后计算平均值以获得更准确的性能数据。您可以手动运行测试用例,也可以使用第三方基准测试库如
benchmark.js来进行更复杂的基准测试。const Benchmark = require('benchmark'); const suite = new Benchmark.Suite(); // 添加测试用例 suite.add('Test Case 1', () => { // 执行要测试的代码片段 }); suite.add('Test Case 2', () => { // 执行要测试的代码片段 }); // 设置测试完成后的回调函数 suite.on('complete', function () { for (let i = 0; i < this.length; i++) { console.log(this[i].toString()); } }); // 运行基准测试 suite.run({ async: true });通过使用 Benchmark.js 库来创建测试套件,并添加多个测试用例进行基准测试。在测试完成后,会触发回调函数将每个测试用例的结果打印
-
分析和优化:根据基准测试的结果,分析性能数据并进行优化。可以根据测试结果中的执行时间、吞吐量等指标来判断哪些部分需要优化,并针对性地进行代码调整和性能优化。
进行基准测试时,还有一些注意事项:
- 确保在相同的硬件和软件环境下运行测试,以确保结果的可比性。
- 关闭不必要的后台进程和服务,以避免对性能测试的干扰。
- 运行基准测试之前,确保代码已经进行了适当的性能优化和代码审查。
基准测试是一个持续的过程,可以随着项目的发展和需求的变化进行定期的性能测试和优化。通过基准测试,您可以更好地了解代码的性能,并做出针对性的优化,以提高 Node.js 应用程序的性能和响应能力。
-
-
负载测试(Load Testing):负载测试是模拟真实用户行为和大量请求来评估系统在压力下的表现。常用的负载测试工具包括 ApacheBench、Siege、Loader.io 等。这些工具可用于模拟并发用户和大量请求,以评估服务器的响应时间、吞吐量和错误率。
-
内存分析(Memory Profiling):内存分析是检测和解决内存泄漏及高内存消耗问题的过程。Node.js 提供了 v8 模块,通过其中的内置 API 可以监控内存使用情况。此外,您还可以使用专门的内存分析工具如 heapdump、memwatch-next 来进行详细的内存分析。
-
CPU 分析(CPU Profiling):CPU 分析用于评估代码中的 CPU 使用情况。Node.js 的 perf_hooks 模块提供了 CPU 分析器,可以用于检测 CPU 使用高峰和瓶颈。此外,工具如 ndb、node-inspector 和 Chrome 开发者工具的 CPU 面板也可以帮助您进行 CPU 分析。
-
压力测试(Stress Testing):压力测试是通过增加负载和并发用户来推动系统达到极限,以评估其性能和稳定性。压力测试工具如 Artillery、wrk 和 Loader.io 可以模拟大规模的请求和并发用户,以测试系统在高负载下的表现。
进行性能测试时,您需要根据应用程序的特点和需求选择合适的工具和技术。性能测试不仅可以帮助您发现潜在的性能问题,还可以验证优化措施的有效性。通过进行全面的性能测试,您可以更好地了解应用程序在不同负载下的表现,并做出相应的优化和调整。
总结
当进行 Node.js 测试时,可以使用各种工具和库来编写和运行测试。以下是对 Node.js 测试的一些总结:
-
测试框架:Mocha 是一个流行的 JavaScript 测试框架,可用于编写和运行 Node.js 测试用例。它提供了丰富的断言库和钩子函数,可以方便地组织和执行测试套件。
-
断言库:断言库用于编写断言,以验证代码的行为是否符合预期。在 Node.js 中,常用的断言库有 Node.js 内置的 assert 模块以及Chai 和 Should.js 等,这些库提供了不同的断言风格和功能,可以根据个人喜好选择。
-
测试覆盖率:测试覆盖率工具可用于衡量测试代码对源代码的覆盖程度。在 Node.js 中,常用的测试覆盖率工具有Istanbul、nyc和Jest等。这些工具可以生成详细的测试覆盖率报告,帮助开发者了解测试用例的质量和覆盖范围。
-
异步测试:由于 Node.js 的异步特性,编写异步测试是非常常见的。为了处理异步代码,Node.js 提供了多种方式,如使用回调函数、Promise、async/await等。此外,还可以使用 Sinon.js 等库来模拟异步操作和创建测试替身。
-
持续集成:持续集成是一种将代码频繁集成到主干的开发实践。在 Node.js 中,可以使用 Travis CI、Jenkins、CircleCI 等持续集成工具来自动运行测试并生成报告。这样可以确保每次提交的代码都经过了测试,并且及时发现和修复问题。
-
Mocking和Stubbing:在测试过程中,可能需要模拟一些外部依赖或创建假对象来隔离被测代码。Sinon.js是一个流行的库,用于创建测试替身,如模拟函数调用、捕获函数调用和设置返回值等。
-
性能测试:除了功能测试,性能测试也是 Node.js 开发中的重要环节。工具如 Artillery、Loadtest 和 Autocannon 等可用于对 Node.js 应用程序进行压力和性能测试,以验证其在高负载和高并发情况下的表现。
Node.js 测试是开发过程中不可或缺的一部分。通过使用合适的工具和编写全面的测试用例,可以提高代码质量、减少错误,并确保应用程序在各种情况下都能正常工作。
34-使用TypeScript
TypeScript 是一种由微软开发的开源编程语言,它是 JavaScript 的一个超集。它通过引入静态类型系统和其他新的语言特性,为 JavaScript 提供了更好的可读性、可维护性和可扩展性。TypeScript 兼容现有的 JavaScript 代码,可以无缝地与 JavaScript 库和框架进行集成。
在 Node.js 中使用 TypeScript 可以让你在编写 JavaScript 代码时获得强大的类型检查和其他高级语言功能。以下是详细介绍在 Node.js 中使用 TypeScript 的步骤:
34.1 安装 TypeScript
首先,你需要通过 npm 全局安装 TypeScript。在命令行中运行以下命令:
npm install -g typescript
34.2 初始化 TypeScript 项目
在你的 Node.js 项目目录下,可以运行以下命令初始化一个 TypeScript 项目
tsc --init
这将在项目根目录下生成一个名为 tsconfig.json 的配置文件,用于配置 TypeScript 编译器的设置。
34.3 tsconfig.json
tsconfig.json 是 TypeScript 编译器的配置文件,用于指定 TypeScript 项目的编译选项和文件包含规则。该文件位于 TypeScript 项目的根目录下。
以下是一个示例的 tsconfig.json 文件内容:
{
"compilerOptions": {
"target": "es5",
"module": "commonjs",
"outDir": "dist",
"strict": true
},
"include": ["src/**/*.ts"],
"exclude": ["node_modules"]
}
让我们逐个解释这些常见的配置选项:
- “compilerOptions”:这是一个对象,包含用于配置 TypeScript 编译器的选项。
- “target”:指定编译后 JavaScript 代码的目标版本。在示例中,目标版本为 ES5。
- “module”:指定模块的生成方式。在示例中,使用 CommonJS 格式。
- “outDir”:指定编译后的 JavaScript 文件输出目录。在示例中,输出目录为
dist文件夹。 - “strict”:启用严格的类型检查。在示例中,严格模式已启用。
- “include”:指定应包含在编译中的文件或文件夹。在示例中,将编译
src文件夹下的所有.ts文件。 - “exclude”:指定应排除在编译中的文件或文件夹。在示例中,排除了
node_modules文件夹。
在 TypeScript 中,可以通过配置文件来设置 ESM(ECMAScript Modules) 和 CJS(CommonJS)的模块系统。以下是配置 TypeScript 项目使用 ESM 和 CJS 的方法:
-
ESM 配置
ESM(ECMAScript Modules)是 ECMAScript 6 标准中定义的模块系统,支持导出和导入 ES6 模块。ESM 使用
import和export关键字来定义和使用模块。{ "compilerOptions": { "target": "es6", "module": "esnext", "moduleResolution": "node", "esModuleInterop": true, "outDir": "./dist" }, "include": ["src"] }在上面配置中,将
module设置为esnext,这样可以在文件中使用import和export关键字来导入和导出模块。-
在需要使用 ESM 的文件中,可以使用以下代码来导入模块:
import fs from 'fs'; -
在需要导出模块的文件中,可以使用以下代码来导出模块:
export default myFunction;注意:在 Node.js 中使用 ESM 时,不支持直接导出多个变量或值。如果需要导出多个值,可以通过导出一个对象来实现。例如:
export { a, b, c };
在ESM中,打包后的文件格式是 ES6 模块(即标准的JavaScript模块),其扩展名为
.js或.mjs。ES6模块使用静态导入和导出语句,因此打包后的代码可以被静态分析和优化,从而提高性能。 -
-
CJS 配置
CJS(CommonJS)是 Node.js 中使用的模块系统 (在 Node.js 中,默认情况下使用的是 CJS 模块系统。),支持导出和导入 CommonJS 模块。CJS 使用
require()函数来引入模块,使用module.exports来导出模块。{ "compilerOptions": { "target": "es6", "module": "commonjs", "outDir": "./dist" }, "include": ["src"] }在上面配置中,将
module设置为commonjs,这样可以在文件中使用require()函数来导入模块,使用module.exports来导出模块。在 CJS 中,打包后的文件格式是 CommonJS 模块,其扩展名为
.js或.cjs。CommonJS 模块使用动态的require()函数来加载模块,并使用module.exports来导出模块。因此,打包后的代码不能被静态分析和优化,从而可能影响性能。
通过以上方式配置 ESM 和 CJS 的模块系统,可以在项目中灵活地使用不同的模块系统,并根据具体情况进行配置。
你可以根据项目的需求和特定的 TypeScript 配置选项对 tsconfig.json 进行自定义。例如,你可以根据需要更改目标版本、模块系统、输出目录等。
34.4 编写 TypeScript 代码
现在,你可以开始编写 TypeScript 代码。创建一个 .ts 文件,并使用 TypeScript 的语法来编写代码。例如:
// app.ts
function greeter(name: string) {
return "Hello, " + name;
}
let user = "World";
console.log(greeter(user));
34.5 编译 TypeScript 代码
一旦编写了 TypeScript 代码,你需要将其编译成 JavaScript 代码,以便在 Node.js 中运行。在命令行中运行以下命令来进行编译:
tsc app.ts
或者,如果你有多个 TypeScript 文件,可以直接运行 tsc 命令来编译整个项目:
tsc
这将根据 tsconfig.json 中的配置对整个项目进行编译。
34.6 运行编译后的 JavaScript 代码
一旦 TypeScript 代码被成功编译成 JavaScript 代码,你就可以像平常一样在 Node.js 中运行它。例如:
node app.js
34.7 高级特性
TypeScript 还支持许多高级特性,如类、接口、泛型、装饰器等。你可以根据需要深入学习这些特性,并在 Node.js 项目中应用它们。
以上是在 Node.js 中使用 TypeScript 的基本步骤。通过使用 TypeScript,可以在 Node.js 项目中获得更好的类型安全性和更清晰的代码结构。如果还想了解更多的有关 TypeScript 的相关知识,欢迎随时访问 TypeScript入门教程。
总结
Node.js 结合 TypeScript 可以提供更好的开发体验和代码可维护性。通过使用 TypeScript,可以更早地发现潜在的错误和问题,并提高代码质量和可读性。同时,TypeScript 也为现代IDE提供了更好的支持,使开发人员能够更高效地编写和维护代码。
35-项目工程化
Node.js 项目工程化是指将一个 Node.js 项目组织、管理和构建成一个可维护和可扩展的整体,以提高开发效率、代码质量和团队协作。下面将详细讲解 Node.js 项目工程化的各个方面:
35.1 目录结构
合理的目录结构是项目工程化的基础。一个典型的 Node.js 项目通常包括 src(源代码)、config(配置文件)、test(测试文件)、public(静态资源文件)、scripts(构建脚本和辅助脚本)、package.json(项目配置文件)等目录。合理的目录结构可以帮助开发者清晰地组织和定位项目中的各个部分。
以下是一种常见的目录结构示例:
|- src/ # 源代码目录
| |- controllers/ # 控制器
| |- models/ # 数据模型
| |- routes/ # 路由
| |- services/ # 服务层
| |- dao/ # 数据访问层
|- config/ # 配置文件
|- test/ # 测试文件
|- public/ # 静态资源文件
|- scripts/ # 构建脚本和辅助脚本
|- package.json # 项目配置文件
|- README.md # 项目说明文档
为了方便管理和维护,建议将项目按照功能模块划分成多个文件夹,每个文件夹包含自己的代码和依赖项。同时,使用合适的架构模式(如 MVC、MVP、MVVM)来组织代码,将业务逻辑、数据访问和视图分离。
35.2 模块化开发
使用模块化开发可以提高代码的可维护性和复用性。可以使用 CommonJS 或 ES Modules 来组织和导入模块。将功能模块化,使其独立、可测试和可重用。
35.3 依赖管理
使用包管理器(如 npm 或 yarn)来管理项目的依赖关系。通过 package.json 文件定义项目的依赖项和脚本命令。使用锁定文件(如 package-lock.json 或 yarn.lock)确保团队成员之间的版本一致性,同时可以使用 .npmrc 或 .yarnrc 等文件进行包管理器的配置。
35.4 配置管理
使用配置文件来管理项目的配置选项,例如数据库连接、API 密钥等。可以使用环境变量、.env 文件或专用的配置模块来管理敏感信息和不同环境的配置。常见的配置管理工具包括 dotenv、config 等。
35.5 日志记录
添加日志记录功能,以便在开发和生产环境中捕获和跟踪错误。可以使用现成的日志库(如 winston、pino、log4js 等)来记录日志,并设置适当的日志级别和输出目标。
35.6 测试和质量保证
编写测试代码并执行自动化测试是项目工程化的重要组成部分。使用测试框架(如 Mocha、Jest 等)编写单元测试、集成测试和端到端测试。考虑使用代码覆盖率工具(如 Istanbul)来衡量测试覆盖率。
35.7 构建和部署
使用构建工具(如 Webpack、Rollup 等)将源代码打包、转换和优化,以便在生产环境中使用。自动化构建过程,并使用持续集成和持续交付(CI/CD)工具来部署应用程序。
35.7.1 Makefile
使用 Makefile 构建 Node.js 应用程序可以简化构建过程并提供可重用的构建规则。Makefile 是一个文本文件,其中包含了一系列规则和命令,用于根据源代码生成目标文件或执行其他任务。
下面是一个简单的 Makefile 示例,用于构建 Node.js 应用程序:
# 定义变量
SRC_DIR := src
BUILD_DIR := build
APP_NAME := myapp
# 定义目标
all: clean build
# 清理构建目录
clean:
rm -rf $(BUILD_DIR)
# 构建应用程序
build:
npm install
mkdir -p $(BUILD_DIR)
cp -R $(SRC_DIR)/* $(BUILD_DIR)
# 运行应用程序
run:
node $(BUILD_DIR)/index.js
在上面的示例中,Makefile 定义了三个主要的目标:clean、build 和 run。
-
clean目标用于清理构建目录,通过rm -rf命令删除$(BUILD_DIR)目录及其所有内容。 -
build目标用于构建应用程序。它首先通过npm install命令安装项目所需的依赖项。然后,使用mkdir -p命令创建构建目录$(BUILD_DIR)。接下来,通过cp -R命令将源代码从$(SRC_DIR)复制到构建目录。 -
run目标用于运行应用程序。它使用 node 命令运行构建目录中的index.js文件。
此外,Makefile 还定义了一些变量,如SRC_DIR(源代码目录)、BUILD_DIR(构建目录)和 APP_NAME(应用程序名称)。通过使用变量,可以轻松地根据项目需求进行配置。
要使用 Makefile 构建 Node.js 应用程序,只需在项目根目录中创建一个名为 Makefile 的文件,并将上述内容添加到其中。然后,可以使用 make 命令执行 Makefile 中定义的目标。例如,要构建应用程序,可以运行 make build 命令。
使用 Makefile 构建 Node.js 应用程序的好处是可以将构建过程自动化,并且可以轻松地扩展和定制构建规则。通过定义目标和命令,可以实现构建、测试、部署等各种任务,并根据需要添加更多的规则。这样,可以提高开发效率并确保应用程序的稳定构建。
35.7.2 Webpack
Webpack 是一个强大的模块打包工具,虽然主要用于前端应用程序的打包,但也可以用于打包 Node.js 应用程序。下面是介绍如何使用 Webpack 打包 Node.js 应用程序的步骤:
-
初始化项目:首先,需要在项目根目录中初始化一个 Node.js 项目。可以使用
npm init或yarn init命令创建package.json文件,并设置项目的基本信息和依赖项。 -
安装Webpack:使用以下命令在项目中安装 Webpack 及其相关插件:
npm install webpack webpack-cli --save-dev这将安装
Webpack及其命令行工具(webpack-cli)作为开发依赖项。 -
创建 Webpack 配置文件:在项目根目录中创建一个名为
webpack.config.js的文件,并添加以下内容:const path = require('path'); module.exports = { target: 'node', entry: './src/index.js', output: { filename: 'bundle.js', path: path.resolve(__dirname, 'dist') }, // 可选的配置项 resolve: { extensions: ['.js'] // 支持导入省略后缀的js文件 }, // 可选的加载器配置 module: { rules: [ { test: /\.js$/, exclude: /node_modules/, use: { loader: 'babel-loader', options: { presets: ['@babel/preset-env'] } } } ] } };在上面的配置文件中,我们指定了 Webpack 的一些基本配置:
- target: ‘node’:指定打包目标为 Node.js 环境。
- entry: ‘./src/index.js’:指定入口文件,这里假设入口文件是
src/index.js。 - output:指定输出文件的名称和路径。
- resolve:可选配置项,用于设置模块导入时的解析规则。在这里,我们配置了支持导入省略后缀的 JavaScript 文件。
- module:可选配置项,用于定义加载器规则。在这里,我们定义了一个加载器规则,使用Babel加载器(babel-loader)来处理
.js文件,并使用@babel/preset-env预设进行转换。
-
创建源代码:在
src目录下创建 Node.js 应用程序的源代码文件。例如,创建一个名为index.js的文件,并添加一些 Node.js 代码。 -
运行Webpack:在终端中运行以下命令,使用 Webpack 打包 Node.js 应用程序:
npx webpack --config webpack.config.js这将执行 Webpack,根据配置文件中的设置来打包应用程序。打包后的文件将生成在
dist目录下,名称为bundle.js。 -
运行打包后的应用程序:使用以下命令在终端中运行打包后的应用程序:
node dist/bundle.js
通过以上步骤,你就可以使用 Webpack 成功地打包 Node.js 应用程序。Webpack 提供了丰富的功能和插件系统,可以进一步定制和优化打包过程。你可以根据项目需求,添加更多的加载器和插件来处理其他类型的文件和任务,例如CSS、图片处理、代码压缩等。同时,Webpack 还支持热模块替换(Hot Module Replacement)等高级特性,可以提供更好的开发体验和构建效率。
35.8 文档和注释
编写清晰的文档和注释,以便团队成员能够理解和维护项目。使用 JSDoc 注释来生成 API 文档,使用 Markdown 编写项目的 README 文档。
35.9 代码风格和规范
使用代码风格指南(如 Airbnb JavaScript Style Guide)来保持代码的一致性和可读性。使用代码静态分析工具(如 ESLint)来强制执行代码规范。
35.10 版本控制
使用版本控制系统(如 Git)来管理项目的源代码,并使用合适的分支策略和代码合并流程。确保团队成员遵循良好的代码提交和代码审查实践。
总结
通过对 Node.js 项目进行工程化,可以提高项目的可维护性和可扩展性,减少bug的产生,加快开发速度,并提升团队的协作效率。工程化还可以使项目更易于理解和维护,降低项目的长期维护成本。因此,在开发 Node.js 项目时,合理规划项目结构,使用适当的工具和技术,实施工程化是非常重要的。
36-性能优化和安全性
Node.js 是一个非常流行的服务器端 JavaScript 运行环境,广泛应用于 Web 开发、后端服务等领域。在实际开发过程中,性能优化和安全性是 Node.js 应用程序必须关注的两个方面。
36.1 缓存和CDN加速
缓存和CDN加速是两种常见的网站性能优化技术,它们都旨在提高网站的访问速度和用户体验。Node.js 是一种基于 JavaScript 的运行时环境,主要用于构建服务器端和网络应用程序。在 Node.js 中,可以使用一些模块来实现缓存和 CDN 加速的功能。下面分别介绍 Node.js 中的缓存和 CDN 加速的实现方式。
36.1.1 缓存
缓存是一种将数据存储在临时存储介质中,以便快速访问的技术。在网站中,缓存可以将经常请求的静态资源(如图片、CSS、JavaScript文件等)保存在缓存服务器或用户终端设备上,当下次请求同一个资源时,可以直接从缓存中获取,避免了重新请求和传输资源的时间消耗。缓存的原理如下:
-
客户端缓存:浏览器可以通过设置HTTP头信息中的缓存策略,将响应中的静态资源缓存在本地。当再次请求同一个资源时,浏览器会先检查缓存是否过期,如果没有过期,则直接从缓存中读取资源,减少了网络传输时间。
-
代理服务器缓存:代理服务器(如反向代理服务器、负载均衡器等)可以缓存经常请求的资源,当有用户请求相同资源时,代理服务器可以直接返回缓存的资源,减轻了源服务器的负载和网络带宽消耗。
-
数据库查询缓存:数据库服务器可以缓存查询结果,当下次有相同的查询请求时,可以直接返回缓存中的结果,提高了数据库查询的性能。
适用场景:
- 静态资源:对于不经常变动的静态资源(如图片、样式表、脚本文件等),可以使用缓存来减少网络传输时间和服务器负载。
- 数据库查询:对于频繁执行的数据库查询,可以使用数据库查询缓存来提高查询性能。
Node.js 提供了一些内置的模块和第三方模块,可以用于实现缓存功能。以下是几种常见的缓存实现方式:
-
内存缓存:使用 Node.js 内置的缓存模块(如 MemoryCache)或第三方模块(如
node-cache)可以将数据保存在内存中,并设置过期时间。当下次请求相同的数据时,可以直接从内存中获取,避免了重新计算或查询数据库的开销。const NodeCache = require("node-cache"); const myCache = new NodeCache(); // 存储数据 myCache.set("myKey", "myValue"); // 获取数据 const value = myCache.get("myKey"); -
文件缓存:使用文件系统模块(如 fs)可以将数据保存在文件中,当下次请求相同的数据时,可以直接读取文件内容,避免了重新计算或查询数据库的开销。这种方式适用于较大的数据或需要长期保存的数据。
const fs = require('fs'); // 写入数据 fs.writeFileSync('data.txt', 'Hello, world!'); // 读取数据 const data = fs.readFileSync('data.txt', 'utf8'); -
数据库缓存:使用数据库模块(如 mysql、mongodb 等)可以将经常查询的数据缓存在数据库中,当下次查询相同的数据时,可以直接从缓存中获取,减少了数据库访问的开销。
const mysql = require('mysql'); const connection = mysql.createConnection({ host: 'localhost', user: 'root', password: 'password', database: 'mydb' }); connection.query('SELECT * FROM my_table', function (error, results, fields) { if (error) throw error; // 处理结果 });
适用场景:Node.js 缓存适用于需要快速访问和减少计算或数据库开销的场景,如频繁访问的 API 接口、动态页面的数据查询等。
注意事项:
- 选择合适的缓存策略:根据数据的访问频率、更新频率以及对实时性的要求,选择合适的缓存方式,如内存缓存、文件缓存或数据库缓存。
- 设置合理的缓存过期时间:根据业务需求和数据更新频率,设置合理的缓存过期时间,避免缓存数据过期导致的不一致性。
- 考虑缓存穿透和缓存雪崩:针对查询量大、并发高的场景,采取相应的缓存穿透和缓存雪崩防护策略,如使用布隆过滤器等技术。
36.1.2 CDN加速
CDN(Content Delivery Network)是一种分布式网络架构,通过部署在世界各地的边缘节点服务器,将网站的静态资源复制到离用户更近的服务器上,以提高访问速度和减轻源服务器的负载。CDN加速的原理如下:
-
就近访问:CDN会根据用户的地理位置,将静态资源复制到距离用户更近的边缘节点服务器上。这样,用户在请求资源时可以就近访问,减少了网络延迟和传输时间。
-
负载均衡:CDN可以根据流量情况,智能地将用户的请求分发到不同的边缘节点服务器上,实现负载均衡,避免单个服务器过载。
-
缓存优化:CDN服务器会缓存静态资源,当有用户请求相同资源时,可以直接返回缓存的资源,减少了对源服务器的请求和网络传输。
适用场景:
- 全球分发:对于需要全球范围内访问的网站或应用程序,可以使用CDN加速来提供就近访问,降低网络延迟。
- 高并发访问:对于需要处理大量并发请求的网站或应用程序,CDN可以实现负载均衡和缓存优化,提高系统的性能和可扩展性。
Node.js 也可以与 CDN(Content Delivery Network)结合使用,以实现 CDN 加速。CDN 加速是通过将静态资源(如图片、CSS、JavaScript 文件等)复制到分布在全球各地的 CDN 节点服务器上,实现就近访问和负载均衡。Node.js 可以通过以下方式与 CDN 结合使用:
-
使用静态文件中间件:Node.js 可以使用静态文件中间件(如 express.static)来处理静态资源请求。当有静态资源请求时,Node.js 可以配置 CDN 的域名作为资源的地址,使请求直接经过 CDN 节点服务器,从而实现 CDN 加速的效果。
const express = require('express'); const app = express(); app.use('/static', express.static('public')); -
配置反向代理:Node.js 可以配置反向代理服务器(如 Nginx)进行 CDN 加速。反向代理服务器可以将静态资源请求转发到 CDN 节点服务器,从而实现就近访问和负载均衡。Node.js 只需要处理动态请求,静态资源的请求由 CDN 处理。
location /static/ { proxy_pass http://cdn.example.com/; }
适用场景:CDN 加速适用于需要提高全球访问速度和减轻源服务器负载的场景,尤其是对于大型网站、应用程序或需要全球范围内访问的资源。
注意事项:
- CDN 资源优化:对于需要加速的静态资源,进行压缩、合并、缓存头设置等优化,以提高加载速度和降低带宽消耗。
- 就近访问和负载均衡:选择覆盖范围广、节点分布均匀的 CDN 服务商,实现就近访问和负载均衡,提高全球访问速度和稳定性。
- 动态内容缓存:对于动态生成的内容,结合 CDN 提供的缓存功能,实现动态内容的加速,如页面缓存、API 响应缓存等。
Node.js 缓存和 CDN 加速是常见的性能优化手段,通过合理选择缓存策略和 CDN 服务商,可以显著提升应用的访问速度和稳定性。在实际项目中,需要结合具体业务场景和需求,灵活应用这些技术手段,并不断进行性能测试和优化,以实现最佳的性能提升效果。
36.2 压缩和合并资源
在前端工程化开发中,压缩和合并资源文件是优化 Web 应用性能的常见手段。在 Node.js 中,你可以使用一些工具和技术来实现这些操作,下面详细介绍一下。
36.2.1 压缩资源
将资源文件进行压缩可以减小文件大小,从而加快文件传输速度,提高网站性能。
gzip 压缩
gzip 压缩是一种在服务器端对资源文件进行压缩的方法,使得资源文件传输时更小,更快。Node.js 提供了 zlib 模块,可以使用 gzip 压缩算法对文件进行压缩。示例代码如下:
const zlib = require('zlib');
const fs = require('fs');
const input = fs.createReadStream('input.txt');
const output = fs.createWriteStream('output.txt.gz');
input.pipe(zlib.createGzip()).pipe(output);
使用构建工具
除了 Gzip 压缩外,还可以使用构建工具对资源文件进行压缩。常见的构建工具包括 webpack、gulp 等。
以 webpack 为例,可以通过引入 compression-webpack-plugin 插件来实现对资源文件的压缩。示例如下:
const CompressionPlugin = require('compression-webpack-plugin');
module.exports = {
// ...其他配置
plugins: [
new CompressionPlugin({
test: /\.(js|css)$/i,
algorithm: 'gzip',
filename: '[path][base].gz',
}),
],
};
上述代码中,我们首先引入了 compression-webpack-plugin 插件,在 plugins 中配置了需要压缩的文件类型(.js 和 .css),压缩算法(gzip)和输出文件名格式。
36.2.2 合并资源文件
合并资源文件可以减少 HTTP 请求的数量,从而提高网站性能。Node.js 中常用的工具包括 gulp、webpack 等。
使用 gulp
gulp 是一个自动化构建工具,可以通过插件实现文件合并和压缩等操作。下面是一个实现 JavaScript 文件合并和压缩的示例:
const gulp = require('gulp');
const concat = require('gulp-concat');
const uglify = require('gulp-uglify');
gulp.task('scripts', function() {
return gulp.src('src/*.js')
.pipe(concat('all.js'))
.pipe(uglify())
.pipe(gulp.dest('dist/'));
});
上述代码中,我们首先定义了一个名为 scripts 的任务,使用 gulp.src() 方法指定需要合并的 JavaScript 文件,将文件通过 gulp-concat 插件进行合并,再使用 gulp-uglify 插件进行压缩,最后将结果通过 gulp.dest() 方法输出到目标文件夹。
使用 webpack
webpack 是一个模块打包工具,可以将多个 JavaScript 文件合并为一个或少量文件,并进行压缩和优化。下面是一个实现 JavaScript 文件合并和压缩的示例:
// webpack.config.js
const webpack = require('webpack');
const path = require('path');
module.exports = {
mode: 'production', // 开启生产模式,自动压缩代码
entry: {
app: './src/index.js',
},
output: {
filename: '[name].bundle.js',
path: path.resolve(__dirname, 'dist'),
},
plugins: [
new webpack.optimize.AggressiveMergingPlugin(), // 合并模块
],
};
上述代码中,我们首先配置了入口文件和输出文件,开启了生产模式,在 plugins 中引入了 AggressiveMergingPlugin 插件,用于合并模块。在运行 webpack 命令后,就可以将所有 JavaScript 文件合并并压缩到一个文件中。
以上是一些常用的 Node.js 工具和技术,用于压缩和合并资源文件。根据具体的项目需求和构建工具的选择,你可以灵活地应用这些技术来优化你的 Web 应用程序。
36.3 XSS和CSRF攻击防范
XSS(跨站脚本攻击)和 CSRF(跨站请求伪造攻击)是两种常见的 Web 安全威胁。
XSS 攻击是指攻击者通过在 Web 页面中插入恶意脚本(比如 JavaScript),从而使得用户在访问页面时执行这些恶意脚本,从而获取用户的敏感信息或者利用用户的身份执行一些恶意操作。XSS 攻击常常是由于没有对用户输入进行充分验证、过滤和转义处理所导致的。
CSRF 攻击是指攻击者利用受害者的身份,在受害者不知情的情况下发送恶意请求,比如以受害者的名义发送电子邮件、发起资金交易等。CSRF 攻击常常是由于没有对请求来源进行验证或者没有采取防范措施(比如使用 CSRF Token)所导致的。
当构建基于 Node.js 的 Web 应用程序时,XSS(跨站脚本攻击)和 CSRF(跨站请求伪造攻击)是两个常见的安全威胁。下面我将详细介绍如何防范这两种攻击。
36.3.1 防范 XSS 攻击
XSS 攻击是指攻击者通过在 Web 页面中插入恶意脚本(比如 JavaScript),从而使得用户在访问页面时执行这些恶意脚本,从而获取用户的敏感信息或者利用用户的身份执行一些恶意操作。
防范措施
-
输入验证和过滤:对用户输入的数据进行严格的验证和过滤,不信任任何来自用户的输入,并对输入进行适当的转义处理。
-
使用 Content Security Policy(CSP):CSP 是一项浏览器安全政策,可以帮助防止 XSS 攻击。通过在 HTTP 头中设置 CSP,可以限制浏览器加载和执行页面中的资源,从而有效地减少 XSS 攻击的风险。
-
对 Cookie 设置 HttpOnly 属性:在设置 Cookie 时,通过将 HttpOnly 属性设置为 true,可以防止 JavaScript 访问这些 Cookie,从而减少 XSS 攻击的影响范围。
-
使用安全的框架和模板引擎:选择使用经过安全审计和广泛使用的框架和模板引擎,这些工具通常会内置一些防范 XSS 攻击的机制。
36.3.2 防范 CSRF 攻击
CSRF 攻击是指攻击者利用受害者的身份,在受害者不知情的情况下发送恶意请求,比如以受害者的名义发送电子邮件、发起资金交易等。
防范措施
-
使用 CSRF Token:在每个敏感操作的表单中添加一个随机生成的 CSRF Token,并在服务器端验证这个 Token。只有当 Token 通过验证,才允许执行相应的操作。
-
同源检测:在处理敏感操作时,要对请求的来源进行检查,确保请求来自可信任的源。
-
使用 SameSite Cookie:在设置 Cookie 时,可以将 SameSite 属性设置为 Strict 或 Lax,从而限制第三方网站对 Cookie 的访问,减少 CSRF 攻击的可能性。
-
不使用 GET 请求进行敏感操作:敏感操作(比如删除、修改等)应该使用 POST、PUT、DELETE 等非幂等请求,避免使用 GET 请求。
通过以上措施,可以在 Node.js 应用程序中有效地防范 XSS 和 CSRF 攻击。除此之外,也建议定期进行安全审计,及时更新依赖项和框架,以及保持对最新安全漏洞的了解,以确保应用程序的安全性。
总结
通过合理的性能优化和综合的安全措施,可以提升 Web 应用程序的性能和安全性。在开发过程中,应该将性能优化和安全性视为同等重要的目标,并进行持续的监控和改进。
37-日志
因为部署在线上的项目无法通过打印的方式直接去查看代码哪里出问题了,只能通过日志的方式去排查问题,所以日志的显得尤为重要。日志是记录应用程序运行过程中发生的事件和错误的重要组成部分,它可以用于跟踪应用程序的行为、故障排查、性能分析和安全审计等方面。
日志记录的内容可以包括时间戳、事件描述、错误码、关联数据等。通常,日志会按照一定的格式进行记录,如文本、JSON、XML 或其他结构化格式。
Node.js 提供了一些内置的模块和第三方库,可以很方便地进行日志记录。
以下是 Node.js 中日志相关的模块和库:
-
console
console 是 Node.js 内置的一个模块,提供了一系列用于输出信息的方法,例如
console.log()、console.warn()、console.error()等。这些方法通常用于调试和快速输出信息,不适合作为长期的日志记录方式。console 日志默认打印到控制台上,也可以通过重定向控制台来将日志输出到文件中。 -
winston
winston 是一个流行的第三方库,提供了灵活的、可配置的日志记录功能。它支持多种存储方式,例如文件、数据库、邮件等,可以根据需求选择合适的存储方式。winston 还支持日志级别、日志格式等自定义设置,可以根据需求进行灵活配置。
-
log4js
log4js 是另一个流行的第三方库,也提供了丰富的日志记录功能。与 winston 不同的是,log4js 更加注重模块化和可配置性,可以将应用程序划分为不同的模块,针对每个模块进行不同的日志记录设置。log4js 支持多种输出源,包括文件、数据库、邮件等。
-
bunyan
bunyan是另一个优秀的第三方库,它提供了高性能的日志记录功能,可以处理大量的并发日志记录。bunyan支持自定义日志格式、日志级别等设置,同时支持多种存储方式,包括文件、数据库、TCP 等。bunyan还支持日志分类和子记录器,可以根据需求进行更加细粒度的日志记录。
Node.js 中的日志记录模块和库有很多,开发者可以根据自己的需求选择合适的方式进行日志记录。无论使用哪种方式,都应该注意日志的存储位置、日志级别、日志格式等方面的设置,以确保日志记录的可靠性和可读性。
37.1 访问日志
访问日志是记录用户对应用程序或系统的访问信息的日志类型。它包含了用户发起的请求以及系统对这些请求的响应,通常包括以下内容:
-
请求信息:包括请求的时间戳、客户端 IP 地址、请求方法(如 GET、POST)、请求的 URL 路径和查询参数等。
-
用户信息:如果用户已经登录,可能还会记录用户的标识信息,如用户名、用户 ID 等。
-
响应信息:包括系统对请求的处理结果,例如状态码(如 200 OK、404 Not Found)、响应的大小和格式等。
其他相关信息:如请求头部信息、浏览器信息、来源页面等。
访问日志的主要作用包括:
-
性能监控:通过分析访问日志,可以了解系统的访问模式、热点路径,从而优化系统性能和资源利用。
-
安全审计:跟踪用户的访问行为,可以帮助检测潜在的安全威胁和异常行为,进行安全审计和监控。
-
故障排查:当系统出现问题时,访问日志可以提供关于用户请求和系统响应的详细信息,有助于定位和解决故障。
-
用户行为分析:通过分析用户的访问行为,可以了解用户偏好、流量来源、页面浏览情况,为产品改进和营销决策提供数据支持。
我们以 log4js 为例介绍一下在应用中如何记录并访问日志:
-
首先,我们需要安装 log4js 模块:
npm install log4js -
然后,我们可以创建一个名为
logger.js的模块,用于配置和导出 log4js 日志记录器对象:const log4js = require('log4js'); // 配置log4js log4js.configure({ appenders: { access: { type: 'file', filename: './access.log' }, console: { type: 'console' } }, categories: { default: { appenders: ['console'], level: 'info' }, access: { appenders: ['access'], level: 'info' } } }); // 导出log4js日志记录器对象 module.exports.accessLogger = log4js.getLogger('access');在上述代码中,我们配置了一个日志记录器:
access。它将日志写入名为access.log的文件,并且在控制台输出。然后,我们通过getLogger方法导出了accessLogger对象。 -
接下来,我们可以使用这些日志记录器对象来记录请求和错误日志。我们需要在
Express应用程序中添加一个中间件,用于记录请求日志。下面是一个名为app.js的示例:const express = require('express'); const { accessLogger } = require('./logger'); // 创建一个Express应用程序 const app = express(); // 添加中间件来记录请求日志 app.use((req, res, next) => { const startTime = new Date(); // 记录请求开始时间、方法和URL accessLogger.info(`[${startTime.toISOString()}] [${req.method}] ${req.originalUrl}`); // 监听响应结束事件 res.on('finish', () => { const endTime = new Date(); const responseTime = endTime - startTime; const responseData = JSON.stringify(res.data); // 假设你有保存响应数据到res.data中 // 记录响应时间和响应内容 accessLogger.info(`[${endTime.toISOString()}] Response time: ${responseTime}ms`); accessLogger.info('Response Data:', responseData); }); next(); }); // 添加路由处理程序 app.get('/', (req, res) => { res.send('Hello, World!'); }); // 监听端口并启动应用程序 const port = 3000; app.listen(port, () => { console.log(`App listening on port ${port}`); });在上述代码中,我们首先记录了请求的开始时间、方法和URL。然后,我们通过监听响应对象的
finish事件,在响应结束时记录了响应时间和响应内容。请注意,这里我们假设将响应数据保存在res.data中,你需要根据实际情况修改这部分代码。
通过以上步骤,我们在 Node.js 应用程序中使用中间件+log4js记录了访问日志,并包括了访问时间、访问路径、请求方法、请求参数、请求头、响应时间和响应内容等详细信息。这些日志信息可以帮助你进行故障排查、性能分析和请求/响应的调试。同时,你也可以根据实际需求对日志格式和内容进行定制化处理。
37.2 异常日志
异常日志是记录应用程序在运行过程中发生的错误、异常和故障的日志。它可以帮助开发人员追踪问题、调试代码并提供故障排除信息。
日志级别是用于对日志消息进行分类和过滤的重要概念。它们定义了日志消息的重要性或优先级,并决定了哪些消息将被记录和显示。下面是常见的日志级别及其含义:
-
TRACE(跟踪):最详细的日志级别,用于记录程序的详细执行过程。通常在调试和故障排除阶段使用,包括一些细粒度的操作、变量值等信息。
-
DEBUG(调试):用于记录调试信息,以帮助开发人员查找问题。这些信息对于理解系统状态和代码流程很有帮助,但不应在生产环境中启用,以避免产生过多的日志记录。
-
INFO(信息):用于记录应用程序的关键事件和状态信息。INFO级别的日志通常用于跟踪应用程序的主要流程,例如启动、关闭和重要的业务操作。这是默认的日志级别。
-
WARN(警告):用于记录非致命性的异常或潜在的问题。警告级别的日志可以标识出一些潜在的错误情况,但不会导致应用程序的中断。
-
ERROR(错误):用于记录发生的错误,这些错误可能导致应用程序无法正常运行或执行某些功能。错误级别的日志表明应用程序发生了可恢复或不可恢复的错误。
-
FATAL(严重错误):最高级别的日志,用于记录致命的错误,这些错误导致应用程序无法继续执行或崩溃。FATAL级别的日志通常表示需要立即采取行动来修复或处理问题。
示例代码:
const log4js = require('log4js');
const logger = log4js.getLogger();
// 设置日志级别为DEBUG
logger.level = 'debug';
// 记录不同级别的日志消息
logger.trace('This is a trace message.');
logger.debug('This is a debug message.');
logger.info('This is an info message.');
logger.warn('This is a warning message.');
logger.error('This is an error message.');
logger.fatal('This is a fatal error message.');
在实际应用中,通常可以根据需求和环境将不同级别的日志记录到不同的目标,例如控制台、文件或数据库。根据应用程序的复杂性和重要性,可以灵活调整日志级别,以达到适当的日志记录量和详细程度。
下面是关于异常日志的详细介绍:
-
异常类型:
- 错误(Error):通常是由于编程错误、逻辑错误或外部依赖问题导致的异常。
- 异常(Exception):典型的是由于非预期的情况或错误的输入导致的运行时异常。
-
错误处理:
- 在 Node.js 中,可以使用 try-catch 语句块来捕获和处理异常。
- 当异常发生时,可以将其记录到异常日志中。你可以使用 log4js 或其他日志库来记录异常日志。
-
异常日志的内容:
- 时间戳:记录异常发生的时间。
- 异常类型:例如 Error 或 Exception。
- 异常信息:异常的详细描述,包括错误消息、堆栈跟踪等。
- 请求信息:如果异常与请求相关,可以记录请求的URL、方法、参数、头部等信息。
- 环境信息:记录应用程序运行的环境,如操作系统、Node.js版本、应用程序版本等。
-
记录异常日志的最佳实践:
- 使用专门的日志记录库,如log4js、winston等。
- 配置日志级别,将异常日志设置为较高的级别,以便快速发现和解决问题。
- 将异常日志保存到文件或数据库中,以便后续分析和审查。
- 在开发、测试和生产环境中使用不同的日志配置,以便在不同环境下进行适当的日志记录。
- 在异常处理中尽量提供有用的错误信息,方便排查问题和修复代码。
下面我们结合 log4js 来介绍一个异常日志的例子:
const log4js = require('log4js');
// 配置log4js
log4js.configure({
appenders: {
exceptions: { type: 'file', filename: './error.log' },
console: { type: 'console' }
},
categories: {
default: { appenders: ['console'], level: 'info' },
exceptions: { appenders: ['exceptions'], level: 'error' }
}
});
const logger = log4js.getLogger('error');
// 捕获和处理异常
try {
// 执行可能抛出异常的代码
// 记录日志
// ...
} catch (error) {
// 记录异常到日志
logger.error('An exception occurred:', error);
// 处理异常
// ...
}
在上述代码中,我们配置了一个名为 exceptions 的日志记录器,并将异常日志写入名为 exceptions.log 的文件。然后,在捕获到异常后,我们使用 logger.error 方法将异常记录到日志中。
37.3 分割日志
我们记录的日志会持续的写入文件中,随着时间的增加,这个文件将会变得非常的大,比如达到几个G以上的大小。这时我们打开这个日志文件将变得非常的缓慢,甚至可能会造成计算机内存溢出无法打开这个文件。那么怎么办呢?这时候就需要用到日志的切割,当写入一定量的日志文件,如果日志文件的大小达到一定的大小(比如10MB)就对这个日志文件进行切割,并按日期命名,那么就会解决日志文件过大的问题。
log4js 支持将日志文件按时间、大小或者日志数量进行切割。你可以使用 log4js-datefile-appender、log4js-rolling-file 或者 log4js-node-logstash等模块来实现日志切割功能。下面以 log4js-rolling-file 为例,演示如何切割日志:
const log4js = require('log4js');
const logger = log4js.getLogger();
// 配置log4js,将日志输出到文件,并按时间和文件大小切割
log4js.configure({
appenders: {
rollingFile: {
type: 'dateFile',
filename: 'logs/app.log',
pattern: '.yyyy-MM-dd-hh',
compress: true, // 是否压缩,如果为true则生成.gz后缀的日志压缩文件,默认为false
keepFileExt: true, // 滚动日志文件时保留文件扩展名,默认为false
daysToKeep: 7, // 日志保持时间
maxLogSize: 10485760, // 10MB
backups: 5 // 在日志滚动期间要保留的旧日志文件的数量,默认为5
},
console: { type: 'console' }
},
categories: {
default: { appenders: ['rollingFile', 'console'], level: 'debug' }
}
});
// 记录日志消息
logger.debug('This is a debug message.');
logger.info('This is an info message.');
logger.warn('This is a warning message.');
logger.error('This is an error message.');
在上述代码中,我们使用了 log4js-rolling-file 模块,并将输出类型设置为dateFile,即按照时间进行切割,同时还设置了 maxLogSize 属性,使得当文件大小达到指定限制时也会自动进行切割。其他配置包括文件名、切割日期格式、是否压缩、是否保留原文件后缀、保留的天数、备份个数等。
运行上述代码后,你将在logs目录下看到类似于 app.log.2022-02-21-00.gz 的日志文件,表示该文件记录了2022年2月21日0点到1点之间的日志信息。当日志文件大小达到10MB时,也会自动进行切割。
通过使用适当的日志输出器,你可以轻松实现 log4js 的日志切割功能。根据具体需求选择不同的模块和配置即可。切割日志可以避免单个日志文件过大,影响系统性能并占用磁盘空间。
37.4 日志与数据库
日志是应用程序开发和运维工作中不可或缺的一部分。它可以帮助开发人员和管理员快速定位和解决问题,同时也是监控和优化系统性能的重要手段。
为了存储和管理日志信息,通常使用日志文件和数据库两种方式。下面我们分别来详细说明这两种方式的特点和适用场景。
37.3.1 日志文件
日志文件是最常见和简单的日志存储方式,它将日志消息以文本形式写入到文件中。每条日志消息通常包含时间戳、日志级别、消息内容等信息。它的特点如下:
-
简单易用:创建和管理日志文件相对简单,只需要打开一个文件并将日志消息追加到其中即可。
-
高可靠性:日志文件通常以追加模式写入,不会覆盖已有的日志消息,保证了数据的完整性。同时,文本文件在大多数操作系统中都具有高度的稳定性。
-
可移植性:日志文件可以在不同的环境中进行传递和备份,方便在不同的系统中进行查看和分析。
-
存储占用空间较小:相比于数据库,日志文件的存储占用空间较小,对于磁盘空间的消耗较少。
适用场景:
-
单机应用程序:对于单机应用程序,使用日志文件是一种简单而有效的方式来记录应用程序的运行日志。
-
调试和故障排查:通过查看日志文件,可以定位和解决应用程序中的问题。
37.3.2 数据库
数据库是一种结构化的数据存储方式,可以将日志消息存储为表格形式的数据结构。每条日志消息通常表示为数据库表中的一行数据,包含时间戳、日志级别、消息内容等字段。它的特点如下:
-
数据分析:使用数据库存储日志消息,可以方便地进行数据分析和查询,例如按时间范围、日志级别、关键字等进行筛选和排序。
-
高可扩展性:数据库通常具有高度的可扩展性,可以处理大量的日志消息,并支持横向扩展和集群部署。
-
多用户访问:多个用户可以同时访问数据库,方便团队协作和共享日志数据。
可以对数据进行更好的加工和处理:数据库可以对日志记录进行聚合、统计、筛选等操作,从而实现更高级别的数据处理。
适用场景:
分布式系统:对于分布式系统,使用数据库来存储日志消息是一种方便和统一的方式。
高并发应用程序:对于需要处理大量并发请求的应用程序,数据库可以提供更好的性能和可扩展性。
要将日志文件写入数据库,可以使用 log4js 的 log4js-mongodb-appender 模块。这个模块允许你将日志消息存储到 MongoDB 数据库中。下面是一个示例代码,演示如何将日志文件写入到数据库:
-
首先,安装log4js-mongodb-appender模块:
npm install log4js-mongodb-appender -
然后,使用以下代码配置log4js,将日志写入到MongoDB数据库:
const log4js = require('log4js'); const logger = log4js.getLogger(); // 配置log4js,将日志输出到MongoDB数据库 log4js.configure({ appenders: { mongodb: { type: 'log4js-mongodb-appender', connectionString: 'mongodb://localhost:27017/logs', collectionName: 'logMessages' }, console: { type: 'console' } }, categories: { default: { appenders: ['mongodb', 'console'], level: 'debug' } } }); // 记录日志消息 logger.debug('This is a debug message.'); logger.info('This is an info message.'); logger.warn('This is a warning message.'); logger.error('This is an error message.');在上述代码中,我们使用了 log4js-mongodb-appender 模块,并将输出类型设置为
log4js-mongodb-appender,同时指定了 MongoDB 数据库的连接字符串和集合名称。运行上述代码后,你将在 MongoDB 数据库中看到名为logs的数据库和一张名为
logMessages的集合。集合中将保存你的日志消息。
你可以根据需求自定义 MongoDB 的连接字符串,包括主机名、端口号、数据库名称等信息。同时,你还可以在集合中添加额外的字段来记录日志的时间戳、日志级别等信息。
要同时将日志文件写入文件和数据库,你可以结合使用 log4js 的 log4js-file-appender 和 log4js-mongodb-appender 模块。这样可以将日志消息同时写入到文件和数据库中。下面是一个示例代码,演示了如何同时将日志写入文件和数据库:
-
首先,安装 log4js-file-appender 和 log4js-mongodb-appender 模块:
npm install log4js-file-appender log4js-mongodb-appender -
然后,使用以下代码配置 log4js,同时将日志输出到文件和 MongoDB 数据库:
const log4js = require('log4js'); const logger = log4js.getLogger(); // 配置log4js,将日志输出到文件和MongoDB数据库 log4js.configure({ appenders: { file: { type: 'file', filename: 'logs/app.log' }, mongodb: { type: 'log4js-mongodb-appender', connectionString: 'mongodb://localhost:27017/logs', collectionName: 'logMessages' }, console: { type: 'console' } }, categories: { default: { appenders: ['file', 'mongodb', 'console'], level: 'debug' } } }); // 记录日志消息 logger.debug('This is a debug message.'); logger.info('This is an info message.'); logger.warn('This is a warning message.'); logger.error('This is an error message.');在上述代码中,我们同时配置了
file和mongodb两个输出器,并将它们添加到appenders中。file输出器使用file类型,将日志写入到文件中,而mongodb输出器使用 log4js-mongodb-appender 模块,将日志写入到 MongoDB 数据库中。运行上述代码后,你将在
logs目录下看到名为app.log的日志文件,同时在 MongoDB 数据库中有一张名为logMessages的集合,其中包含了你的日志消息。
你可以根据需求自定义文件输出的路径和名称,以及 MongoDB 的连接字符串和集合配置。通过同时将日志写入文件和数据库,你可以方便地进行查看和分析,并且具备了数据持久化和数据查询的特性。
总结
开发者可以根据项目需求选择合适的方式来记录和访问日志,以便后续的日志分析和监控。日志文件和数据库都是常见的日志存储方式,各自具有一些特点和适用场景。在实际应用中,可以根据需求和系统规模选择合适的日志存储方式,或者将两者结合使用,将日志同时写入文件和数据库,以充分利用它们各自的优势。
38-监控
在Web应用程序中,监控和警报系统是非常重要的,它们可以帮助我们及时发现和解决潜在问题,保障应用程序的正常运行。通常,应用监控主要分为基础设施监控和应用性能监控两个方面。
基础设施监控(Infrastructure Monitoring):这一类监控主要关注应用程序运行所依赖的基础设施,包括服务器、网络设备、存储设备等。通过监控这些基础设施的状态,例如CPU利用率、内存使用情况、网络带宽等指标,可以及时发现硬件故障、资源不足或网络问题,并采取相应的措施进行维护和优化。
应用性能监控(Application Performance Monitoring,简称APM):这一类监控主要关注应用程序的性能和可用性。它涵盖了对应用程序的各个组件和功能进行监控,例如请求响应时间、事务成功率、错误率、数据库查询性能等指标。通过监控应用程序的性能指标,可以及时发现性能瓶颈、异常情况或潜在问题,并进行针对性的调整和优化。
Node.js 监控是指对 Node.js 应用程序进行实时监测、度量和分析,以了解应用程序的性能、稳定性和可用性。通过监控 Node.js 应用程序,可以及时发现潜在问题,并采取相应措施来优化应用程序的性能和可靠性。
下面是一些常见的 Node.js 监控技术和工具,用于监控不同方面的 Node.js 应用程序:
-
基础设施监控
-
CPU和内存使用:通过操作系统提供的工具或第三方监控工具,监控 Node.js 应用程序所在服务器的CPU和内存使用情况。这有助于识别资源瓶颈并进行容量规划。
-
网络流量:监控服务器上的网络流量,以了解应用程序的请求和响应情况,并检测潜在的网络问题。
-
-
应用性能监控(APM)
-
响应时间:监控应用程序的请求响应时间,包括客户端到服务器的请求延迟、处理请求的时间和响应返回给客户端的时间。这有助于发现性能瓶颈和优化请求处理。
-
事件循环延迟:监控 Node.js 的事件循环延迟,以了解事件循环队列中待处理事件的数量和延迟。这可以帮助发现事件处理的瓶颈和不良代码实践。
-
内存使用:监控 Node.js 应用程序的内存使用情况,包括堆内存和非堆内存的分配和释放。这有助于检测内存泄漏和优化内存管理。
-
-
错误监控
-
未捕获的异常:监控应用程序中未被捕获的异常,以便及时发现并解决潜在问题。可以使用工具如Sentry、Bugsnag等来捕获和报告错误信息,并提供有关错误发生时的上下文信息。
-
错误率:监控应用程序中的错误率,包括HTTP请求错误、数据库连接错误等。这有助于识别系统的健康状态,并快速响应潜在的故障。
-
-
日志监控
-
记录日志:在应用程序中记录关键事件和错误信息,可以使用 Node.js 内置的
console.log函数或专业的日志库(如Winston、Bunyan等)。适当的日志记录有助于进行故障排查和系统分析。 -
日志聚合和分析:将应用程序产生的日志集中存储到一个中央位置,使用工具如ELK Stack(Elasticsearch、Logstash、Kibana)、Splunk等进行日志的搜索、过滤和分析。这有助于快速定位问题和提供更深入的洞察。
-
-
实时监控
-
实时指标监控:使用工具如Prometheus、StatsD等,收集和展示 Node.js 应用程序的实时指标数据(如CPU利用率、内存使用、请求处理时间等)。这使得开发人员和运维人员可以及时了解应用程序的状态,并对性能问题做出快速响应。
-
可视化仪表板:使用工具如Grafana,创建可视化仪表板,将监控数据以图表和图形的形式展示出来。这有助于更直观地了解应用程序的运行情况和趋势。
-
需要根据具体的需求和场景选择适当的监控技术和工具,并合理设置监控指标和报警规则。通过持续监控和分析 Node.js 应用程序,可以优化应用程序的性能,提高可靠性,减少故障并提供更好的用户体验。
38.1 报警的实现
在 Node.js 应用程序中,监控和报警是确保应用程序稳定性和可靠性的重要环节。当 Node.js 应用程序出现异常或达到预设的阈值时,可以采用以下一些报警方式:
-
邮件报警:通过发送电子邮件通知相关人员。可以使用 Node.js 中的 Nodemailer 库来发送电子邮件报警。你需要配置一个 SMTP 服务器来发送邮件,例如 Gmail、SendGrid 或自己的企业邮件服务器。将报警信息以文本或 HTML 格式发送给指定的收件人。
// 需要安装依赖包:npm install nodemailer // 引入 nodemailer 模块 const nodemailer = require('nodemailer'); // 创建一个 SMTP 连接池 let transporter = nodemailer.createTransport({ host: 'smtp.example.com', // 替换为你的 SMTP 服务器地址 port: 587, // SMTP 服务器端口,一般为 25 或 587 secure: false, // 使用 SSL 或 TLS,一般为 false auth: { user: 'your_username', // 替换为你的邮箱用户名 pass: 'your_password' // 替换为你的邮箱密码 } }); // 设置要发送的邮件内容 let mailOptions = { from: 'sender@example.com', // 发件人邮箱地址 to: 'recipient@example.com', // 收件人邮箱地址 subject: '测试邮件', // 邮件主题 text: '这是一封测试邮件。' // 邮件内容 }; // 使用发送邮件 transporter.sendMail(mailOptions, (error, info) => { if (error) { console.log(error); } else { console.log('邮件已成功发送:' + info.response); } });在上面的示例中,我们首先引入了 nodemailer 模块,然后创建了一个 SMTP 连接池,并设置了发件人信息和邮件内容。最后,调用
sendMail方法发送邮件,并在发送完成后输出相应的信息或错误。请注意,在实际使用时,需要将示例中的 SMTP 服务器地址、发件人邮箱用户名、密码、收件人邮箱地址等信息替换为实际的值。
-
短信报警:通过发送短信消息通知相关人员。你可以使用第三方短信服务提供商(如 Twilio、Nexmo)或自己的短信网关来发送短信报警。这些服务提供API,你可以使用 Node.js 库与其集成,并向指定的手机号码发送报警信息。
-
实时消息报警:通过实时消息平台向团队成员发送报警信息。常见的实时消息平台包括 Slack、Microsoft Teams、Rocket.Chat 等。你可以使用相应平台提供的 API 或 SDK,或者使用第三方库(如 Slack SDK for Node.js)将报警信息发送到特定的频道或用户。
-
呼叫报警:通过电话自动拨号系统向关键团队成员拨打电话进行报警。你可以使用第三方呼叫服务提供商(如 Twilio)或自己的电话系统来实现电话报警。将报警信息转换为语音消息,并通过 API 发起呼叫请求,拨打指定的电话号码。
-
日志记录:将报警信息记录到应用程序的日志文件中。你可以使用 Node.js 中的日志库(如 Winston、Bunyan)将报警信息写入日志文件。然后,你可以使用日志监控和分析工具(如 ELK Stack、Splunk)对日志进行实时监控和分析,以便及时发现异常情况。
具体需要根据你的应用程序需求和团队工作流程选择适合的报警方式。同时,还应考虑报警的灵敏度和重要性,以避免过度报警或忽略关键问题。在配置报警规则时,请设置合理的阈值,并确保相关人员能够及时接收到报警信息。
38.2 稳定性
应用的稳定性是指应用在长时间运行过程中能够保持良好的表现,并能够处理各种异常情况而不崩溃或导致系统故障。以下是提高 Node.js 应用稳定性的一些关键方面:
-
错误处理:合理处理和捕获错误是保证应用稳定性的重要步骤。使用
try-catch块或Promise.catch()来捕获异步操作中的错误,避免未捕获的异常导致应用崩溃。同时,通过适当的日志记录来追踪和分析错误信息,以便进行及时的故障排查。 -
异常处理:除了处理代码中的错误,还需要考虑到应用程序可能遇到的其他异常情况,如网络故障、数据库连接问题等。使用事件监听器(EventEmitter)来处理异常事件,例如处理未捕获的异常、处理未处理的
Promise拒绝等,以确保应用程序能够从异常中恢复并继续正常运行。 -
内存管理:Node.js 应用程序通常会使用 V8 引擎的内存堆来管理对象和数据。正确管理内存是确保应用稳定性的关键因素之一。使用适当的内存管理技术,如避免内存泄漏、及时释放不再使用的对象和资源,可以减少内存占用和避免应用程序由于内存问题而崩溃。
-
资源限制:为了防止应用程序因过多的请求或资源占用而崩溃,可以设置适当的资源限制。例如,设置最大并发连接数、限制每个请求的处理时间、限制内存使用等。这样可以防止应用程序被过载,并保持稳定性。
-
监控和报警:监控应用程序的运行状态和性能指标是确保稳定性的重要手段。通过实时监控 CPU 使用率、内存占用、请求响应时间等指标,可以及时发现异常情况并采取相应措施。配置报警机制,当系统达到预设的阈值时,及时通知相关人员进行响应和故障排查。
-
自动化部署和回滚:使用自动化部署工具和流程,确保新版本的应用程序能够平滑地部署到生产环境中。同时,考虑使用回滚机制,以便在部署过程中出现问题时能够快速回滚到之前的稳定版本,减少影响范围和恢复时间。
-
容错设计:采用容错设计的原则可以提高应用程序的稳定性。例如,实现请求的重试机制、使用负载均衡和故障转移策略、设计健壮的数据存储和缓存策略等。这些措施可以帮助应对网络故障、资源不足和其他异常情况。
通过合理的错误处理、异常处理、内存管理、资源限制、监控报警、自动化部署回滚和容错设计等措施,可以提高 Node.js 应用程序的稳定性,确保应用在长时间运行中能够保持良好的表现。
总结
Node.js 的监控是指对应用程序在运行过程中的各种指标进行实时监测和收集,以便及时发现问题、优化性能,并确保应用程序的稳定运行。监控包括基本指标监控(如CPU利用率、内存占用)、事件监控(如HTTP请求处理时间、错误事件)、日志监控、实时报警、性能分析、容器化监控和服务可用性监控等方面。通过全面监控 Node.js 应用程序,可以及时发现潜在问题、提高应用程序的稳定性和性能,并确保服务对外正常提供。
39-部署和扩展
代码审查一般都是交给工具来完成,在应用代码开发完成以后,一般还会集成单元测试等环境,然后经过一系列的检查测试、审核之后,就可以将代码提交到稳定分支,然后部署上线。
应用程序的部署和扩展是确保应用程序在生产环境中高效运行的重要步骤。下面是关于应用程序部署和扩展的一些建议:
-
选择合适的部署方式
-
自托管服务器:将应用程序部署在自己的服务器上,可以使用工具如Nginx或Apache作为反向代理服务器,使用PM2等进程管理工具来管理 Node.js 进程。
-
云服务提供商:使用云计算平台(如AWS、Azure、Google Cloud等)提供的服务来部署和扩展应用程序,可以通过容器化技术(如Docker)来简化部署流程。
-
服务器无状态架构:将应用程序设计为无状态,使其能够水平扩展,以便在需要时添加更多的服务器节点。
-
-
使用负载均衡
-
在高流量情况下,使用负载均衡来分发请求可以提高应用程序的性能和可靠性。常用的负载均衡解决方案包括Nginx、HAProxy和AWS ELB等。
-
可以使用轮询、IP哈希、最少连接等算法来进行负载均衡,确保请求被均匀地分发到不同的服务器节点上。
-
-
配置监控和日志记录
-
使用监控工具(如Prometheus、Grafana)来监控应用程序的性能指标、错误率等,并及时发现和解决潜在的问题。
-
配置日志记录系统,记录应用程序的日志,以便跟踪和调试错误。
-
-
使用缓存
-
使用缓存技术可以提高应用程序的响应速度和吞吐量。常见的缓存解决方案包括Redis、Memcached等。
-
可以将频繁访问的数据缓存起来,减少与数据库的交互次数。
-
-
异步/非阻塞编程
- 在 Node.js 中,利用异步和非阻塞的特性可以更高效地处理大量并发请求。确保代码按照异步的思维方式编写,避免阻塞操作。
-
自动化部署和持续集成
- 使用自动化工具(如Jenkins、Travis CI等)来进行持续集成和自动化部署,以减少人为错误和提高开发效率。
- 配置自动化流水线,将代码从版本控制系统自动部署到生产环境。
-
使用容器化技术
-
使用容器将应用程序、依赖、配置等打包成独立的镜像,方便部署和运行。
-
常见的容器化技术包括 Docker 和 Kubernetes。
-
-
备份和恢复
-
定期备份数据和配置文件,以防止数据丢失或系统故障。
-
准备好恢复策略和过程,以便在出现问题时能够快速恢复应用程序的正常运行。
-
39.1 将 Node.js 应用部署到生产环境
将 Node.js 应用程序部署到生产环境需要注意一些重要的方面,下面是一个详细的步骤:
39.1.1 选择合适的生产环境
选择一种可靠且稳定的操作系统,如 Ubuntu、CentOS 或云服务器(阿里云、腾讯云等)。
注意:需要配置服务器的安全设置,例如更新操作系统、关闭不必要的端口和服务、配置防火墙等。
39.1.2 安装 Node.js 和 NPM
在服务器或云服务上安装 Node.js 和 NPM,推荐使用 Node.js 的 LTS 版本。
39.1.3 安装依赖和构建项目
先使用 NPM 安装应用程序的依赖,然后再构建项目(如编译 TypeScript 或打包 JavaScript)。
39.1.4 配置环境变量
将应用程序所需的环境变量设置为服务器环境变量或者在应用程序中读取配置文件。
39.1.5 配置反向代理服务器
使用 Nginx 或 Apache 等反向代理服务器来处理静态文件、负载均衡请求等。
要使用 Nginx 作为反向代理服务器来代理 Node.js 应用程序,你可以按照以下步骤进行操作:
-
安装 Nginx:
在你的服务器上安装
Nginx,可以使用包管理工具(如apt、yum或brew)进行安装。 -
配置 Nginx
打开 Nginx 配置文件,通常位于
/etc/nginx/nginx.conf或/etc/nginx/conf.d/default.conf。在
http块内添加一个新的server块,配置代理规则。 -
配置代理规则:
对于每个 Node.js 应用程序,使用
location指令配置代理规则。确保每个 Node.js 应用程序都在不同的端口上正确运行。例如,你可能有一个应用程序运行在3000端口,另一个运行在3001端口,以此类推。例如,以下是一个示例配置,将请求根据路径代理到不同的 Node.js 应用程序:
server { listen 80; server_name yourdomain.com; location /app1/ { proxy_pass http://localhost:3000; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; } location /app2/ { proxy_pass http://localhost:3001; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; } } -
保存配置并重启 Nginx:
保存配置文件,并使用适当的命令重启 Nginx 服务,例如
sudo service nginx restart。 -
测试代理:
确保每个 Node.js 应用程序都在运行,并监听正确的端口。使用浏览器或 cURL 等工具发送请求到你的 Nginx 的 IP 地址或域名,并检查代理是否按预期工作。
通过这样的配置,Nginx 将会根据请求的路径将其代理到不同的 Node.js 应用程序上。你可以根据需求配置更多的 location 块来代理更多的 Node.js 应用程序。Nginx 将会代理请求并将它们转发到 Node.js 服务器上运行的应用程序。请确保你的 Node.js 应用程序正在监听正确的端口,并且服务器上的防火墙允许传入的请求通过所使用的端口。
39.1.6 配置 HTTPS
配置 HTTPS 来确保数据传输的安全性,建议使用 Let’s Encrypt 免费证书。
Nginx 配置 SSL 证书需要在配置文件的 server 块内,添加以下配置来指定 SSL 证书和私钥的文件路径:
server {
listen 443 ssl;
server_name yourdomain.com;
ssl_certificate /path/to/ssl-certificate.crt;
ssl_certificate_key /path/to/private-key.key;
# 可选:如果你的证书包含中间证书,请添加以下配置
# ssl_trusted_certificate /path/to/intermediate-certificate.crt;
# 其他 Nginx 配置...
}
保存修改后的配置文件,并使用适当的命令重新加载 Nginx,例如 sudo service nginx reload。
通过以上步骤,你就成功地在 Nginx 中配置了反向代理,并为多个 Node.js 应用配置了 HTTPS。请确保你的 SSL 证书是有效的,并且你的服务器可以正常处理 HTTPS 请求。如果你需要进一步的配置,也可以根据需求进行调整。
39.1.7 配置监控和日志记录
使用监控工具(如 Prometheus、Grafana)监控应用程序性能指标、错误率等。
配置日志记录系统,记录应用程序的日志,方便跟踪和调试错误。
39.1.8 启动应用程序
使用 PM2 等进程管理工具来管理 Node.js 进程。
安装 PM2
PM2 是一个流行的 Node.js 进程管理工具,用于在生产环境中部署和管理 Node.js 应用程序。它提供了许多有用的功能,例如进程监控、自动重启、负载均衡等。
在服务器上全局安装 PM2,你可以使用 npm 来进行安装:npm install pm2 -g
启动应用程序
使用 PM2 启动你的 Node.js 应用程序,例如:
pm2 start app.js
其中 app.js 是你的 Node.js 应用程序的入口文件。
如果你希望启动多个 Node.js 实例来实现负载均衡和集群扩展,可以通过以下命令指定要启动的实例数量:
pm2 start app.js -i max
上述命令中的 -i max 表示启动与 CPU 核心数相同的实例数量,以充分利用服务器资源。
管理应用程序
PM2(Process Manager 2)是一个流行的 Node.js 进程管理工具,它可以帮助你管理和扩展 Node.js 应用程序。使用 PM2,你可以轻松地启动、停止、监控和自动重启多个 Node.js 进程,并且它还提供了负载均衡、日志管理、故障恢复等功能。
一旦应用程序启动,你可以使用 PM2 管理应用程序的生命周期,比如重新启动、停止、重载等。例如:
- 重新启动应用程序:pm2 restart <app-name|app-id>
- 停止应用程序:pm2 stop <app-name|app-id>
- 重载应用程序:pm2 reload <app-name|app-id>
- 删除应用程序:pm2 delete <app-name|app-id>
其中 <app-name|app-id> 可以是应用程序的名称或 ID。
查看进程列表
使用 pm2 list 命令可以查看当前正在运行的应用程序的进程列表。每个进程都有一个唯一的 ID、名称和状态。
pm2 list
查看进程状态
你可以使用以下命令来查看当前由 PM2 (Process Manager 2)管理的所有进程的状态:
pm2 status
设置开机自启动
如果需要在服务器重启后自动启动应用程序,你可以使用以下命令设置 PM2 开机自启动:
pm2 startup
监控日志
使用 PM2 可以很方便地监控应用程序的日志,例如:
pm2 logs app
PM2 还提供了许多其他有用的功能,如集群模式、负载均衡等,具体可以根据需求进行配置和操作。
使用 PM2 的监控功能来查看各个实例的运行状况,以及负载情况和内存使用情况等:
pm2 monit
负载均衡
PM2 会根据默认的负载均衡算法(Round Robin)将请求分发给不同的 Node.js 实例,从而实现负载均衡。
故障恢复
如果某个实例意外退出,PM2 将会自动重新启动该实例,确保应用程序的稳定运行。
通过使用 PM2,你可以很方便地实现负载均衡和集群扩展,从而提高应用程序的性能和可靠性。
pm2的参数设置
使用 PM2 管理 Node.js 进程时,你可以通过一些参数来配置自动重启、日志记录等功能。以下是一些常用的参数及其用法:
-
设置自动重启等参数
使用
--watch参数可以监视文件变化并自动重启应用程序。例如:pm2 start app.js --watch这将使 PM2 监视
app.js文件的变化,并在文件被修改时自动重启应用程序。 -
设置应用程序名称
使用
--name参数可以为应用程序指定一个名称,方便管理和识别。例如:pm2 start app.js --name myapp这将以
myapp作为应用程序的名称启动应用程序。 -
设置日志输出
使用
--log参数可以将应用程序的日志输出到指定文件中。例如:pm2 start app.js --log /path/to/app.log这将应用程序的日志输出到指定的
/path/to/app.log文件中。 -
设置环境变量
使用
--env参数可以设置应用程序的环境变量。例如:pm2 start app.js --env production这将以
production环境变量启动应用程序。 -
设置监听端口
使用
--port参数可以指定应用程序监听的端口。例如:pm2 start app.js -- --port 3000
除了上述参数外,PM2 还提供了许多其他参数和配置选项,可以根据具体需求进行配置。你可以使用 pm2 start --help 命令查看所有可用的参数和选项。希望这些信息能够帮助你更好地使用 PM2 管理 Node.js 应用程序。
PM2配置文件
PM2 可以帮助你生成一个基本的 ecosystem.config.js 配置文件,以便更轻松地管理和配置你的应用程序。使用以下命令可以生成一个基本的配置文件:
pm2 ecosystem
运行此命令后,PM2 将提示你提供有关应用程序的一些信息,例如应用程序的名称、入口文件路径等。根据提示输入相应的信息后,PM2 将自动生成一个基本的 ecosystem.config.js 文件。
以下是生成的 ecosystem.config.js 文件示例:
module.exports = {
apps: [
{
name: 'myapp',
script: 'app.js',
instances: 1,
autorestart: true,
watch: false,
max_memory_restart: '1G',
env: {
NODE_ENV: 'development'
},
env_production: {
NODE_ENV: 'production'
}
}
]
};
参数说明:
- module.exports:这是一个 CommonJS 模块的导出语句,用于将配置对象导出为
ecosystem.config.js的模块结果。 - apps:这是一个数组,包含了一个或多个应用程序的配置对象。
- name:应用程序的名称,用来标识和区分不同的应用程序。
- script:应用程序的入口文件路径,即启动应用程序的主要脚本。
- watch:一个布尔值,指示是否监视文件变化并自动重启应用程序。当设置为
true时,PM2将监视应用程序相关文件的变化,一旦文件发生变化,PM2 将自动重新启动应用程序。 - env:一个对象,包含应用程序的环境变量。可以在这里定义和设置应用程序所需的环境变量,例如数据库连接信息、API 密钥等。
- env_production:一个对象,定义了生产环境下的环境变量。你可以在这里设置生产环境所需的变量,例如生产数据库连接信息、API密钥等。
- instances:用于指定应用程序的实例数。当设置为大于 1 的值时,PM2 将以集群模式运行应用程序,即会在多个进程中并行地运行应用程序实例。
- exec_mode:用于指定应用程序的执行模式。可以设置为
fork或cluster。fork模式下,每个应用程序实例将在一个独立的进程中运行;cluster模式下,应用程序将以Node.js的集群模式运行,即使用多个子进程共同处理请求。
max_memory_restart:用于指定当应用程序占用的内存超过指定值时,PM2 将自动重启应用程序。可以使用字节数或者带有单位的字符串来指定内存大小。
你可以根据需要在 apps 数组中添加多个应用程序的配置对象。每个配置对象都代表一个应用程序,并可以具有自己的名称、入口文件、环境变量等。
要使用 ecosystem.config.js 文件启动应用程序,请使用以下命令:
pm2 start ecosystem.config.js --cwd /path/to/config
/path/to/config 指的是 ecosystem.config.js 配置文件的存放路径。
使用 ecosystem.config.js 文件作为配置文件,可以更方便地管理和部署多个应用程序,并且还可以添加更复杂的逻辑和自定义设置。
通过以上步骤,你可以使用 PM2 管理你的 Node.js 应用程序,确保应用程序能够稳定运行并且方便地进行监控和管理。
39.1.9 测试应用程序
在生产环境下测试应用程序,确保应用程序正常运行。
可以使用压力测试工具(如 ApacheBench等)来测试应用程序的性能。
39.2 使用容器化技术(如Docker)
将 Node.js 应用程序部署为容器化应用是一种常见的做法,它可以帮助你更轻松地管理应用程序的环境和依赖,并实现快速部署和水平扩展。以下是详细的步骤,讲解如何使用容器化技术部署 Node.js 应用程序:
39.2.1 准备 Dockerfile
在你的 Node.js 项目根目录下创建一个名为 Dockerfile 的文件,其中定义了容器的构建规则和依赖关系。一个简单的示例 Dockerfile 内容如下:
FROM node:latest
WORKDIR /usr/src/app
COPY package*.json ./
RUN npm install
COPY . .
EXPOSE 3000
CMD [ "node", "app.js" ]
以下是对每个指令的说明:
-
FROM node:latest:基于最新的 Node.js 官方镜像构建 Docker 镜像。
-
WORKDIR /usr/src/app:设置容器内的工作目录为
/usr/src/app,即将应用程序代码复制到该位置。 -
COPY package*.json ./:将应用程序的
package.json和package-lock.json文件复制到容器的当前工作目录。 -
RUN npm install:在容器中执行
npm install命令,安装应用程序所需的依赖模块。 -
COPY . .:将当前目录下的所有文件复制到容器的当前工作目录。
-
EXPOSE 3000:指定容器监听的端口号为
3000,允许外部网络访问该端口。 -
CMD [“node”, “app.js”]:在容器中运行
node app.js命令,启动 Node.js 应用程序。
39.2.2 构建 Docker 镜像
在项目根目录下打开终端,执行以下命令来构建 Docker 镜像:
docker build -t my-node-app .
这将根据 Dockerfile 中的定义,构建一个名为 my-node-app 的 Docker 镜像。
.代表将构建好的镜像放到当前目录下。
39.2.3 运行 Docker 容器
在构建完成后,你可以通过以下命令来运行 Docker 容器:
docker run -p 3000:3000 -d my-node-app
这将在后台运行名为 my-node-app 的 Docker 容器,并将容器内部的 3000 端口映射到宿主机的 3000 端口。
39.2.4 访问应用程序
现在,你可以通过浏览器或其他 HTTP 客户端访问 http://localhost:3000 来查看部署的 Node.js 应用程序。
39.2.5 高级特性
你还可以使用 Docker Compose 管理多个容器,并结合容器编排工具如 Kubernetes 实现更复杂的部署和管理。
通过以上步骤,你就可以使用容器化技术将 Node.js 应用程序部署为 Docker 容器。这种方法可以使你的应用程序在不同环境中具有一致的运行方式,并且更容易进行扩展和管理。
39.3 使用负载均衡和集群扩展应用
在 Node.js 中,你可以使用负载均衡和集群扩展来提高应用程序的性能和可靠性。负载均衡可以将流量分发到多个服务器上,以避免单点故障和处理更大的并发请求。而集群扩展则通过在多个服务器上运行相同的应用程序实例来增加应用程序的处理能力和可扩展性。下面是详细介绍如何在 Node.js 中使用负载均衡和集群扩展应用的步骤:
39.3.1 使用负载均衡
要在 Node.js 中实现负载均衡,可以使用以下方法之一:
-
反向代理:使用反向代理服务器(如 Nginx、HAProxy)将流量分发到多个 Node.js 服务器上。反向代理服务器会根据负载情况动态地将请求分发给可用的服务器。
-
Node.js 模块:使用负载均衡模块,例如 cluster 模块或第三方模块 pm2。这些模块允许你在同一台机器上启动多个 Node.js 进程,并使用负载均衡算法将请求分发给不同的进程。
39.3.2 使用集群扩展
要在 Node.js 中实现集群扩展,可以使用以下方法之一:
-
cluster 模块:Node.js 的内置 cluster 模块允许你在同一台机器上创建一个进程集群。每个进程都可以处理请求,并且它们可以共享相同的端口,从而实现负载均衡。
-
第三方模块:使用第三方模块如 pm2 可以更方便地管理和扩展 Node.js 进程。pm2 允许你在多台机器上启动多个 Node.js 进程,并提供监控、负载均衡和故障恢复等功能。
无论你选择哪种方法,都需要确保正确配置负载均衡算法、会话共享、数据同步和错误处理等方面。此外,你还可以考虑使用一些云服务(如 AWS Elastic Load Balancer、Azure Load Balancer),它们提供了高级的负载均衡和自动扩展功能。
通过使用负载均衡和集群扩展,你可以将流量分发到多个服务器上,并实现高可用性、高并发能力和横向扩展。这些方法可以提升你的应用程序的性能和可靠性。
总结
根据应用程序的具体需求和情况,选择适合的扩展策略,可以是纵向扩展(增加服务器的资源,如CPU、内存),也可以是横向扩展(添加更多的服务器节点)。使用负载均衡、容器化技术和自动化工具可以简化扩展过程。